

Abstract
Quantitative estimation of T1 is a challenging but important task inherent to many clinical applications. The most commonly used paradigm for estimating T1 in vivo involves performing a sequence of spoiled gradient-recalled echo acquisitions at different flip angles, followed by fitting of an exponential model to the data. Although there has been substantial work comparing different fitting methods, there has been little discussion on how these methods should be applied for data acquired using multichannel receivers. In this note, we demonstrate that the manner in which multichannel data is handled can have a substantial impact on T1 estimation performance and should be considered equally as important as choice of flip angles or fitting strategy.
Keywords: T1 mapping, relaxometry, variable flip angle, non-linear least squares
INTRODUCTION
The relaxation time T1 defines the rate of recovery of longitudinal magnetization of spins in a tissue toward equilibrium after radio frequency excitation. Quantitative knowledge of T1 is useful for many clinical applications, including: (1) optimizing pulse sequences to generate contrast between tissues of interest; (2) estimating perfusion rate constants like Ktrans in dynamic contrast-enhanced MRI (1); (3) monitoring pathology and treatment efficacy (2,3); and (4) guidance for automated image segmentation (4). Although T1-weighted images can be readily acquired, generating accurate quantitative estimates of the T1 values of tissues is not as straightforward. The “gold standard” for T1 mapping is two-dimensional spin echo inversion recovery (5-7); however, this approach is too slow for in vivo clinical applications. Look–Locker techniques (8,9) are faster than IR, but still time consuming and nontrivial to implement. Variable flip angle (VFA) spoiled gradientrecalled echo (SPGR) sequences (10-15) are commonly used for in vivo T1 mapping due to their time and signalto-noise ratio (SNR) efficiency [even when accounting for B1 inhomogeneity (16)], and straightforward implementation. Because of their ubiquity, we focus on the VFA–SPGR approach to T1 mapping in this work.
In the literature, there has been substantial discussion on what numerical fitting strategy to use for estimating T1 from a VFA–SPGR sequence. However, there has been essentially no discussion on how these methods should be applied for data acquired with multichannel receivers. In this work, we investigate several approaches for handling multichannel data during T1 estimation and demonstrate that this seemingly innocuous processing step can substantially impact T1 estimation performance.
THEORY
The VFA–SPGR Signal Model
Consider an MRI experiment where the object of interest is probed using a fully sampled, fully spoiled, Cartesian SPGR sequence with nominal flip angle θ, repetition time TR, echo time, and (relative) transmit radiofrequency field B1, and where the generated MR signal is observed by a Nc-element phased array or multichannel receiver (17). Let Ω denote the (discrete) set of pixels tiling the prescribed field-of-view. Assuming that B1 is (approximately) known a priori, at pixel x ∈ Ω, flip angle index i = 1, …, Ni, and for receiver channel c = 1, …, Nc, the reconstructed discrete image series can be modeled as:
| [1] |
where m0(x) is a complex variable that is proportional to tissue spin density, s(x, c) is the sensitivity function for the cth receiver coil, θ̂(x, i) = θ(i)B1(x) is the effective flip angle and z(x, c, i) is complex Gaussian noise. In this work, noise is assumed to be uncorrelated and have variance .
By fixing TR and applying a different nominal flip angle for each i, T1 can be estimated from the resulting sequence of Ni images. As m0(x) and s(x, c) are individually not of interest here, their product (m(x, c) = m0(x)s(x, c)) can be treated as a single unknown such that there are only Nc + 1 target quantities in Eq. [1] for each x. At least two unique flip angles (preferably three or more) must be used for these quantities to be estimable. For single-channel VFA–SGPR sequences (Nc = 1), one only has to choose which fitting method to use. For multichannel VFA–SGPR sequences (Nc > 1), however, one has the added task of determining how to apply the selected fitting method to the multichannel image sequence. Standard fitting methods may be: (1) applied independently on each channel image sequence, with a final T1 estimate being formed by averaging the set of results; (2) applied on a composite image (e.g., root sum-of-squares) sequence; or (3) generalized such that a single T1 map is jointly estimated using all coil data sets simultaneously.
