

Abstract
Multi-task learning (MTL) aims to improve the performance of multiple related tasks by exploiting the intrinsic relationships among them. Recently, multi-task feature learning algorithms have received increasing attention and they have been successfully applied to many applications involving high-dimensional data. However, they assume that all tasks share a common set of features, which is too restrictive and may not hold in real-world applications, since outlier tasks often exist. In this paper, we propose a Robust MultiTask Feature Learning algorithm (rMTFL) which simultaneously captures a common set of features among relevant tasks and identifies outlier tasks. Specifically, we decompose the weight (model) matrix for all tasks into two components. We impose the well-known group Lasso penalty on row groups of the first component for capturing the shared features among relevant tasks. To simultaneously identify the outlier tasks, we impose the same group Lasso penalty but on column groups of the second component. We propose to employ the accelerated gradient descent to efficiently solve the optimization problem in rMTFL, and show that the proposed algorithm is scalable to large-size problems. In addition, we provide a detailed theoretical analysis on the proposed rMTFL formulation. Specifically, we present a theoretical bound to measure how well our proposed rMTFL approximates the true evaluation, and provide bounds to measure the error between the estimated weights of rMTFL and the underlying true weights. Moreover, by assuming that the underlying true weights are above the noise level, we present a sound theoretical result to show how to obtain the underlying true shared features and outlier tasks (sparsity patterns). Empirical studies on both synthetic and real-world data demonstrate that our proposed rMTFL is capable of simultaneously capturing shared features among tasks and identifying outlier tasks.
Keywords: Multi-task learning, feature selection, outlier tasks detection
1. Introduction
Multi-task learning [8] aims to improve the performance of multiple related tasks by utilizing the intrinsic relationships among these tasks. Multi-task learning has been applied successfully in a wide range of applications including object recognition [8], speech recognition [28], handwritten digits recognition [30] and disease progression prediction [44]. A critical ingredient in these applications is how to model the shared structures among tasks. Existing algorithms can be broadly classified into two categories: explicit parameter sharing and implicit structure sharing.
Under explicit parameter sharing, all the tasks explicitly share some common parameters; examples include hidden units in neural networks [8, 5], prior in hierarchical Bayesian models [4, 31, 36, 38], parameters of Gaussian process [18], feature mapping matrix [1], classification weight [11] and similarity metric [28, 40]. On the contrary, algorithms under implicit structure sharing do not explicitly impose all tasks to share certain parameters, but they implicitly capture some common structures; for example, the algorithms in [29, 24] constrain all tasks to share a common low rank subspace and the algorithms in [27, 2, 23, 19, 22, 17, 35, 41] constrain all tasks to share a common set of features.
One key assumption of the above multi-task learning algorithms for both categories is that all tasks are related to each other by the presumed structures. However, this may not hold in real-world applications, as outlier tasks often exist. Thus, simply assuming that all tasks share a certain structure may degrade the performance. This motivates the development of several recent multi-task learning algorithms for discovering the inherent relationship among tasks. For example, some multi-task learning algorithms [32, 34, 14, 42, 16] cluster the given tasks into different groups and impose the tasks in the same groups to share a certain common structure. Multi-task learning algorithms with a composite regularization [15, 9, 10] have been proposed to capture different types of relationships using regularization.
In this paper, we consider the multi-task learning setting where the relevant tasks share a common set of features while outlier tasks exist. We propose a Robust Multi-Task Feature Learning algorithm (rMTFL) which simultaneously captures the shared features among relevant tasks and detects outlier tasks. Specifically, we decompose the weight matrix W consisting of the prediction models of all tasks into the sum of two components P and Q. We employ the well-known group Lasso penalty on row groups of P such that the relevant tasks capture a common set of features. In addition, we employ the same group Lasso penalty but on column groups of Q to simultaneously identify the outlier tasks. The main contributions of this paper include:
We propose a Robust Multi-Task Feature Learning formulation (rMTFL) which simultaneously captures a common set of features among relevant tasks and identifies outlier tasks. We propose to employ accelerated gradient descent to efficiently solve the optimization problem involved in rMTFL, and show that the proposed algorithm is scalable to large-size problems.
We present a theoretical bound to measure how well rMTFL can approximate the underlying true evaluation, and give bounds to measure the error between the weights estimated from rMTFL and the underlying true weights. Moreover, by assuming that the underlying true weights are above the noise level, we present a sound theoretical result to show how we can obtain the underlying true shared features and outlier tasks (sparsity patterns).
We perform empirical studies using both synthetic and real-world data. Our experiments demonstrate the efficiency of the proposed algorithm. Results also demonstrate the effectiveness of rMTFL for capturing shared features among tasks and identifying outlier tasks simultaneously.
Organization
The remainder of this paper is organized as follows: In Section 2, we introduce our proposed rMTFL formulation. In Section 3, we present the proposed optimization algorithm for rMTFL. In Section 4, we provide a detailed theoretical analysis on rMTFL. In Section 5, we discuss related work. Experimental results are presented in Section 6 and we conclude the paper in Section 7.
