
Figure 8.
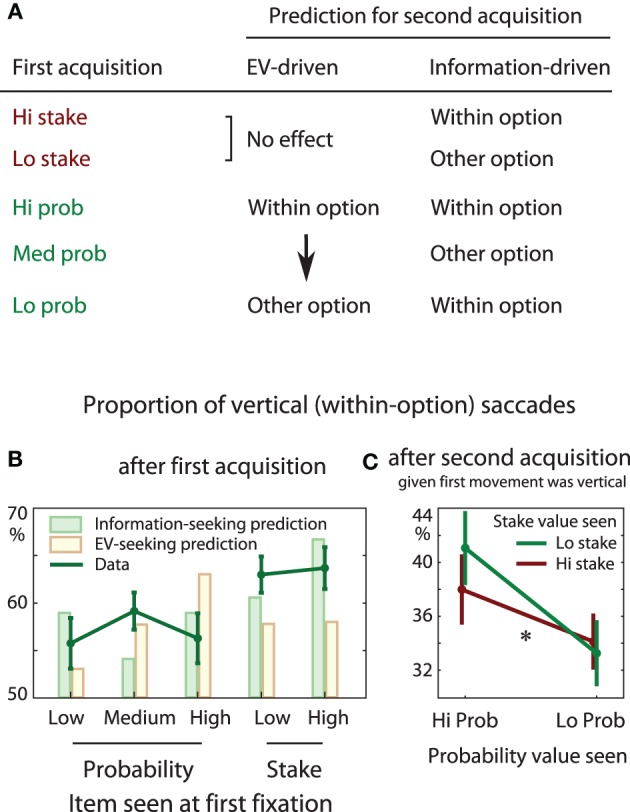
(A) Attention may be guided by EV or by information seeking. The two drives predict different patterns of fixation in our task. If attention were EV-seeking, gaze ought to remain within the current option if the first-seen item was a high probability, but not if it were a low probability. On the other hand, if attention were information-seeking, gaze ought to remain within the current option if a high stake was seen, compared to a low stake. (B) After the first fixation, participants may look vertically within the option, or across to the other option. Where they look next depends on what they just saw: within-option saccades are commoner after seeing a stake. This is predicted when attention is information-driven, rather than EV-driven. Green bars represent the theoretical information gain from making a within-option saccade, calculated as 〈DKL [posterior EV || prior EV]〉prior p,s, which represents how much information one could expect to learn after making a particular saccade. Yellow bars represent the Bayesian estimate of EV of the current option. Both green (information) and yellow (EV) bars are arbitrarily scaled. (C) On trials where the first two acquisitions were within one gamble, participants sometimes refixate the first item seen. This is more likely when the probability was high (p = 0.047), but there was no effect of stake (p > 0.05, with no interaction).