Generalized T1 Fitting Strategies
Typically, T1 fitting of single-channel data is performed either by approximating and solving Eq. [1] as a linear system or via nonlinear least squares (NLLS) regression. In this section, we generalize these two common approaches for multichannel data. Mirroring the approach of Gupta (10) and Fram et al. (11) for the single-channel problem, if noise is ignored, Eq. [1] can be converted into the following pseudo-linear form:
| [2] |
Although the full complex g(·) could be used in Eq. [2], the magnitude signal is typically used in practice out of convenience and to improve numerical stability. Letting Yx,c and Xx,c be length-Ni vectors defined element-wise as and , respectively, Eq. [2] can be expressed as Yx,c ≈ Xx,cax + 1bx,c, where the slope ax = exp(−TR/T1(x)) and intercepts bx,c = |m(x, c)|[1−ax], and 1 is a length-Ni vector of ones. These variables can be independently estimated at each pixel location x ∈ Ω via ordinary least squares regression, that is,
| [3] |
The (modulated) spin density and T1 parameter estimates are then distilled as m(x, c) = b̂x,c/(1 − âx) and T1(x) = −TR/ln(âx), respectively. Because of its simplicity and fast execution, the linearized approximation paradigm has been widely adopted for estimating T1 from single-channel VFA SPGR sequences. However, in practice, it can exhibit suboptimal performance because: (1) numerical stability is limited as noise is not accounted for (13,18,19); and (2) the estimates of m0 and T1 are inherently biased as the target variables are not wholly decoupled (20).
As noted by Wang et al. (13), a more flexible and robust approach to estimate T1 from VFA–SPGR sequences is via NLLS regression. The NLLS approach treats m0 and T1 as independent quantities and is noise aware, and thus tends to be more stable and exhibits less bias than the pseudo-linear approximation approach discussed above. At each pixel x ∈ Ω, the Nc+1 target variables are directly estimated by solving
| [4] |
where
| [5] |
Solutions to this problem are the maximum likelihood estimators for m0 and T1. Eq. [4] can be solved using standard nonlinear optimization techniques, including: (1) Levenberg–Marquardt iteration (13,21,22); (2) iteratively reweighted least squares regression (20); and (3) variable projection (7,18,23,24).
Variable projection is particularly appealing for problems in which the target cost functional is quadratic with respect to one or more variables, as it reduces the dimensionality of the optimization problem. This has both quantitative and computational advantages. For the problem inherent to Eq. [4], closed-form expressions for the parameters satisfying the optimality condition, ∇m̄(x,·) = 0, can be readily defined, that is:
| [6] |
Embedding these expressions into Eq. [4] yields, independently for each x ∈ Ω, the following:
| [7] |
One-dimensional optimization problems like Eq. [7] can be simply and efficiently solved using derivative-free methods. As a viable range ([α, β]) for the target variable is known a priori, golden section search (GSS) (25) is particularly attractive as its runtime can be predicted based on desired estimate resolution (tol): . For example, T1 can often be assumed to lie between α = 0 ms and β = 10000 ms. If a resolution of tol = 1 ms is deemed sufficient, only maxIter = 20 iterations are required by GSS to perform the estimation. A pictorial example of this fitting procedure is shown in Fig. 1.
FIG. 1.
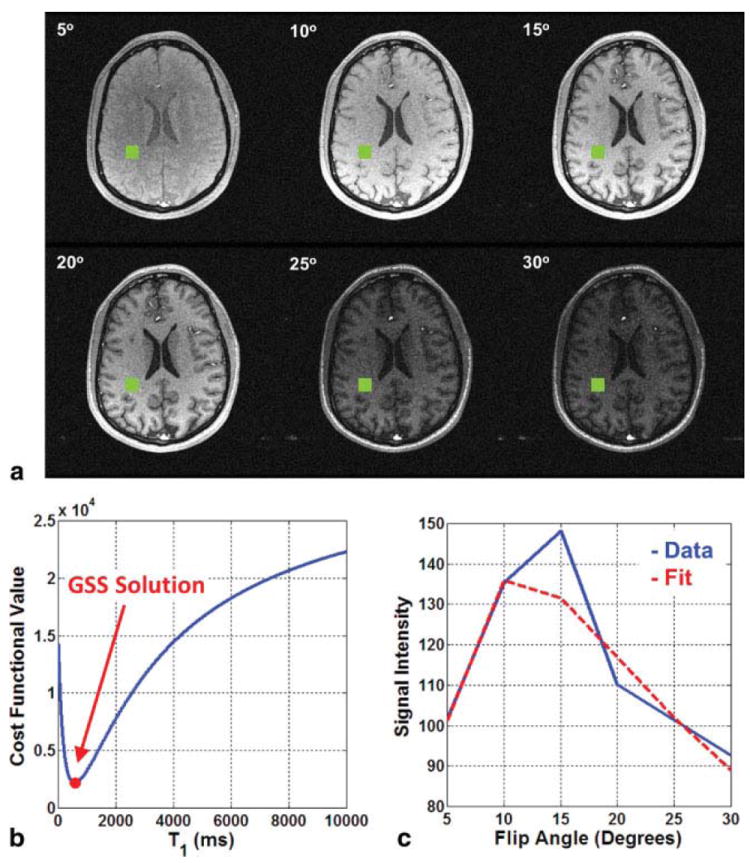
a: The white matter voxel of interest is shown in green on each of the six flip angle images. b: Using the signal from the voxel of interest, the cost functional in Eq. [7] is computed for integer T1 values between 0 and 10000. GSS easily finds the minimum of this unimodal functional. c: Using the T1 value estimated by via GSS, the spin density parameter, m0, is determined and the SPGR signal model in Eq. [1] is (implicitly) fit to the raw data.
