
Figure 7. Prediction of native language on the basis of electrophysiological and behavioral data.
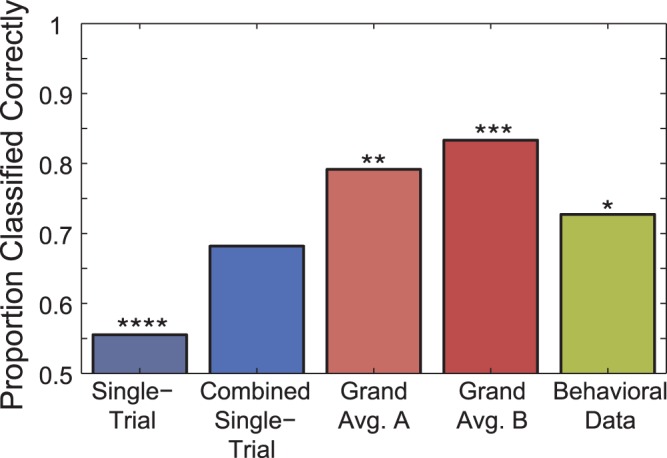
Five decoding analyses aimed at predicting the native-language of a given-participant on the basis of their measured data were carried out. Two analyses made use of concatenated single-trial EEG data from each of the three measurement conditions. The first of these analyses determined single-trial classification rates using this data set, while the second combined the single-trial predictions (70 total trials) for each participant’s data obtained when it was used as a test-set during the classification analysis. Two additional analyses made used of concatenated individual grand-averaged ERPs. One utilized both standard and deviant stimulus ERPs collected in all of the three measurement conditions, while the other included only the deviant ERPs measured using the 63 and 41 ms VOT stimuli. A final analysis was performed using a vector of seven mean behavioral identification scores collected for each participant in the original study by Brandmeyer et al. Significance levels shown using asterisks (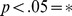 ,
, 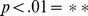 ,
, 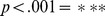 ,
, 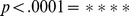 ), and are based on the number of observations available for each of the five data sets. For the single-trial analysis, 1540 data points (70 per participant) were available, while for the remaining four analyses, 22 data points (one per participant) were available.
), and are based on the number of observations available for each of the five data sets. For the single-trial analysis, 1540 data points (70 per participant) were available, while for the remaining four analyses, 22 data points (one per participant) were available.