
Figure 4. Distribution of resources for the CUDA kernel that performs the MCMC algorithm.

Each voxel is assigned to more than one thread within a thread block, so that the likelihood calculation is parallelised. Each CUDA block is comprised of  threads and processes only 1 voxel (
threads and processes only 1 voxel (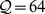 was used in this study).
was used in this study).