Different Ways to Apply a Fitting Strategy to MultiChannel Data
In addition to selecting a fitting strategy (e.g., NLLS), one must also choose how to apply that strategy to multichannel data when estimating T1 from VFA–SPGR sequences. When directly applied to a multichannel data sequence, both fitting strategies described in the last section correspond to so-called joint estimation, as a single T1 estimate is directly generated. Joint estimation via NLLS is the most theoretically appealing approach considered in this work, as it corresponds to the maximum likelihood estimator for T1 in Eq. [1]. It will herein be considered the “gold standard” against which other strategies are compared.
Although attractive, joint estimation can be computationally intensive and so may be impractical in certain clinical situations. Alternatively, multichannel data can be treated as a set of Nc-independent sequences, with a separate fitting being performed on each channel and the Nc results aggregated to yield the final T1 estimate. If the signal is assumed to be “noise-free,” as in linearized approximation, then uniform averaging of the different channel estimates is warranted. However, for noise-corrupted signals, a weighted average (e.g., by the expected SNR of base signal) of the different channel estimation results may yield better performance than simple uniform averaging. Channel-by-channel estimation may exhibit some computational advantage over joint estimation as it eliminates cross-channel computations; however, it is also (relatively) less statistically efficient than joint estimation as the number of effective variables in the estimation problem is increased from Nc + 1 to 2Nc for each pixel, x. Thus, even an “optimally” weighted aggregate of channel-by-channel will typically not outperform joint estimation.
A third strategy is to perform T1 estimation on a sequence of composite images, such as those formed by computing the root-sum-of-squares (RSS) across the channel dimension. This type of strategy is commonly applied in practice albeit often implicitly. As the composite image-based approach reduces the dimensionality of the estimation problem, it is computationally very attractive — Nc times less work is needed than for the channel-by-channel strategy. Noise amplification is also mitigated as estimation is ultimately performed on a high SNR signal. However, as composite images typically contain nonadditive, nonzero mean noise, care must be taken to avoid generating heavily biased estimates. From well-known results on Rician statistics (26),
| [8] |
Eq. [8] suggests the use of the following “debiased” composition strategy in lieu of standard RSS coil image composition:
| [9] |
(27). h can be treated as a single-channel sequence (Nc = 1) and subsequently processed using the fitting strategies described in the last section. Although composite imagebased strategies are not statistically optimal, they may offer practical advantage if their accuracy is comparable to that of joint NLLS estimation.
METHODS
Data Acquisition
Two volunteers were imaged under an IRB-approved protocol on a 1.5-Tesla system (GE Signa v.14.0, Waukesha, WI) using a standard three-dimensional SPGR sequence (TR/echo time = 15/5 ms, field-of-view = 24 cm, 256×256 matrix, BW = ±31.25 kHz, NEX = 1, 28 1 mm axial slices) and an eight-channel receive-only head coil. Raw k-space data were retained for both studies such that the complete (complex) multichannel image sequence was available for processing. Three different flip angles were used during the first volunteer study (2°, 10°, 25°), and six during the second (5°, 10°, 15°, 20°, 25°, 30°). In both cases, prescan parameters determined for the 25° prescription were used for the acquisition sequences for all other flip angles. B1 mapping was not performed, and so the nominal and effective flip angles were assumed to be identical. Coil noise statistics were estimated from a small background region of the images. The total imaging time for the volunteer studies were 4.92 and 9.83 min, respectively. We acknowledge that these scan times are longer than typically used in clinical practice; however, we note that use of acceleration strategies (e.g., partial Fourier, parallel imaging) would also require use of a generalized signal model in lieu of the standard SPGR model in Eq. [1], which is beyond the scope of this study.
Data Processing
All T1 estimation experiments were executed in Matlab (Mathworks, Natick, MA) on a dual six-core (Intel x5670, 2.93 GHz, 12MB cache) machine with 24-GB DDR3 1333 MHz memory. Both the linearized approximation and variable projection-based NLLS fitting strategies described in the Theory section were applied to the multichannel data sequences in the following manner: (1) jointly; (2) channel-by-channel; (3) to an RSS composite image; and (4) to a debiased composite image generated according to Eq. [9]. Correspondingly, eight different T1 estimates were formed for each volunteer study. As discussed in the Theory section, channel-by-channel and joint linearized approximation were performed on magnitude image data, whereas channel-by-channel and joint NLLS fitting was performed directly on the complex image data. Channel-by-channel linearized approximation results were uniformly averaged, corresponding to the “noise-free” signal assumption of the fitting strategy. For consistency, channel-by-channel NLLS results were also aggregated via uniform averaging. The GSS optimization routine used by NLLS was parameterized as α = 0 ms, β = 10000 ms, and tol = 1 ms for all executions.
