
Fig. 1.
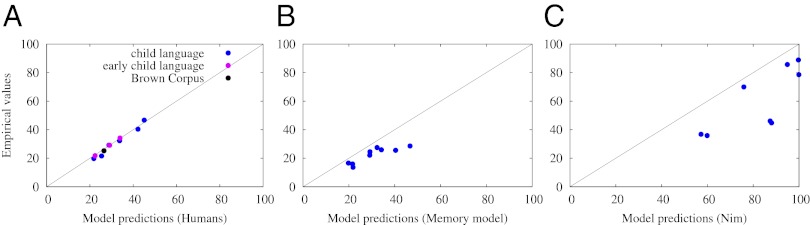
Syntactic diversity in human language (A), memory-based learning model (B), and Nim Chimpsky (C) (details of the data are provided in SI Text). The diagonal line denotes identity; close clustering around it indicates strong agreement. For humans and Nim, the model predictions are made on the assumption that category combinations are independent. For the memory-based learner, the model prediction is based on frequency-dependent storage and retrieval. Only human data are consistent with a productive grammar (ρc = 0.977). Both the memory-based learning model (P < 0.002) and Nim (P < 0.004) show significantly lower diversity than expected under a grammar.