Notations
Scalars, vectors, matrices and sets are denoted by lower case letters, bold face lower case letters, capital letters and calligraphic capital letters, respectively. xi and xij denote the i-th entry of a vector x and the (i, j)-th entry of a matrix X. xi (xi) denotes the i-th row (column) of a matrix X.
denotes a submatrix composed of the rows of X indexed by
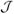 .
and
denote the (j, k)-th entry and the j-th column of a matrix Xi. Euclidean and Frobenius norms are denoted by ‖ · ‖ and ‖ · ‖F. ℓp,q-norm of a matrix X is defined as
and the inner product of X and Y is denoted by 〈X,Y〉. ℕm is defined as the set {1, …, m} and N(μ, σ2) denotes a normal distribution with mean μ and standard deviation σ.
.
and
denote the (j, k)-th entry and the j-th column of a matrix Xi. Euclidean and Frobenius norms are denoted by ‖ · ‖ and ‖ · ‖F. ℓp,q-norm of a matrix X is defined as
and the inner product of X and Y is denoted by 〈X,Y〉. ℕm is defined as the set {1, …, m} and N(μ, σ2) denotes a normal distribution with mean μ and standard deviation σ.
2. The Proposed Formulation
Assume that we are given m learning tasks associated with the training data {(X1, y1),⋯, (Xm,ym)}, where Xi ∈ ℝd × ni is the data matrix of the i-th task with each column as a sample; yi ∈ ℝni is the response of the i-th task (yi has continuous values for regression and discrete values for classification); d is the data dimensionality; ni is the number of samples for the i-th task. The data has been normalized such that the (j, k)-th entry of Xi denoted as satisfies
| (1) |
We consider learning a linear function
for each task and decomposing the weight matrix W = [w1, ⋯, wm] ∈ ℝd × m into the sum of two components P and Q (Please refer to Figure 1 for illustration). We make use of different regularization terms on P and Q to exploit relationships among tasks. Formally, our rMTFL model is formulated as:
Figure 1.

Illustration of weight matrix decomposition for rMTFL, where squares with white background denote zero entries. There are 5 tasks, where the fourth task is an outlier task. Please refer to the text for detailed explanation.
| (2) |
where the first regularization term on P captures the shared features among tasks and the second term on Q discovers the outlier tasks; λ1 and λ2 are nonnegative parameters to control these two terms. Specifically, the first regularization term is based on the well-known group Lasso penalty on row groups of P which restricts the rows of the optimal solution P* to consist of all zero or nonzero elements [2]. Thus, all related tasks should select a common set of features. However, the assumption that all tasks share the same set of features may not hold in real applications, as outlier tasks often exist. To address this issue, we introduce the second regularization term based on the same group Lasso penalty but on column groups of Q to discover these outlier tasks. Similarly, the columns of the optimal solution Q* consist of all zero or nonzero elements, with the nonzero columns corresponding to outlier tasks. Intuitively, if the i-th column of Q* is nonzero, then the i-th column of W* is also nonzero, thus the i-th task does not share a common set of features with other tasks, identified as an outlier task; meanwhile, for the remaining tasks corresponding to the zero columns of Q*, they share a common set of features captured by the nonzero rows of P* (see Figure 1).
3. Optimization Algorithm
In this section, we show how to solve the rMTFL formulation in Eq. (2) efficiently. Denote
| (3) |
where l(P, Q) is the empirical loss function and r(P, Q) is the regularization term. We note that the objective function in Eq. (2) is a composite function of a differential term l(P, Q) and a non-differential term r(P, Q). Denote
| (4) |
which is the first order Taylor expansion of l(P, Q) at (R, S), with the squared Euclidean distance between (P, Q) and (R, S) as the regularization term. The traditional gradient descent algorithm obtains the solution at the k-th iteration (k ≥ 1) by (Pk, Qk) = arg minP,Q TPk–1, Qk–1,ηk (P,Q) + r(P, Q) with a proper step size ηk. Here we propose to employ the accelerated gradient descent [25, 26] to solve the optimization problem, which generates the solution at the k-th iteration (k ≥ 1) by computing the following proximal operator [20, 19, 21, 12, 37, 3]:
| (5) |
where R1 = P0,S1 = Q0 and Rk+1 = Pk + αk(Pk − Pk – 1), Sk + 1 = Qk + αk(Qk − Qk–1) for k ≥ 1; ηk (k ≥ 1) is set by finding the smallest nonnegative integer mk such that with ηk = 2mk ηk–1:
| (6) |
We note that (Rk+1,Sk +1) is in fact a linear combination of (Pk,Qk) and (Pk –1,Qk –1). The coefficient αk plays an important role in the convergence of the algorithm. As suggested by [6], we set αk = (tk–1 − 1)/tk, where t0 = 1 and for k ≥ 1. According to the theoretical analysis in [6], we present the following convergence result for rMTFL:
Theorem 1. Let (Pk, Qk) be generated by Eq. (5) with a properly chosen ηk satisfying Eq. (6). Then for any k ≥ 1,
| (7) |
where f(·, ·) and (P*,Q*) are respectively the objective function and the optimal solution in Eq. (2).
