
Fig. 1.
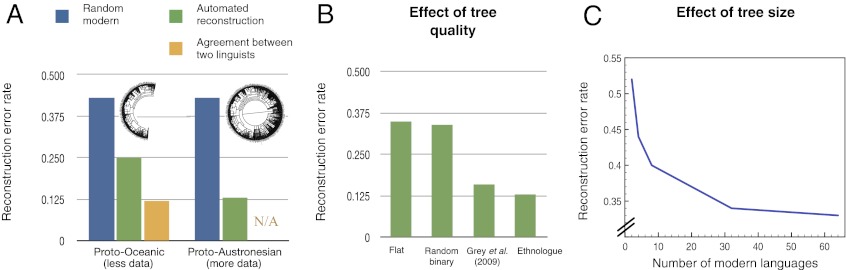
Quantitative validation of reconstructions and identification of some important factors influencing reconstruction quality. (A) Reconstruction error rates for a baseline (which consists of picking one modern word at random), our system, and the amount of disagreement between two linguist’s manual reconstructions. Reconstruction error rates are Levenshtein distances normalized by the mean word form length so that errors can be compared across languages. Agreement between linguists was computed on only Proto-Oceanic because the dataset used lacked multiple reconstructions for other protolanguages. (B) The effect of the topology on the quality of the reconstruction. On one hand, the difference between reconstruction error rates obtained from the system that ran on an uninformed topology (first and second) and rates obtained from the system that ran on an informed topology (third and fourth) is statistically significant. On the other hand, the corresponding difference between a flat tree and a random binary tree is not statistically significant, nor is the difference between using the consensus tree of ref. 41 and the Ethnologue tree (29). This suggests that our method has a certain robustness to moderate topology variations. (C) Reconstruction error rate as a function of the number of languages used to train our automatic reconstruction system. Note that the error is not expected to go down to zero, perfect reconstruction being generally unidentifiable. The results in A and B are directly comparable: In fact, the entry labeled “Ethnologue” in B corresponds to the green Proto-Austronesian entry in A. The results in A and B and those in C are not directly comparable because the evaluation in C is restricted to those cognates with at least one reflex in the smallest evaluation set (to make the curve comparable across the horizontal axis of C).