RESULTS
Figure 2 shows representative T1 maps generated of the mid-level brain for each volunteer by the different fitting strategies. Corroborating previous reports (20), linearized approximation exhibits visible upward bias relative to NLLS in brain tissue (not including cerebrospinal fluid, whose low SNR can actually lead to downward bias). The magnitude of T1 bias also appears to amplify during joint regression, which is undesirable but not unexpected. Noting that bias magnitude exhibits an inverse relationship with SNR (20), we highlight that these trends are especially evident in the results for volunteer #1 (acquired with only three flip angles).
FIG. 2.
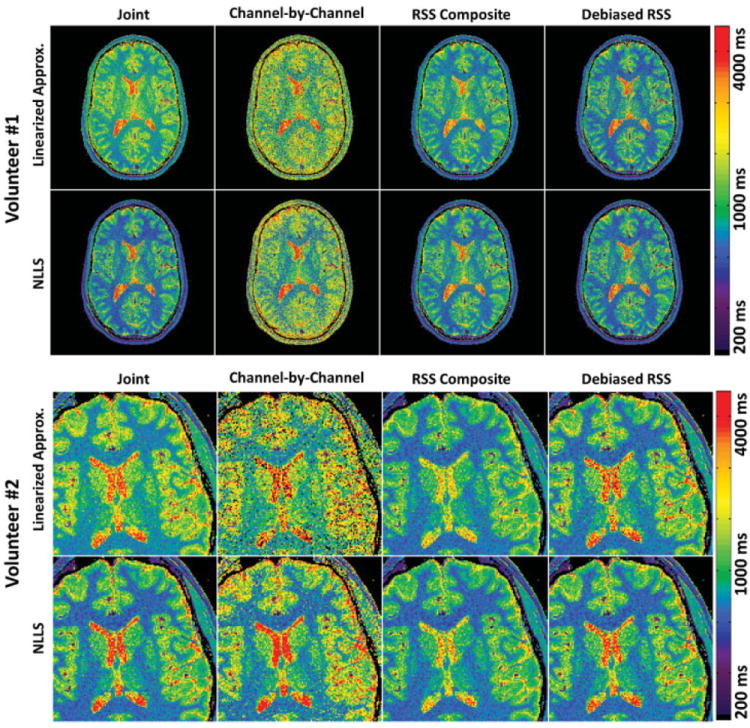
T1 maps generated for Volunteers #1 and #2 using linearized approximation (top rows) and NLLS regression (bottom rows). Each of the four columns represents a different multichannel handling strategy, specifically joint (1st column), channel-by-channel (2nd column), RSS composite based (3rd column), and debiased RSS composite based (4th column) estimation. Joint NLLS estimation is considered the “gold standard.” All maps were windowed and leveled identically.
To quantitatively characterize the observed trends, eight neuroanatomical regions-of-interest (ROIs) were manually identified for each volunteer study for comparative evaluation. The approximate locations of these ROIs are shown in Fig. 3b. For each T1 estimation result for a study, and for every ROI, the median was computed as a robust measure of the central tendency (Table 1). These values are largely consistent with the literature (e.g., (28)). Paired comparisons of brain tissue intra-ROI T1 values were performed between corresponding linearized approximation and NLLS results via the one-sided Wilcoxon sign-rank test (29) (Table 2), under the null hypothesis that, for a particular multichannel handling strategy, linearized approximation estimates smaller T1 values than NLLS. Evidence in Table 2 suggests that this null hypothesis can be rejected (P < 0.05) in the strong majority of cases (22/24 cases for volunteer #1 and 24/24 cases for volunteer #2). Thus, the relative upward bias of linearized approximation for brain tissues (again, not including cerebrospinal fluid) appears to manifest under any multichannel handling strategy albeit with varying degree.
FIG. 3.