3.1 Implementation details
There are two issues that remain to be addressed: how to compute the proximal operator in Eq. (5) and how to select a proper initial value η0.
Due to the decomposable property of Eq. (5), we can cast Eq. (5) into the following two separate proximal operator problems:
where ∇Rl(Rk,Sk) and ∇Sl(Rk,Sk) are the partial derivatives of l(R,S) with respect to S and R at (Rk,Sk). The above proximal operator problems admit closed form solutions with time complexity of O(dm)[19]:
where and denote the i-th row of Uk and the j-th column of Vk, respectively.
An appropriate choice for η0 is the Lipschitz constant L of the gradient of l(P,Q). However, the Lipschitz constant L is unknown and calculating it is computationally expensive. Next, we show how to estimate its lower and upper bounds. Denote by a block diagonal matrix with as the i-th block. Then the Lipschitz constant L is just the squared maximum singular value of D. According to matrix norm properties [13], we can bound L as follows:
| (8) |
We note that D is a block diagonal matrix and it is sparse when m (the number of tasks) is large, which makes the bounds of L very tight. If we set η0 as the upper bound of L, then we do not need line search, because when ηk ≥ L, Eq. (6) is always satisfied [6]. Otherwise, line search is necessary. Although setting η0 as the upper bound of L can eliminate line search, it may increase the outer iterative steps. On the contrary, it leads to a smaller outer iterative steps by setting η0 as the lower bound of L. In our experiments, we use the lower bound of L to initialize η.
4. Theoretical Analysis
4.1 Basic Assumption
We assume that the responses are given by a linear model plus Gaussian noise1, i.e.,
| (9) |
where W* is the true weight matrix decomposed as the sum of two underlying true components P* and Q*:
| (10) |
| (11) |
are respectively the training data and responses of the i-th task;
| (12) |
| (13) |
are the i.i.d. normal noise and the true evaluation, respectively. Thus, we have
| (14) |
We also define
| (15) |
as the index sets for the nonzero and zero rows of P.
4.2 Theoretical Bounds
The following theorem provides a key property of the optimal solution of Eq. (2), which is critical for our subsequent theoretical analysis:
Theorem 2. Let (P̂, Q̂) be an optimal solution of Eq. (2) for m ≥ 2 and n, d ≥ 1. Let Xi and yi be defined in Eq. (11); let δi and be defined in Eq. (12) and Eq. (13), respectively. We assume that the data is normalized as in Eq. (1). Choose the regularization parameters λ1 and λ2 as
| (16) |
where t is a positive scalar. Then with probability of at least , for any P,Q ∈ ℝd × m, we have
| (17) |
Based on Theorem 2, we present some performance bounds of our rMTFL model in Eq. (2). We first introduce some notations to unclutter the equations. Let X ∈ ℝdm × mn be a block diagonal matrix with Xi ∈ ℝd × n (i ∈ ℕm) as the i-th block. Define a vectorization operator ‘vec’ over an arbitrary matrix A ∈ ℝd × m such that . Then, Eq. (17) can be rewritten as
| (18) |
where . Next, we make the following assumption about the training data and the weight matrix, which generalizes the restricted eigenvalue assumption in [7].
Assumption 1. For a matrix pair ΓP ∈ ℝd × m and ΓQ ∈ ℝd × m, let r and c (1 ≤ r ≤ d, 1 ≤ c ≤ m) be the upper bounds of |
(P*)| and |
(Q*T)|, respectively, and let β1 and β2 be positive scalars. We assume that there exist positive scalars κ1(r) and κ2(c) such that
| (19) |
| (20) |
where the set
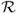 (r, c) is defined as
(r, c) is defined as
(·) is defined in Eq. (15) and |
| denotes the number of elements in the set
.
Note that Assumption 1 is related to the restricted eigenvalue assumption which is a critical condition in [7]. Some previous studies on multi-task learning [22, 10] also make use of similar assumptions. Our main theoretical result is summarized in the following theorem for performance bounds.
Theorem 3. Let (P̂, Q̂) be an optimal solution of Eq. (2) for m ≥ 2 and n, d ≥ 1 and take the regularization parameters λ1 and λ2 as in Eq. (16). Then under Assumption 1, the following results hold with probability of at least :
| (21) |
| (22) |
| (23) |
If in addition, the following conditions hold:
| (24) |
| (25) |
then with the same probability, the following two sets
| (26) |
| (27) |
estimate the true sparsity pattern
(P*) and
(Q*T), respectively. That is,
| (28) |
| (29) |
Theorem 3 provides important theoretical guarantee for rMTFL. Specifically, these bounds not only measure how well our rMTFL model can approximate the true evaluation values defined in Eq. (9) [Eq. (21)], but also measure how well our rMTFL model can approximate the true weight matrices (P*,Q*,W* = P* + Q*) [Eq. (22) and Eq. (23)]. Moreover, under the assumption that the underlying true weights are above the noise level [Eq. (24) and Eq. (24)], we can also estimate the true sparsity patterns (i.e.,
(P*),
(Q*T)) with high probability [Eq. (26) and Eq. (27)].
