
Figure 1.
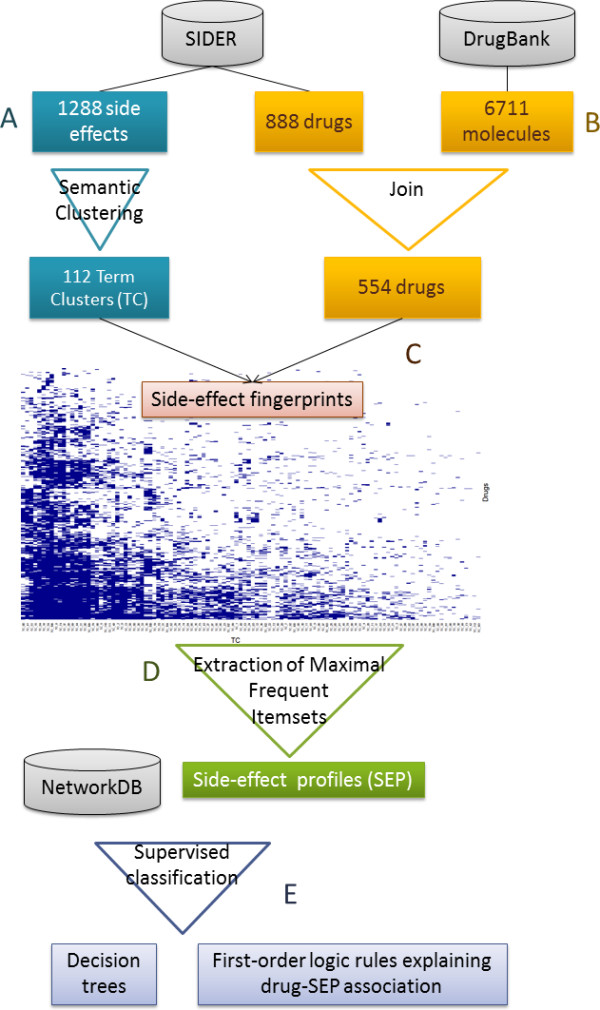
Overview of our approach for characterizing drug-SEP associations. Terms used for describing side effects in SIDER DB are grouped using a semantic similarity measure in order to build Term Clusters or TCs (A). Drugs are mapped to DrugBank in order to retrieve information about drugs themselves and their targets (B). TCs are associated to drugs to represent each drug by a side-effect fingerprint (C). SEPs are extracted as maximal frequent itemsets from side effect fingerprints (D). Two machine-learning methods are used to characterize each SEP in terms of drug and target properties (E).