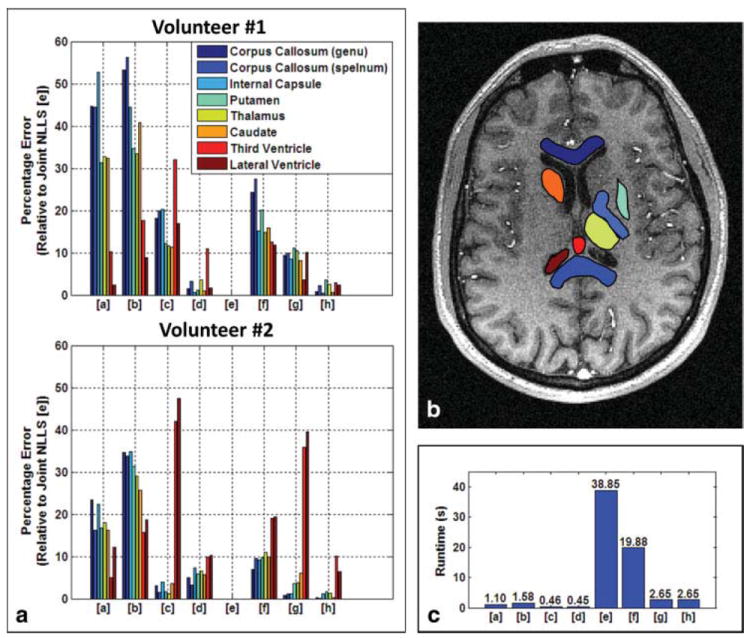
a: Percentage error (relative to joint NLLS) of the various estimation results. For all subfigures, fitting procedures are indexed as linearized approximation [a–d] and NLLS regression [e–h]. Multichannel handling strategies are indexed as joint [a,e], channel-by-channel [b,f], RSS composite based [c,g], and debiased RSS composite based [d,h] estimation. b: Locations of neuroanatomical ROI’s. c: Average runtimes for different fitting and multichannel handling strategies.
Table 1.
Median Observed T1 relaxation Times for Various Neuroanatomical Regions, as Estimated via Linearized Approximation [a–d] and NLLS Regression [e–h].
| [a] | [b] | [c] | [d] | [e] | [f] | [g] | [h] | |
|---|---|---|---|---|---|---|---|---|
| Volunteer #1 | ||||||||
| Corpus callosum (Genu) | 1028 | 1089 | 840 | 722 | 711 | 884 | 778 | 717 |
| Corpus callosum (Splenum) | 1056 | 1142 | 876 | 755 | 731 | 932 | 804 | 747 |
| Internal capsule | 1177 | 1114 | 927 | 776 | 771 | 888 | 837 | 774 |
| Putamen | 1441 | 1477 | 1231 | 1109 | 1097 | 1317 | 1220 | 1136 |
| Thalamus | 1565 | 1574 | 1317 | 1221 | 1179 | 1354 | 1303 | 1210 |
| Caudate | 1576 | 1676 | 1326 | 1203 | 1191 | 1380 | 1289 | 1183 |
| Third ventricle | 4311 | 4596 | 2657 | 4339 | 3908 | 4395 | 3766 | 4021 |
| Lateral ventricle | 4632 | 4933 | 3761 | 4603 | 4528 | 5066 | 4072 | 4421 |
| Volunteer #2 | ||||||||
| Corpus callosum (Genu) | 874 | 953 | 730 | 743 | 708 | 757 | 702 | 710 |
| Corpus callosum (Splenum) | 882 | 1015 | 770 | 784 | 759 | 831 | 751 | 758 |
| Internal capsule | 1003 | 1106 | 852 | 879 | 820 | 895 | 810 | 830 |
| Putamen | 1391 | 1564 | 1172 | 1261 | 1191 | 1307 | 1149 | 1201 |
| Thalamus | 1354 | 1480 | 1134 | 1223 | 1147 | 1273 | 1104 | 1162 |
| Caudate | 1516 | 1640 | 1257 | 1379 | 1305 | 1435 | 1225 | 1302 |
| Third ventricle | 4228 | 3753 | 2583 | 4012 | 4454 | 5301 | 2856 | 4008 |
| Lateral ventricle | 3952 | 3655 | 2362 | 4033 | 4498 | 5369 | 2718 | 4207 |
Each table column corresponds to a different multichannel handling strategy, specifically joint [a,e], coil-by-coil [b,f], RSS composite based [c,g], and debiased RSS composite based [d,h] estimation. All times are in ms.
Table 2.
p-values Generated for Brain Tissue ROIs by One-sided Wilcoxon Sign-Rank Test Under Null Hypothesis that, for a Particular Multi-Channel Handling Strategy, Linearized Approximation Estimates Smaller T1 Values than NLLS.
