
Figure 1.
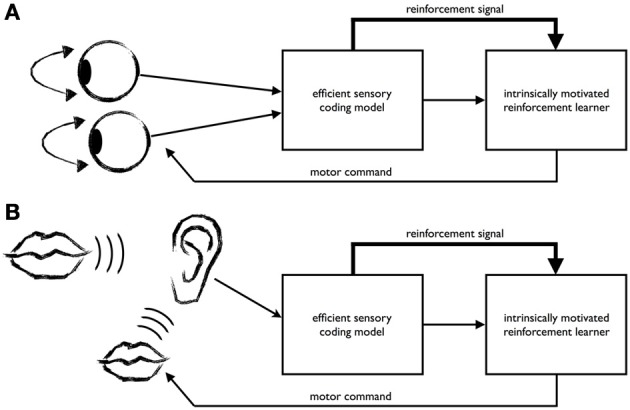
The recently proposed intrinsically motivated learning architecture for efficient coding in active perception (A) also gives rise to the development of imitation (B). (A) The learning architecture comprises an efficient coding model for the sensory input and an intrinsically motivated reinforcement learning mechanism for generating behavior. In the example of Zhao et al. (2012), the efficient coding model learns a sparse code for binocular images, while the reinforcement learner generates vergence eye movements. To this end, it receives from the sensory coding model a representation of the sensory input (thin arrow) and an internally generated reward signal reflecting how well the sensory model could encode the binocular input (thick arrow). Both the sensory coding model and the reinforcement learner try to optimize the encoding of the data. The system discovers that the input data can be encoded most efficiently when vergence commands are used to minimize binocular disparity. (B) The learner acquires an efficient encoding of speech signals provided by a tutor (big mouth). When the learner starts babbling (small mouth), the resulting acoustic signals are encoded by the sensory model that has been tuned to the tutor's speech. Signals that are easy to encode for the sensory model because the utterance sounds similar to the tutor's speech will produce a high reinforcement signal. Through this, the system's utterances are progressively driven to approximate the tutor's speech.