
Figure 1. Transformation-invariance with the CT learning mechanism.
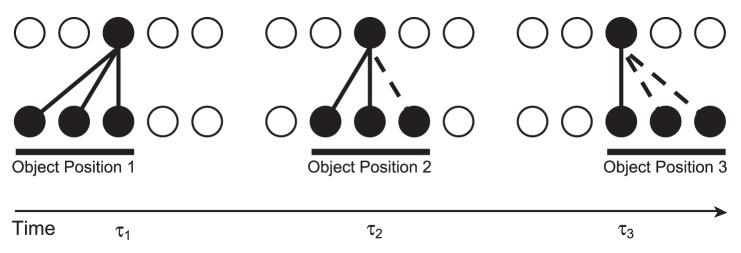
In the initial position at the first transform time ( ) the input neurons randomly activate a set of postsynaptic neurons (due to the random synaptic weight initialisation) and the synaptic connections between the active input and output neurons will be strengthened through Hebbian learning. If the second transform at
) the input neurons randomly activate a set of postsynaptic neurons (due to the random synaptic weight initialisation) and the synaptic connections between the active input and output neurons will be strengthened through Hebbian learning. If the second transform at  is similar enough to the first, the same postsynaptic neurons will be encouraged to fire by some of the same connections potentiated at
is similar enough to the first, the same postsynaptic neurons will be encouraged to fire by some of the same connections potentiated at  and the input neurons of the second transform will have their synapses potentiated onto the same set of output neurons. This process may continue (
and the input neurons of the second transform will have their synapses potentiated onto the same set of output neurons. This process may continue (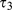 ) until there is very little or no resemblance between the current and the initial transforms. In addition to changes in retinal location, the same principles will apply to build other types of transformation-invariance. For example, changes in view and scale will be accommodated through the same process, provided that there is sufficient overlap of afferent neurons between the transforms.
) until there is very little or no resemblance between the current and the initial transforms. In addition to changes in retinal location, the same principles will apply to build other types of transformation-invariance. For example, changes in view and scale will be accommodated through the same process, provided that there is sufficient overlap of afferent neurons between the transforms.