| Volunteer #1 | JOINT | COIL-BY-COIL | RSS | DEBIASED RSS |
|---|---|---|---|---|
| Corpus Callosum (Genu) | <0.0001 | <0.0001 | <0.0001 | 0.0280 |
| Corpus Callosum (Splenum) | <0.0001 | <0.0001 | <0.0001 | 0.0478 |
| Internal Capsule | <0.0001 | <0.0001 | <0.0001 | 0.0108 |
| Putamen | <0.0001 | <0.0001 | 0.0013 | 0.0303 |
| Thalamus | <0.0001 | <0.0001 | <0.0001 | 0.0182 |
| Caudate | <0.0001 | <0.0001 | 0.1457 | 0.4246 |
| Volunteer #2 | ||||
| Corpus Callosum (Genu) | <0.0001 | <0.0001 | <0.0001 | <0.0001 |
| Corpus Callosum (Splenum) | <0.0001 | <0.0001 | <0.0001 | <0.0001 |
| Internal Capsule | <0.0001 | <0.0001 | <0.0001 | <0.0001 |
| Putamen | <0.0001 | <0.0001 | <0.0001 | <0.0001 |
| Thalamus | <0.0001 | <0.0001 | <0.0001 | <0.0001 |
| Caudate | <0.0001 | <0.0001 | 0.0011 | <0.0001 |
DISCUSSION
In addition to the choice of flip angles and T1 fitting strategy, how multichannel data is handled also appears to have a substantial impact on estimation performance (refer Table 1). For both linearized approximation and NLLS, joint estimation admits markedly better regional homogeneity than its channel-by-channel analog for both volunteers. This trend is not surprising as the former paradigm contains fewer unknown quantities and is thus (relatively) more statistically efficient. As discussed in the Theory section, channel-by-channel performance could potentially be improved using an SNR-weighted rather than uniform averaging to aggregate the results. For linearized approximation, however, using such a strategy would be inconsistent with the assumption that the base signal is inherently “noise-free,” and so was not considered. A preliminary investigation into the use of (expected) SNR-weighted averaging was performed for the channel-by-channel NLLS results; however, the results (not included here) suggested that such a migration, while improving the results somewhat, would not affect the relative rankings of the tested strategies.
Composite image-based methods also outperform their channel-by-channel analog in terms of signal quality, due to their use of higher SNR base signals. There are, however, noticeable differences between the T1 maps generated using standard and debiased RSS composite images, which can be attributed to the methods’ use of base signals with differing noise properties. Low SNR regions of single-channel magnitude MR images are well-known to exhibit positive bias (refer Eq. [8]) due to the asymmetry of the corrupting Rician noise distribution. Standard RSS composite images, which are formed by aggregating a set of magnitude images, inherit this bias. As the presumed MR signal model, Eq. [1], is inversely related to T1, fitting a positively biased signal yields an underestimated T1 value. However, as demonstrated, the degree of this underestimation can be mitigated by instead using a composition procedure that prospectively accounts for this bias. In low-SNR signal regions, the difference in T1 values estimated from a standard and debased RSS composite image can be substantial. For example, for volunteer #1, there was ~16% difference in median T1 value of the anterior corpus callosum (genu) between the standard and debiased RSS linearized approximation results. Similarly, for volunteer #2, there was ~35% difference in median T1 value of the lateral ventricle between the standard and debiased RSS NLLS results. Despite these improvements, we highlight that some discrepancies still exist between the debiased composite image-based estimates and the joint NLLS results, simply because the latter leverages a more comprehensive signal model.
Theoretically, linearized approximation is invariant to the choice of magnitude or complex data as it assumes that the base signal is “noise-free.” Practically, this choice will cause noise to affect fitting performance differently. Although using linearized approximation on complex data may seem benign, this can lead to numerical instabilities when dividing by the logarithm of the slope regression parameter to determine T1. Moreover, during joint linearized approximation, the compounding of phase errors in this processing step can yield substantial bias in the final T1 estimate. Performing linearized approximation on magnitude data mitigates some of these numerical issues, but instead faces the Rician-type bias issues discussed earlier. Nonetheless, preliminary testing suggested that fitting the magnitude signal was more favorable in terms of both numerical stability and performance and, given its general prevalence, was adopted in this work.
Joint NLLS estimation is not only the most statistically attractive approach considered in this work but also the most computationally expensive. Thus, a less expensive paradigm which reasonably mimics joint NLLS performance may be practically advantageous in certain situations. To characterize differences between joint NLLS and the other estimation strategies, absolute relative (i.e., percentage) differences of intra-ROI median values were performed. The results are shown in Figure 3a. Mirroring the visual difference in Figure 2, the strong noise amplification present in the channel-by-channel results makes them not competitive with other strategies. Similarly, joint linearized approximation yields results that are too strongly biased, despite reduced noise compared to the channel-by-channel results. Of the composite image based approaches, NLLS not surprisingly outperforms linearized approximation, and debiased RSS outperforms standard RSS.
