

Abstract
The present experiments investigated how the process of statistically segmenting words from fluent speech is linked to the process of mapping meanings to words. Seventeen-month-old infants first participated in a statistical word segmentation task, which was immediately followed by an object-label-learning task. Infants presented with labels that were words in the fluent speech used in the segmentation task were able to learn the object labels. However, infants presented with labels consisting of novel syllable sequences (nonwords; Experiment 1) or familiar sequences with low internal probabilities (part-words; Experiment 2) did not learn the labels. Thus, prior segmentation opportunities, but not mere frequency of exposure, facilitated infants' learning of object labels. This work provides the first demonstration that exposure to word forms in a statistical word segmentation task facilitates subsequent word learning.
By the end of the first year of life, infants have learned a great deal about the sound structure of their native language, from individual phonemes and phoneme combinations to the cues that signal word boundaries in fluent speech (e.g., Saffran, Werker, & Werner, 2006). One-year-old infants are also just beginning to link meanings to words, as they make the transition from perceiving the language around them to understanding and producing words (Bates, Dale, & Thal, 1995). However, relatively little is known about how infants apply their knowledge of the sounds of their language to the problem of linking meanings to words (Hollich, Jusczyk, & Luce, 2002; Saffran & Graf Estes, 2006; Stager & Werker, 1997).
Word segmentation is one process that connects infants' early learning about the sounds of words and their subsequent association of those sounds with meanings. Before infants can learn the function of a word or associate it with a meaning, the sounds corresponding to the word must be segmented from fluent speech (because most words infants hear are not spoken in isolation; Brent & Siskind, 2001; Woodward & Aslin, 1990). Infants' learning about the sound structure of their native language provides them with a basis for segmenting words from the speech stream using phonotactic patterns (Mattys & Jusczyk, 2001), stress patterns within words (Jusczyk, Houston, & Newsome, 1999), and patterns in allophonic variations (Jusczyk, Hohne, & Bauman, 1999), among other cues.
Studies using artificial languages suggest that infants are adept at using statistical information in the speech stream to identify word boundaries. Saffran, Aslin, and Newport (1996) found that infants were able to segment speech sounds corresponding to words in a fluent speech stream after listening to 2 min of an artificial language. There were no pauses or other acoustic cues to word boundaries (e.g., orthographically, golabupadotitupiro …). The only available segmentation cue was that the transitional probabilities from one syllable to the next were markedly higher within words (1.0) than across word boundaries (.33). This pattern of higher transitional probabilities within words than across word boundaries is also characteristic of natural infant-directed speech (Swingley, 2005).
In demonstrating infants' statistical word segmentation skills, Saffran et al. (1996) found that infants could discriminate sound sequences that were words in the artificial language (e.g., golabu) from nonword sequences (syllables that were from the language but presented in a novel order, e.g., tilado), listening longer to the nonwords in a head-turn preference procedure. Infants could also discriminate words from part-words (syllable sequences spanning word boundaries, e.g., bupado, from golabu#padoti). Infants' successful discrimination of word and part-word sequences is particularly impressive because both kinds of sequences appeared frequently in the artificial language (Aslin, Saffran, & Newport, 1998).
Although these results indicate that infants can discriminate between likely and unlikely sound sequences, they do not address the nature of the representations that infants acquire during word segmentation. Such studies are typically invoked as a demonstration that infants can segment individual words from the speech stream. However, what they actually demonstrate is that infants distinguish between sound sequences with low versus high internal transitional probabilities. Are infants' representations of the sequences with high transitional probability truly wordlike? This is a largely unaddressed question that applies quite generally across the literature on word segmentation in infants (though see Saffran, 2001, and Hollich, 2006). We addressed this issue by asking whether infants treat such high-probability sequences as candidate words. That is, are these sequences mere sounds, or do infants expect that they are sounds that can be linked to meanings? One act that learners typically perform with words is mapping wordlike sounds to meanings. Although knowledge of words extends far beyond their use as labels, establishing a connection between sound and meaning is an essential part of learning words, especially for young children. Thus, in the experiments reported here, we investigated the output of statistical learning by testing whether newly segmented sound sequences are available to be mapped to novel meanings.