5. Related Work
Previous studies in [15, 9, 10] also decompose the weight matrix into two components; rMTFL differs from these work in several aspects:
rMTFL employs different regularization terms from the algorithms in [15, 9, 10]. The regularization terms in rMTFL not only have intuitive explanations for feature selection and outlier tasks detection (see Figure 1 and detailed explanation in Section 2), but also have sound theoretical guarantee (see Section 4).
rMTFL has the mechanism of detecting outlier tasks, unlike the algorithms in [15, 9]. Although the algorithm in [10] has the ability to detect the outlier, it focuses on capturing the low rank structure among tasks, while rMTFL has advantages on high dimensional multi-task feature learning problems. Specifically, in terms of the evaluation performance, the main difference between our Theorem 2 and Lemma 4.3 in [10] is that the bound of rMTFL is based on , while the bound of RMTL in [10] is based on ║Q(L̂ − L)║tr. In practical multi-task learning problems, the dimensionality is often high and the underlying selected features are few, that is, the number of elements in
(P) can be small, which indicates that
is small, leading to a tight bound in Theorem 2. However, in the scenario of a large number of tasks, the relevant tasks may share a low rank subspace, resulting in a small value of ║Q(L̂ −L)║tr. Therefore, rMTFL has an advantage of identifying a few shared features for high dimensional data, while RMTL in [10] focuses on discovering low rank subspace among a large number of tasks. Our experimental results in Section 6.4 demonstrate that rMTFL outperforms RMTL in the high dimensional scenario, and RMTL is preferred when the number of tasks is large but the dimensionality is low.Unlike the analysis in [10], we provide theoretical bounds to measure the error between the estimated weights of rMTFL and the underlying true weights. Moreover, we have theoretically shown under what conditions we can obtain the underlying true shared features and outlier tasks (sparsity patterns). In addition, both Theorem 2 and Theorem 3 work with probability of at least which is higher than presented in Lemma 4.3 and Theorem 4.1 of [10].
Each step of the optimization method in [10] involves SVD operation with a time complexity of O(min(d2m, m2d)), thus it does not scale to large-size problems (e.g., the number of tasks and the dimensionality are large). As we show in Section 3.1, the optimization method of rMTFL has a much lower time complexity of O(dm) and hence can be applied to large-size problems.
6. Experiments
6.1 Competing Algorithms and Data Sets
Competing Algorithms
We compare our rMTFL algorithm on multi-task regression problems with seven representative algorithms: ridge multi-task regression (ridge), ℓ1-norm multi-task regression (lasso), trace-norm multi-task regression (trace), ℓ1,2-norm multi-task regression (L1,2), dirty model multi-task regression (DirtyMTL) [15], sparse structures and low rank multi-task regression (SLR) [9] and robust multi-task regression (RMTL) [10]. All eight algorithms employ a quadratic loss function. Matlab codes of the rMTFL algorithm are available online [43].
Synthetic data
The synthetic data is generated as follows: we set the number of tasks m = 30 and each task has ni = 200 samples in d = 200 dimension; each entry of the data matrix Xi ∈ ℝd × ni(i ∈ ℕm) is sampled from the distribution N(0,25) and it is normalized such that Eq. (1) is satisfied; each entry of the ground truth weight matrices P ∈ ℝd × m and Q ∈ ℝd × m is generated from the distribution N(0,64); we set the first 160 rows of P and the first 20 columns of Q as zero vectors; the elements of the noise vector δi ∈ ℝni(i ∈ Nm) are sampled from the distribution N(0,1); the response yi ∈ ℝni(i ∈ ℕm) is computed via . Under this setting, we have constructed 20 related tasks and 10 outlier tasks.
Real-world Data
We adopt two data sets for our multitask regression evaluation: School data2 and MRI data.
The School data set is from the Inner London Education Authority (ILEA), consisting of examination records of 15362 students (samples) from 139 secondary schools in years 1985, 1986 and 1987. Each sample is represented by 27 binary attributes which include year, gender, examination score, etc., plus 1 bias attribute (In our experiments, the bias attribute is not used). The response (target) is the examination score. So we have 139 tasks with each task corresponding to one school.
The MRI data set is from the ANDI database. It contains MRI data of 675 patients preprocessed using FreeSurfer3. The MRI data include 306 features which can be categorized into 5 types: cortical thickness average, cortical thickness standard deviation, volume of cortical parcellation, volume of white matter parcellation, and surface area. The response (target) is the Mini Mental State Examination (MMSE) score coming from 6 different time points: M06, M12, M18, M24, M36, and M48. We remove the samples which fail the MRI quality controls and with missing entries. After the preprocessing above, we have 6 tasks with each task corresponding to a time point and the sample sizes corresponding to 6 tasks are 648, 642, 293, 569, 389 and 87, respectively.