Like estimation quality, computational expense also depends on the what T1 estimation paradigm is used. The eight considered estimation approaches were executed 10 times each for both volunteers. The overall average time for each method is shown in Figure 3c. On inspection, two trends immediately emerge. First, linearized approximation is always faster than NLLS. Joint NLLS estimation is clearly the most intensive approach, requiring ~ 35× more effort than its linearized approximation counterpart. At best, composite image-based NLLS estimation is only ~ 6× slower. Second, composite image-based methods are less computationally expensive than methods that directly fit multichannel data. For NLLS, this difference in computational expense is upward of ~ 14×. Thus, if computational expense precludes use of joint NLLS, using NLLS with the debiased composite image as the base signal may be a practical and effective alternative.
CONCLUSIONS
In this note, we have demonstrated that the performance of VFA–SPGR-based T1 estimation strongly depends on how multichannel data is handled during processing, and that this aspect should be considered equally important to the selection of a fitting strategy and the number of used flip angles. Our results corroborate previous observations for single channel acquisition (20) that linearized approximation is biased relative to NLLS for brain tissues and suggest that this trend occurs regardless of which multichannel handling strategy is used. We have also shown that linearized approximation (10,11) can be generalized for joint regression, although improved SNR comes at the expense of amplified bias.
Focusing on NLLS-based strategies, joint regression remains the method of choice for estimating T1 from multi-channel VFA–SPGR data if computational expense is not of concern. Conversely, channel-by-channel strategies are computationally inefficient and poorly performing, and so should not be considered. Composite image-based strategies are computationally attractive; however, care must be taken to mitigate bias that manifests from noise during channel combination. As demonstrated, a strategy which uses NLLS regression and the debiased channel composition strategy proposed in Eq. [9] yields strong categorical emulation of joint NLLS regression albeit in over an order of magnitude less computation time.
The relative performance trends of the methods considered in this work should directly translate for advanced hardware implementations [e.g., GPUs (19)], as well as to variable TR paradigms (18,24) and potentially other quantitative MRI applications where multichannel data handling has historically been a secondary consideration.
Acknowledgments
The authors would like to thank Diane Sauter for her assistance with the imaging experiments.
Grant sponsor: National Institute of Health (Mayo Clinic Center for Advanced Imaging Research); Grant number: RR018898, HL070620, EB000212
References
- 1.Tofts PS. Modeling tracer kinetics in dynamic Gd-DTPA MR imaging. J Magn Reson Imag. 1997;7:91–101. doi: 10.1002/jmri.1880070113. [DOI] [PubMed] [Google Scholar]
- 2.Barbosa S, Blumhardt LD, Roberts N, Lock T, Edwards RH. Magnetic resonance relaxation time mapping in multiple sclerosis: normal appearing white matter and the “invisible” lesion load. Magn Reson Imag. 1994;12:33–42. doi: 10.1016/0730-725x(94)92350-7. [DOI] [PubMed] [Google Scholar]
- 3.Steen RG, Schroeder J. Age-related changes in the pediatric brain: proton T1 in healthy children and in children with sickle cell disease. Magn Reson Imag. 2003;21:9–15. doi: 10.1016/s0730-725x(02)00635-5. [DOI] [PubMed] [Google Scholar]
- 4.Chen PF, Steen RG, Yezzi A, Krim H. Joint brain parametric T1-map segmentation and RF inhomogeneity calibration. Int J Biomed Imag. 2009;269525:1–14. doi: 10.1155/2009/269525. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Drain LE. A direct method of measuring nuclear spin-lattice relaxation times. Proc Phys Soc Lond A. 1949;62:301–306. [Google Scholar]
- 6.Hahn EL. An accurate nuclear magnetic resonance method for measuring spin-lattice relaxation times. Phys Rev. 1949;76:145–146. [Google Scholar]
- 7.Barral JK, Gudmundson E, Stikov N, Etezadi-Amoli M, Stoica P, Nishimura DG. A robust methodology for in vivo T1 mapping. Magn Reson Med. 2010;64:1057–1067. doi: 10.1002/mrm.22497. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Look DC, Locker DR. Time saving in measurement of NMR and EPR relaxation times. Rev Sci Instrum. 1970;41:250–251. [Google Scholar]