To test infants' ability to associate meanings with newly segmented words, we combined two established methods for testing infants. Infants were first familiarized with fluent speech in a statistical word segmentation task similar to those used in previous studies (Aslin et al., 1998; Saffran et al., 1996). The infants then immediately participated in a label-object association task, a measure of infants' learning of new object labels (Stager & Werker, 1997; Werker, Cohen, Lloyd, Casasola, & Stager, 1998). In this task, the infants were habituated to two label-object pairings, via a loudspeaker and computer monitor. After habituation, we measured looking time to two types of test trials: those in which the original label-object pairings were maintained (same trials) and those in which the original pairings were violated (switch trials). Our measure of word learning was whether the infant looked longer on switch trials than on same trials, which would indicate that the infant noticed the altered pairing. Critically, for half the infants, the labels were words from the artificial language that had been heard during the word segmentation task; for the other half of the infants, the labels were either nonwords (Experiment 1) or part-words (Experiment 2).
We predicted that if the statistics of the speech stream in the segmentation task influenced subsequent word learning, then infants learning object labels that were words in the speech stream would be more successful than infants learning nonword or part-word labels. Specifically, infants learning word labels would be expected to show the greatest looking-time difference between same and switch test trials. This prediction is consistent with the hypothesis that word segmentation and word learning are linked and, further, that the output of this statistical learning mechanism yields candidate words that support the mapping of sound to meaning. Alternatively, if the statistics of the speech stream do not influence subsequent word learning, infants would be expected to perform similarly on same and switch test trials regardless of whether they were learning word, nonword, or part-word object labels.
Experiment 1
Experiment 1 tested infants' learning of object labels that were words in the segmentation task versus object labels that were nonwords (i.e., did not appear) in the word segmentation task. Thus, infants had the opportunity to statistically segment the sound sequences corresponding to the words before they acted as labels. The sound sequences in the nonwords, although made of familiar syllables, were novel prior to the label-object association task.
Method
Subjects
Twenty-eight 17-month-old monolingual English-learning infants (mean age = 17.4 months, range: 17.0−18.1) were randomly assigned to either the word or the nonword condition. All infants were born full-term, had fewer than five prior ear infections, and had no history of hearing or vision impairments. Data from 10 additional infants were excluded from analysis because of fussiness (8) or parental interference (2).
Stimulus Materials
Word Segmentation Task
To control for possible arbitrary listening preferences, we created two counterbalanced versions of the artificial language (Language 1: timay, dobu, piga, mano; Language 2: nomay, mati, gabu, pido). Words from Language 1 were nonwords for Language 2, and vice versa (see Table 1). A trained female speaker unfamiliar with the stimuli read sequences of approximately 20 syllables from each language; each sequence included 1 or 2 extra syllables at the beginning and end that were cut from the final recording. The syllables were spoken without pauses, forming a fluent speech stream (e.g., pigatimaydobu …) with a consistent rate (96 syllables/min) and pitch (F0 = 179 Hz). So that the speaker would not identify words in the languages and introduce word-boundary cues, syllable sequences from the two counterbalanced languages were interspersed in her script. For each language, syllable sequences were then spliced together to form a speech stream containing 60 repetitions of each word in a pseudorandom order, with no word appearing twice in succession. Each speech stream was 2.5 min long. The only reliable cue to word boundaries was the statistical structure of the language (within-word transitional probabilities = 1.0, across-word probabilities = .33).
Table 1. Test Words, Nonwords, and Part-Words in Experiments 1 and 2.
| Language | Experiment 1 | Experiment 2 | ||
|---|---|---|---|---|
|
|
|
|||
| Words | Nonwords | Words | Part-words | |
| Language 1 | timay, dobu | nomay, gabu | timay, dobu | pimo, kuga |
| Language 2 | nomay, gabu | timay, dobu | pimo, kuga | timay, dobu |
Object-Labeling Task
The novel objects were two computerized 3-D images similar in size (15 × 10 cm, 12 × 15 cm) but highly discriminable in shape and color.
Each infant received one of two sets of label-object pairs (i.e., manipulation of condition was between subjects). One set contained words from the segmentation task (e.g., timay in Language 1). The other set contained nonwords (e.g., gabu for Language 1).
Each infant participated in one of four testing conditions: Half of the infants exposed to Language 1 received two word test items, and half received two nonword test items; half the infants exposed to Language 2 received two word test items, and half received two nonword test items.
Apparatus
Testing was performed in a 2-m × 2-m soundproof booth. A flat-screen monitor on the front wall displayed the computerized objects; a loudspeaker was located below the screen. The infant sat on a parent's lap or in a booster seat 1 m from the screen. A camera mounted on the front wall enabled the observer, located outside the booth, to monitor looking behavior.
