
Fig. 4.
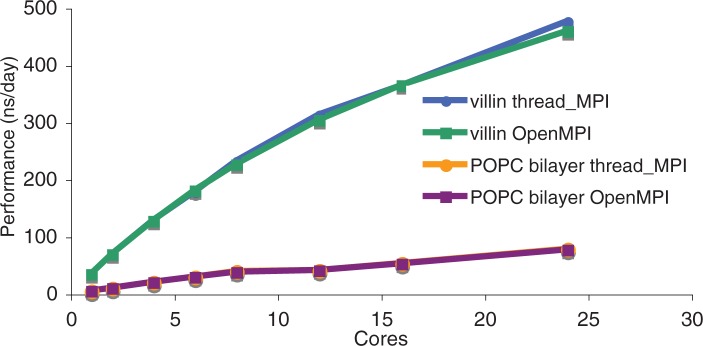
Efficient and portable parallel execution using POSIX or Windows threads. Performance is plotted as a function of number of cores using the thread\_MPI library and compared with using OpenMPI. Simulations were run on a single node with 24 AMD 8425HE cores running at 2.66 GHz. Performance is nearly identical between the two parallel implementations. Data are plotted for the Villin and POPC bilayer benchmark systems