6.2 Experimental Setting
In our experiments, we terminate all the algorithms when the relative change of the two consecutive objective function values is less than 10−5. We randomly split the samples (both synthetic and real-world data sets) from each task into training and test samples with different training ratios. We evaluate eight multi-task regression algorithms on the test data set, using normalized mean squared error (nMSE) and averaged means squared error (aMSE) as the regression performance measures [39, 10, 42]. For each training ratio, both nMSE and aMSE are averaged over 10 random splittings of training and test sets. All parameters of the eight algorithms are tuned via 3-fold cross validation.
6.3 Synthetic Data Experiments
We set the training ratio of synthetic data generated in Section 6.1 as 20% and 30%, respectively. Experimental results (averaged nMSE and aMSE) are shown in Figure 2. We observe that rMTFL outperforms all the other competing algorithms, which demonstrates the effectiveness of rMTFL for high dimensional problems with outlier tasks.
Figure 2.

Averaged test error (nMSE and aMSE) vs. training ratio for synthetic data.
6.3.1 Illustration of Outlier Tasks Detection
Next, we further demonstrate the outlier tasks detection capability of rMTFL. We firstly generate another synthetic data set following the same procedure in Section 6.1, except that each task has ni = 20 samples. Then, we set and run rMTFL on this synthetic data until the relative change of the two consecutive objective function values is less than 10−5. Figure 3 shows the results of P and Q obtained by rMTFL. Specifically, there are 164 zero rows in P and 21 zero columns in Q. These results demonstrate the capability of rMTFL in simultaneously capturing the shared features among tasks (the nonzero rows of P) and discovering outlier tasks (the nonzero columns of Q).
Figure 3.

Figures of P, Q and W = P + Q generated from rMTFL on the synthetic data. Black points correspond to zero entries. Note that the figures are clockwise rotated 90 degrees.
6.3.2 Scalability Studies on rMTFL
We conduct scalability studies on two algorithms which are capable of identifying outlier tasks: rMTFL and RMTL [10], when the dimension and the number of tasks increase. We firstly fix m = 20 and let the dimension d increase as {50i},i = 0,⋯,5. Then we run rMTFL and RMTL on the synthetic data generated following the same procedure in Section 6.1. The computational time (CPU time) vs. dimension plot is shown in the left subfigure of Figure 4. Similarly, we fix d = 100 and let the number of tasks m increase as {10i},i = 0, ⋯, 5. Then we run rMTFL and RMTL and show the computational time (CPU time) vs. the number of tasks plot as in the right subfigure of Figure 4. We observe that, the CPU time of both rMTFL and RMTL increases when the dimension d (or the number of tasks m) increases. However, the CPU time of RMTL increases significantly faster than rMTFL. Because the SVD computation with a time complexity of O(min(d2m,m2d)) involved at each step of RMTL is computationally much more expensive than the computation of the ℓ1,2-norm proximal operator with a time complexity of O(dm) involved at each step of rMTFL. This demonstrates the superior scalability of rMTFL over RMTL.
Figure 4.

CPU time vs. dimension (left) and number of tasks (right) plots for rMTFL and RMTL. The CPU time is averaged over 10 independent runs.
6.4 Real-world Data Experiments
For the School data set, we respectively set the training ratio as 16%, 24%, 32%, and for the MRI data set, we respectively set the training ratio as 15%,20%,25%. Table 1 and Table 2 show the experimental results in terms of averaged nMSE and aMSE.
Table 1.
Comparison of eight multi-task regression algorithms on the MRI data set in terms of averaged nMSE and aMSE.
| measure | traning ratio | ridge | lasso | trace | L1,2 | DirtyMTL | SLR | RMTL | rMTFL |
|---|---|---|---|---|---|---|---|---|---|
| nMSE | 0.15 | 0.9494 | 0.6469 | 0.6889 | 0.6445 | 0.6355 | 0.6905 | 0.6930 | 0.5743 |
| 0.20 | 0.9355 | 0.6242 | 0.6629 | 0.6555 | 0.6231 | 0.6648 | 0.6557 | 0.5700 | |
| 0.25 | 0.9151 | 0.6015 | 0.6230 | 0.6446 | 0.6082 | 0.6244 | 0.6239 | 0.5498 | |
|
| |||||||||
| aMSE | 0.15 | 0.0270 | 0.0188 | 0.0195 | 0.0184 | 0.0177 | 0.0196 | 0.0196 | 0.0168 |
| 0.20 | 0.0262 | 0.0177 | 0.0184 | 0.0184 | 0.0172 | 0.0185 | 0.0182 | 0.0163 | |
| 0.25 | 0.0255 | 0.0170 | 0.0171 | 0.0181 | 0.0167 | 0.0171 | 0.0171 | 0.0157 | |
Table 2.