Procedure
Each infant first listened to the 2.5-min fluent speech stream, while watching a cartoon. The segmentation task was immediately followed by the label-object association task, a measure of early word learning with minimal task demands (Werker et al., 1998). Although the label-object association task lacks a social referential context, it does retain an essential aspect of word learning: linking a sound sequence with a meaning representation (here, object identity).
The program Habit 2000 (Cohen, Atkinson, & Chaput, 2000) was used to present label-object combinations. As a protection against bias, the observer was blind to the identity of the materials being presented, and the parent listened to masking music over headphones.
During the habituation phase, the infant viewed two different label-object combinations, presented one at a time in random order. An object moved from side to side while its associated label played. The label-object combination played for as long as the infant looked at the screen. Trials were terminated when the infant looked away from the screen for 1 s, or after a maximum looking time of 20 s. A cartoon guided the infant's attention back to the screen between trials. The habituation criterion was satisfied when looking time across three consecutive trials decreased to 50% of the average looking time across the first three trials. The mean number of trials to reach the habituation criterion (see Table 2) did not differ across conditions, t(26) < 1.
Table 2. Mean Number of Trials to Reach the Habituation Criterion in Experiments 1 and 2.
| Experiment | Condition | ||
|---|---|---|---|
|
| |||
| Word | Nonword | Part-word | |
| Experiment 1 | 10.79 (5.60) | 10.43 (3.90) | — |
| Experiment 2 | 10.93 (5.89) | — | 12.57 (6.70) |
Note. Standard deviations are given in parentheses.
Test trials began immediately after the infant habituated or reached the maximum cutoff of 25 trials (all infants in this experiment met the habituation criterion). During same trials, the infant viewed the label-object combinations from the habituation phase. During switch trials, the labels for the two objects were switched; for example, Object 1 occurred with Label 2. There were four same and four switch trials, organized into two counterbalanced testing orders.
Results and Discussion
We first compared the looking-time differences for same and switch test trials (switch-trial looking time — same-trial looking time) for infants who heard the two counterbalanced familiarization languages (Language 1 and Language 2). There were no significant looking-time differences between languages in either the word condition, t(12) < 1, or the nonword condition, t(12) < 1. Therefore, performance was collapsed across the two languages in the subsequent analyses.
To examine the effects of exposure to the artificial language on performance in the label-object association task, we performed a 2 (trial type: same vs. switch) × 2 (condition: word vs. nonword labels) mixed analysis of variance (ANOVA). There was no main effect of trial type, F(1, 26) = 1.77, n.s., or condition, F(1, 26) = 2.66, n.s. However, there was a significant Trial Type × Condition interaction, F(1, 26) = 4.99, p = .03, prep = .91 (see Killeen, 2005), ηp2 = .16. To examine this interaction (shown in Fig. 1), we performed a set of planned comparisons using paired t tests. Whereas infants learning nonword object labels showed no difference in looking time between same and switch test trials, t(13) < 1, infants learning word labels exhibited significantly longer looking times on switch trials than on same trials, t(13) = 2.31, p = .04, prep = .98, d = 0.42. Eleven of 14 infants in the word condition and 5 of 14 infants in the nonword condition showed the switch-trial preference.
Fig. 1.
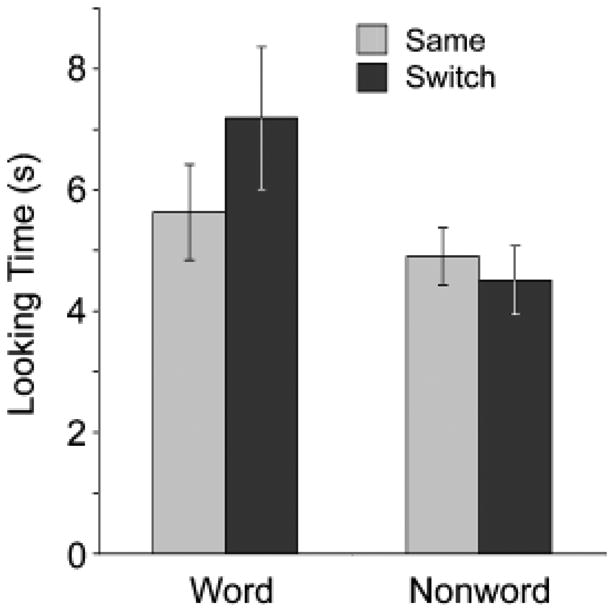
Experiment 1: mean looking times (±1 SE) on same and switch test trials for infants in the word and nonword conditions.
