
Figure 3. Distribution of resources for the CUDA kernel that performs the Levenberg-Marquardt algorithm.

Voxels are assigned to threads of CUDA blocks. Each CUDA block is comprised of  threads and processes
threads and processes  voxels (
voxels (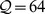 was used in this study).
was used in this study).
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
Voxels are assigned to threads of CUDA blocks. Each CUDA block is comprised of threads and processes voxels ( was used in this study).