Comparison of eight multi-task regression algorithms on the School data set in terms of averaged nMSE and aMSE.
| measure | traning ratio | ridge | lasso | trace | L1,2 | DirtyMTL | SLR | RMTL | rMTFL |
|---|---|---|---|---|---|---|---|---|---|
| nMSE | 0.16 | 1.2325 | 1.0457 | 0.7829 | 0.9236 | 0.8989 | 0.7812 | 0.7804 | 0.8628 |
| 0.24 | 1.0734 | 0.9441 | 0.7606 | 0.9017 | 0.8413 | 0.7608 | 0.7613 | 0.8173 | |
| 0.32 | 0.9996 | 0.8875 | 0.7506 | 0.8972 | 0.8019 | 0.7507 | 0.7504 | 0.7874 | |
|
| |||||||||
| aMSE | 0.16 | 0.3154 | 0.2735 | 0.2048 | 0.2395 | 0.2358 | 0.2044 | 0.2041 | 0.2252 |
| 0.24 | 0.2773 | 0.2469 | 0.1993 | 0.2341 | 0.2203 | 0.1993 | 0.1995 | 0.2135 | |
| 0.32 | 0.2580 | 0.2312 | 0.1958 | 0.2316 | 0.2088 | 0.1958 | 0.1958 | 0.2049 | |
From these results, we have the following observations: (1) rMTFL outperforms all the other algorithms on the MRI data set. This may be due to the fact that for the MRI data set, the dimension (d = 306) is high especially when compared with the number of tasks (m = 6). (2) For the School data set, the multi-task learning algorithms based on trace norm (low rank) regularization (trace, SLR, RMTL) outperform the multi-task learning algorithms based on ℓ1,q-norm (feature selection) regularization (lasso, L1,2, DirtyMTL, rMTFL). This may be due to the fact that the number of tasks (m = 139) of the School data set is larger compared with dimension (d = 27). In this case, restricting all tasks to share a low rank subspace is more reasonable than restricting all tasks to share a few common features. (3) On both data sets, the performance of rMTFL is the best among the feature selection based multi-task learning algorithms (lasso, L1,2, DirtyMTL, rMTFL). This may be due to rMTFL's capability of simultaneously discovering the shared features and identifying outlier tasks.
6.4.1 Outlier Tasks Detection
The proposed rMTFL algorithm is capable of capturing the shared features among tasks and detecting outlier tasks. We next evaluate the outlier tasks detection performance on the MRI data set. Firstly, we run rMTFL on the whole MRI data set and observe that the fourth task is identified as an outlier task. Then, we remove the fourth task, obtaining a new multi-task regression problem with the remaining 5 tasks. Finally, we run ℓ1,2-norm multi-task regression on this ‘clean’ multi-task regression problem. We call this two-stage procedure as 2S-rMTFL. The test errors (nMSE and aMSE) on the MRI data set are shown in Figure 5. We can clearly see that after removing the outlier tasks, 2S-rMTFL outperforms L1,2 and rMTFL, which demonstrates the effectiveness of rMTFL in detecting outlier tasks.
Figure 5.

Test errors (nMSE and aMSE) on the MRI data set. See the texts for more details.
7. Conclusions
In this paper, we propose a Robust Multi-Task Feature Learning algorithm (rMTFL) to simultaneously capture the shared features among multiple related tasks and detect outlier tasks. We analyze the theoretical properties of rMTFL. Our analysis shows how well rMTFL can approximate the true evaluation, and measure how well rMTFL can approximate the underlying true weights. Moreover, we show that rMTFL can obtain the true sparsity patterns if the underlying true weights are above the noise level. In addition, the optimization problem involved in rMTFL can be solved efficiently, and rMTFL scales to large-size problems. In the future work, we will extend our rMTFL algorithm to multitask learning problems with general loss functions and apply rMTFL to other real-world applications.
Acknowledgments
This work is supported in part by NSFC (Grant No. 60835002, 61075004 and 91120301), NIH (R01 LM010730) and NSF (IIS-0953662, CCF-1025177).
Appendix
To prove the theorems presented in Section 4.2, we first provide some basic lemmas and then give the detailed proof.
Lemma 1. For any matrix pair P,P̂ ∈ ℝd × m, we have the following inequality:
| (30) |
Proof. According to Eq. (15),we have
It follows that
| (31) |
We note that . Substituting Eq. (31) into Eq. (30), we verify Lemma 1.
Lemma 2. Let δi be I.I.D. random variables with δi ∼ N(0,σ2), i ∈ ℕn and . Then we have
is a standard normal random variable, i.e., υ ∼ N(0,1).
Proof. Since δi are I.I.D. random variables with δi ∼ N(0, σ2), i∈ ℕn, υ must be a normal random variable. Next, we need to show that the mean (E) and variance (V) of υ are respectively 0 and 1, as given below:
Lemma 3. Let χ2(d) be a chi-squared random variable with d degrees of freedom. Then, the following holds:
Proof. By the Wallace inequality [33], we obtain
| (32) |
where N is a standard normal random variable and . Lemma 3 follows directly from Eq. (32) and inequality .