These results suggest that prior exposure to the fluent speech facilitated infants' learning of the word object labels, whereas infants exposed to nonword object labels showed no evidence of learning.1 However, it remains unclear which aspect o infants' familiarization during the word segmentation task facilitated the subsequent mapping of sounds to meanings. Our previous discussion focused on the potential role of the internal statistics of the word sequences in facilitating label learning. However, there is a simpler explanation: The mere frequency of occurrence of the word sequences in the artificial language may have facilitated learning. Each of the test words occurred 60 times in the segmentation speech stream, whereas the nonwords never occurred. In order to more directly investigate the potential influence of statistical structure, it is necessary to equate the frequency of the labels during familiarization while maintaining differences in their internal transitional probabilities; this is the approach we took in Experiment 2.
Experiment 2
In this experiment, we used words and part-words (sequences that spanned word boundaries in the segmentation stream) as labels in the label-object association task. Part-word sequences have the opportunity to become familiar because the syllable sequences occur in the artificial language, whereas nonword sequences do not. The words and part-words were presented in a frequency-balanced artificial language (Aslin et al., 1998) designed to equate frequency of word and part-word test sequences. Of the four words in each language, two occurred twice as often as the other two (i.e., there were two high-frequency words and two low-frequency words). The part-words formed by the high-frequency words occurred as often as the low-frequency words. The two low-frequency words and the two (equally frequent) high-frequency part-words served as labels in the label-object association task. Thus, the test items differed in their internal statistical structure, but not in their frequency of exposure. Using this design, it was possible to directly assess the effects of the statistical structure of our labels.
As in Experiment 1, infants participated in a segmentation task followed by a label-object association task. The labels were either words or part-words from the segmentation stream. If the familiarity or frequency of a sound sequence is critical for learning, then infants would be expected to show equivalent learning of the word and part-word labels. However, if the pre-dictiveness or internal structure of a sound sequence is critical, then infants would be expected to find the word labels easier to acquire than the part-word labels.
Method
Subjects
Twenty-eight 17-month-olds participated (mean age = 17.5 months, range: 17.0–18.0). Data from 13 additional infants were excluded because of fussiness (6), parental interference (2), and experimenter error or equipment failure (5).
Stimulus Materials
In order to more closely approximate the operations of a speech synthesizer (a synthesizer was used to create previous artificial languages, e.g., Saffran et al., 1996), we used a different procedure to record the languages used in Experiment 2. A female speaker recorded three-syllable sequences, of which only the middle syllables were used in the final speech stream (e.g., the sequences timaydo, maydobu, dobuga were spliced to form the sequence maydobu). The syllables were recorded in three-syllable sets to maintain the appropriate coarticulation contexts for the target syllables. These middle syllables were spliced into a fluent speech stream with no pauses or other reliable acoustic cues to word boundaries (98 syllables/min; F0 = 224 Hz). As in Experiment 1, we generated two counterbalanced languages (Language 1 words: timay, dobu, gapi, moku; Language 2 words: pimo, kuga, buti, maydo; see Table 1).
So that the frequency of the word and part-word test items would be balanced, the two low-frequency words each occurred 90 times in the speech stream (Language 1: timay and dobu; Language 2: pimo and kuga), and the two high-frequency words occurred 180 times (Language 1: gapi and moku; Language 2: buti and maydo). This design yielded two part-words that each occurred 90 times in the language. For example, in Language 1, the sequence gapi-moku was repeated 90 times; therefore, the part-word sequence pimo occurred the same number of times as the low-frequency words in the language. As in Experiment 1, the only cue to word boundaries was the statistical structure of the language (within-word transitional probabilities = 1.0; across-word probabilities = 0–.5). The transitional probability of the part-word test sequences was .5 (e.g., half of the time gapi occurred, it preceded moku). Thus, although the word and part-word test items were equally frequent, the word test items had higher internal transitional probabilities than the part-word test items. The duration of each speech stream was 5.5 min. The exposure was lengthened relative to Experiment 1 because frequency-balanced languages typically require additional exposure (e.g., Aslin et al., 1998).
The novel object stimuli were the same as in Experiment 1.
Procedure
The procedure was similar to that of Experiment 1. To accommodate the longer speech-stream familiarization period, we allowed the infants and parents to move around the testing room while playing or snacking quietly. Parents were asked to avoid referring to the artificial language. Following familiarization, the toys were removed, and parents received instructions for the next part of the experiment. Because of this slight delay, infants received a 30-s refamiliarization with the artificial language before beginning the label-object association task.
