
Figure 1.
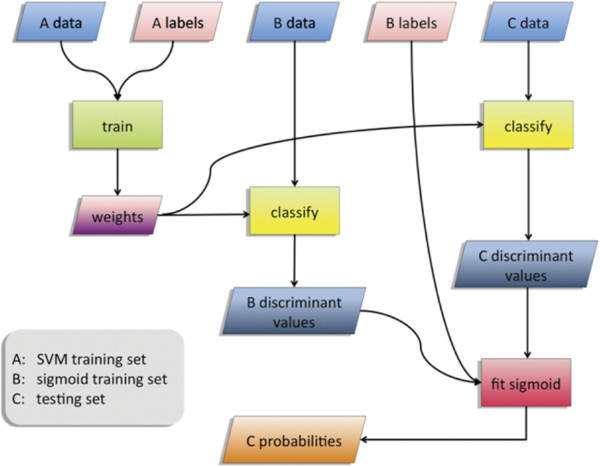
Flowchart Describing the Probability Estimation Procedure using SVM and the Sigmoid Fitting Function. First, SVM is trained using dataset A (SVM training set). Then, classification predictions (in the form of discriminant values) for dataset B (sigmoid training or tuning set) are generated. Those predictions along with the known labels of B are used for the fitting of the sigmoid function. Finally, classification results for dataset C (test set) are mapped to estimated class membership probabilities using the fitted sigmoid.