Proof of Theorem 2
Proof. Since (P̂, Q̂) is an optimal solution of Eq. (2), the following holds for any P and Q:
Substituting Eq. (14) into the above inequality, we have
| (33) |
where Z = [X1δ1, ⋯,Xmδm] ∈ ℝd × m with its (j,i)-th entry given by
| (34) |
and denotes the (j, k)-th entry of data matrix Xi for the i-th task. It follows from Eq. (1) that
| (35) |
are i.i.d. standard normal random variables (see Lemma 2), i.e., υji ∼ N(0,1). Thus,
is a chi-squared random variable with dm degrees of freedom, and it follows from Lemma 3:
which is equivalent to the following:
| (36) |
Under the event in Eq. (36), we bound as
| (37) |
Similarly, under the event in Eq. (36), we have
| (38) |
Combine Eq. (33), Eq. (37), Eq. (38) and Lemma 1, we verify Theorem 2.
Proof of Theorem 3
Proof. Let ΓP = P̂ − P, ΓQ = Q̂ − Q. Setting P = P*, Q = Q*, P* and Q* are the true weight matrices in Eq. (10), we have XT vec(P + Q) = XT vec(P* + Q*) = vec(F*). Following Eq. (18), we obtain
| (39) |
Under Assumption 1, we have
| (40) |
| (41) |
Substituting Eq. (40) and Eq. (41) into Eq. (39), we obtain
which directly leads to Eq. (21).
Following Assumption 1, we have
which imply that
| (42) |
| (43) |
Substituting Eq. (42) and Eq. (43)) into Eq. (40) and Eq. (41), and considering Eq. (21), we can easily verify Eq. (22) and Eq. (23).
To prove Eq. (28), we need to show the following two:
| (44) |
| (45) |
We first prove (a) by contradiction. Assume there exists a j1 such that
. Then according to the definitions of
and
(P*), we have
which contradicts with the following fact:
| (46) |
We thus verify (a). Similarly, if we assume there exists a j2 such that , then using the condition in Eq. (24) and the definition of in Eq. (26), we have
which contradicts with Eq. (46), thus (b) holds. Combining (a) and (b), we verify Eq. (28). Similarly, we can prove Eq. (29).□
Footnotes
For notation simplicity, we assume that the number of training samples of all tasks are the same. However, the following theoretical analysis can be easily extended to the case with different training sample sizes for different tasks.
Contributor Information
Pinghua Gong, Email: gph08@mails.tsinghua.edu.cn.
Jieping Ye, Email: Jieping.Ye@asu.edu.
Changshui Zhang, Email: zcs@mail.tsinghua.edu.cn.
References
- 1.Ando R, Zhang T. A framework for learning predictive structures from multiple tasks and unlabeled data. JMLR. 2005;6:1817–1853. [Google Scholar]
- 2.Argyriou A, Evgeniou T, Pontil M. Convex multi-task feature learning. Machine Learning. 2008;73(3):243–272. [Google Scholar]
- 3.Bach F, Jenatton R, Mairal J, Obozinski G. Optimization with sparsity-inducing penalties. Arxiv preprint arXiv:1108.0775. 2011 [Google Scholar]
- 4.Bakker B, Heskes T. Task clustering and gating for bayesian multitask learning. JMLR. 2003;4:83–99. [Google Scholar]
- 5.Baxter J. A model of inductive bias learning. Journal of Artificial Intelligence Research. 2000;12:149–198. [Google Scholar]
- 6.Beck A, Teboulle M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Journal on Imaging Sciences. 2009;2(1):183–202. [Google Scholar]
- 7.Bickel P, Ritov Y, Tsybakov A. Simultaneous analysis of lasso and dantzig selector. The Annals of Statistics. 2009;37(4):1705–1732. [Google Scholar]
- 8.Caruana R. Multitask learning. Machine Learning. 1997;28(1):41–75. [Google Scholar]
- 9.Chen J, Liu J, Ye J. Learning incoherent sparse and low-rank patterns from multiple tasks. SIGKDD. 2010:1179–1188. doi: 10.1145/2086737.2086742. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Chen J, Zhou J, Ye J. Integrating low-rank and group-sparse structures for robust multi-task learning. SIGKDD. 2011:42–50. [Google Scholar]
- 11.Evgeniou T, Pontil M. Regularized multi–task learning. SIGKDD. 2004:109–117. [Google Scholar]
- 12.Gong P, Gai K, Zhang C. Efficient Euclidean projections via piecewise root finding and its application in gradient projection. Neurocomputing. 2011:2754–2766. [Google Scholar]
- 13.Horn R, Johnson C. Matrix analysis. Cambridge University Press; 1990. [Google Scholar]
- 14.Jacob L, Bach F, Vert J. Clustered multi-task learning: A convex formulation. NIPS. 2008 [Google Scholar]
