
Figure 2. Critic learning in a linear track task.

A: Learning rule with three factors. Top: TD-LTP is the learning rule given in Eq. 17. It works by passing the presynaptic spike train 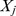 (factor 1) and the postsynaptic spike train
(factor 1) and the postsynaptic spike train 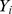 (factor 2) through a coincidence window
(factor 2) through a coincidence window  . Spikes are counted as coincident if the postsynaptic spike occurs within after a few ms of a presynaptic spike. The result of the pre-post coincidence measure is filtered through a
. Spikes are counted as coincident if the postsynaptic spike occurs within after a few ms of a presynaptic spike. The result of the pre-post coincidence measure is filtered through a  kernel, and then multiplied by the TD error
kernel, and then multiplied by the TD error 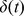 (factor 3) to yield the learning rule which controls the change
(factor 3) to yield the learning rule which controls the change 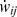 of the synaptic weight. Bottom: TD-STDP is a TD-modulated variant of R-STDP. The main difference with TD-LTP is the presence of a post-before-pre component in the coincidence window. B: Linear track task. The linear track experiment is a simplified version of the standard maze task. The actor's choice is forced to the correct direction with constant velocity (left), while the critic learns to represent value (right). C: Value function learning by the critic. Each colored trace shows the value function represented by the critic neurons activity against time in the
of the synaptic weight. Bottom: TD-STDP is a TD-modulated variant of R-STDP. The main difference with TD-LTP is the presence of a post-before-pre component in the coincidence window. B: Linear track task. The linear track experiment is a simplified version of the standard maze task. The actor's choice is forced to the correct direction with constant velocity (left), while the critic learns to represent value (right). C: Value function learning by the critic. Each colored trace shows the value function represented by the critic neurons activity against time in the  first simulation trials (from dark blue in trial 1 to dark red in trial 20), with
first simulation trials (from dark blue in trial 1 to dark red in trial 20), with 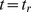 corresponding to the time of the reward delivery. The black line shows an average over trials 30 to 50, after learning converged. The gray dashed line shows the theoretical value function. D: TD signal
corresponding to the time of the reward delivery. The black line shows an average over trials 30 to 50, after learning converged. The gray dashed line shows the theoretical value function. D: TD signal  corresponding to the simulation in C. The gray dashed line shows the reward time course
corresponding to the simulation in C. The gray dashed line shows the reward time course 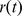 .
.