- 9.Henderson E, McKinnon G, Lee TY, Rutt BK. A fast 3D Look-Locker method for volumetric T1 mapping. Magn Reson Imag. 1999;17:1163–1171. doi: 10.1016/s0730-725x(99)00025-9. [DOI] [PubMed] [Google Scholar]
- 10.Gupta RK. A new look at the method of variable nutation angle for themeasurement of spin-lattice relaxation time using Fourier transform NMR. J Magn Reson. 1977;25:231–235. [Google Scholar]
- 11.Fram EK, Herfkens RJ, Johnson GA, Glover GH, Karis JP, Shimakawa A, Perkins TG, Pelc NJ. Rapid calculation of T1 using variable flip angle gradient refocused imaging. Magn Reson Imag. 1987;5:201–208. doi: 10.1016/0730-725x(87)90021-x. [DOI] [PubMed] [Google Scholar]
- 12.Haase A, Frahm J, Matthaei D, Hanicke W, Merboldt KD. FLASH imaging: rapid NMR imaging using low flip angle pulses. J Magn Reson. 1986;67:258–266. doi: 10.1016/j.jmr.2011.09.021. [DOI] [PubMed] [Google Scholar]
- 13.Wang HZ, Riederer SJ, Lee JN. Optimizing the precision in T1 relaxation estimation using limited flip angles. Magn Reson Med. 1987;5:399–416. doi: 10.1002/mrm.1910050502. [DOI] [PubMed] [Google Scholar]
- 14.Deoni S, Rutt B, Peters T. Rapid combined T1 and T2 mapping using gradient recalled acquisition in the steady state. Magn Reson Med. 2003;49:515–526. doi: 10.1002/mrm.10407. [DOI] [PubMed] [Google Scholar]
- 15.Deoni S, Peters T, Rutt B. High-resolution T1 and T2 mapping of the brain in a clinically acceptable time with DESPOT1 and DESPOT2. Magn Reson Med. 2005;53:237–241. doi: 10.1002/mrm.20314. [DOI] [PubMed] [Google Scholar]
- 16.Cheng HLM, Wright GA. Rapid high-resolution T(1) mapping by variable flip angles: accurate and precise measurements in the presence of radiofrequency field inhomogeneity. Magn Reson Med. 2006;55:566–574. doi: 10.1002/mrm.20791. [DOI] [PubMed] [Google Scholar]
- 17.Roemer PB, Edelstein WA, Hayes CE, Souza SP, Mueller OM. The NMR phased array. Magn Reson Med. 1990;16:192–225. doi: 10.1002/mrm.1910160203. [DOI] [PubMed] [Google Scholar]
- 18.Haldar JP, Anderson J, Sun SW. Maximum likelihood estimation of T1 relaxation parameters using VARPRO. Proceedings of the 15th Annual Meeting of ISMRM; Berlin, Germany. 2007. p. 41. [Google Scholar]
- 19.Wang D, Shi L, Wang YJ, Yuan J, Yeung DKW, King AD, Ahuja AT, Heng PA. Concatenated and parallel optimization for the estimation of T1 map in FLASH MRI with multiple flip angles. Magn Res Med. 2010;63:1431–1436. doi: 10.1002/mrm.22294. [DOI] [PubMed] [Google Scholar]
- 20.Chang LC, Koay CG, Basser PJ, Pierpaoli C. Linear least-squares method for unbiased estimation of T1 from SPGR signals. Magn Reson Med. 2008;60:496–501. doi: 10.1002/mrm.21669. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Levenberg K. A method for the solution of certain non-linear problems in least squares. Quart Appl Math. 1944;2:164–168. [Google Scholar]
- 22.Marquardt D. An algorithm for least-squares estimation of nonlinear parameters. SIAM J Appl Math. 1963;11:431–41. [Google Scholar]
- 23.Golub GH, Pereyra V. The differentiation of pseudo-inverses and non-linear least squares problems whose variables separate. SIAM J Num Anal. 1973;10:413–432. [Google Scholar]
- 24.Gong J, Hornak JP. A fast T1 algorithm. J Magn Reson Imag. 1992;10:623–626. doi: 10.1016/0730-725x(92)90013-p. [DOI] [PubMed] [Google Scholar]
- 25.Heath MT. Scientific computing. New York: McGraw-Hill; 2002. [Google Scholar]
- 26.Sijbers J, den Dekker AJ, van Audekerke J, Verhoye M, van Dyck D. Estimation of the noise in magnitude MR images. Magn Reson Imag. 1998;16:87–90. doi: 10.1016/s0730-725x(97)00199-9. [DOI] [PubMed] [Google Scholar]
- 27.Manjon JV, Coupe P, Marti-Bonmati L, Collins DL, Robles M. Adaptive non-local means denoising of MR images with spatially varying noise levels. J Magn Reson Imag. 2010;31:192–203. doi: 10.1002/jmri.22003. [DOI] [PubMed] [Google Scholar]
- 28.Stanisz GJ, Odrobina EE, Pun J, Escaravage M, Graham SJ, Bronskill MJ, Henkelman RM. T1, T2 relaxation and magnetization transfer in tissue at 3T. Magn Reson Med. 2005:507–512. doi: 10.1002/mrm.20605. [DOI] [PubMed] [Google Scholar]
- 29.Siegel S. Non-parametric statistics for the behavioral sciences. New York: McGraw-Hill; 1956. [Google Scholar]