- 15.Jalali A, Ravikumar P, Sanghavi S, Ruan C. A dirty model for multi-task learning. NIPS. 2010 [Google Scholar]
- 16.Kang Z, Grauman K, Sha F. Learning with whom to share in multi-task feature learning. ICML. 2011 [Google Scholar]
- 17.Kim S, Xing E. Tree-guided group lasso for multi-task regression with structured sparsity. ICML. 2009 [Google Scholar]
- 18.Lawrence N, Platt J. Learning to learn with the informative vector machine. ICML. 2004 [Google Scholar]
- 19.Liu J, Ji S, Ye J. Multi-task feature learning via efficient ℓ2,1-norm minimization. UAI. 2009:339–348. [Google Scholar]
- 20.Liu J, Ji S, Ye J. Slep: Sparse learning with efficient projections. Arizona State University. 2009 [Google Scholar]
- 21.Liu J, Yuan L, Ye J. An efficient algorithm for a class of fused lasso problems. SIGKDD. 2010:323–332. [Google Scholar]
- 22.Lounici K, Pontil M, Tsybakov A, Van De Geer S. Taking advantage of sparsity in multi-task learning. COLT. 2009 [Google Scholar]
- 23.Negahban S, Wainwright M. Joint support recovery under high-dimensional scaling: Benefits and perils of ℓ1,∞-regularization. NIPS. 2008;21 [Google Scholar]
- 24.Negahban S, Wainwright M. Estimation of (near) low-rank matrices with noise and high-dimensional scaling. The Annals of Statistics. 2011;39(2):1069–1097. [Google Scholar]
- 25.Nesterov Y. Introductory lectures on convex optimization: A basic course. Springer Netherlands; 2004. [Google Scholar]
- 26.Nesterov Y. Gradient methods for minimizing composite objective function. Center for Operations Research and Econometrics (CORE), Catholic University of Louvain, Tech Rep. 2007;76 [Google Scholar]
- 27.Obozinski G, Taskar B, Jordan M. Multi-task feature selection. Statistics Department, UC Berkeley, Tech Rep. 2006 [Google Scholar]
- 28.Parameswaran S, Weinberger K. Large margin multi-task metric learning. NIPS. 2010;23:1867–1875. [Google Scholar]
- 29.Pong T, Tseng P, Ji S, Ye J. Trace norm regularization: Reformulations, algorithms, and multi-task learning. SIAM Journal on Optimization. 2010;20(6):3465–3489. [Google Scholar]
- 30.Quadrianto N, Smola A, Caetano T, Vishwanathan S, Petterson J. Multitask learning without label correspondences. NIPS. 2010 [Google Scholar]
- 31.Schwaighofer A, Tresp V, Yu K. Learning Gaussian process kernels via hierarchical bayes. NIPS. 2005;17:1209–1216. [Google Scholar]
- 32.Thrun S, O'Sullivan J. Discovering structure in multiple learning tasks: The tc algorithm. ICML. 1996:489–497. [Google Scholar]
- 33.Wallace D. Bounds on normal approximations to student's and the chi-square distributions. The Annals of Mathematical Statistics. 1959:1121–1130. [Google Scholar]
- 34.Xue Y, Liao X, Carin L, Krishnapuram B. Multi-task learning for classification with dirichlet process priors. JMLR. 2007;8:35–63. [Google Scholar]
- 35.Yang X, Kim S, Xing E. Heterogeneous multitask learning with joint sparsity constraints. NIPS. 2009;23 [Google Scholar]
- 36.Yu K, Tresp V, Schwaighofer A. Learning Gaussian processes from multiple tasks. ICML. 2005:1012–1019. [Google Scholar]
- 37.Yuan L, Liu J, Ye J. Efficient methods for overlapping group lasso. NIPS. 2011 doi: 10.1109/TPAMI.2013.17. [DOI] [PubMed] [Google Scholar]
- 38.Zhang J, Ghahramani Z, Yang Y. Learning multiple related tasks using latent independent component analysis. NIPS. 2006;18:1585–1592. [Google Scholar]
- 39.Zhang Y, Yeung D. Multi-task learning using generalized t process. AISTATS. 2010 [Google Scholar]
- 40.Zhang Y, Yeung D. Transfer metric learning by learning task relationships. SIGKDD. 2010:1199–1208. [Google Scholar]
- 41.Zhang Y, Yeung D, Xu Q. Probabilistic multi-task feature selection. NIPS. 2010 [Google Scholar]
- 42.Zhou J, Chen J, Ye J. Clustered multi-task learning via alternating structure optimization. NIPS. 2011 [PMC free article] [PubMed] [Google Scholar]
- 43.Zhou J, Chen J, Ye J. MALSAR: Multi-tAsk Learning via StructurAl Regularization. Arizona State University; 2012. [Google Scholar]
- 44.Zhou J, Yuan L, Liu J, Ye J. A multi-task learning formulation for predicting disease progression. SIGKDD. 2011:814–822. [Google Scholar]