Habituation and testing followed the same procedures as in Experiment 1, except for a change in testing orders. Pilot testing and previous studies (Aslin et al., 1998) indicated that learning word sequences from frequency-balanced languages was likely to be more difficult than learning word sequences from non-balanced artificial languages (perhaps because in this design, the highly frequent words—which do not serve as test items— are likely to be learned first). Therefore, the testing orders in Experiment 2 were selected to promote infants' ability to exhibit learning; all infants (in both the word and part-word conditions) began testing with switch test trials. In pilot testing, we observed that infants' attention tended to decrease over the course of testing. We thus gave all infants the opportunity to dishabituate to switch trials at the beginning of testing. If anything, this manipulation should have increased the probability that infants in the part-word condition (along with those in the word condition) would show the same-switch difference that is our index of learning.
The mean number of trials to reach the habituation criterion (see Table 2) did not differ between the two conditions, t(26) < 1. Three infants, 2 from the part-word condition and 1 from the word condition, failed to habituate. The pattern of results was unchanged with the data from these infants excluded.
Results and Discussion
As in Experiment 1, we first examined effects of the two counterbalanced languages. There were no significant looking-time differences between languages in either the word condition, t(12) < 1, or the part-word condition, t(12) = 1.22, n.s. Therefore, performance was collapsed across languages in the subsequent analyses.
We performed a 2 (trial type: same vs. switch) × 2 (condition: word vs. part-word labels) mixed ANOVA to examine label learning. There was no main effect of trial type, F(1, 26) = 1.85, n.s., or condition, F(1, 26) < 1. There was a significant interaction of trial type and condition, F(1, 26) = 5.09, p = .03, prep = .91, ηp2 = .16.
To examine the interaction (see Fig. 2), we performed paired t tests comparing looking times on switch versus same trials for infants in the word and part-word conditions separately. Infants exposed to word labels looked significantly longer on switch than on same test trials, t(13) = 2.31, p = .04, prep = .93, d = 0.53, whereas infants exposed to part-word labels showed no looking-time difference between same and switch trials, t(13) < 1. Ten of 14 infants in the word condition and 5 of 14 infants in the part-word condition showed the switch-trial preference.
Fig. 2.
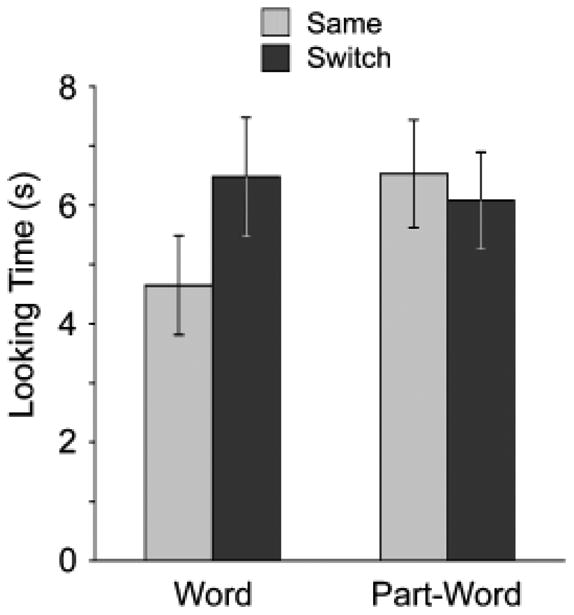
Experiment 2: mean looking times (±1 SE) on same and switch test trials for infants in the word and part-word conditions.
As in Experiment 1, only infants exposed to word labels exhibited learning in the object-labeling task; they dishabituated on switch test trials, in which the original label-object pairings were violated. Infants exposed to part-word labels gave no indication that they learned the labels. This is particularly striking given that the infants heard the part-words as often as they heard the words during the segmentation task.
General Discussion
In two experiments, we have shown that newly segmented words were easier for 17-month-old infants to link to objects than were novel sequences of familiar sounds (Experiment 1) or familiar sound sequences with weak internal structure (Experiment 2). These findings support the intuition that there is a connection between the processes of segmenting words and linking words to meanings. Although this connection may be expected—word segmentation is likely a necessary first step to learning many words—these results are among the first to link word segmentation and word learning (see also Hollich, 2006; Swingley, 2002), and they are the first demonstration of a connection between statistical word segmentation and word learning.
The findings also support the hypothesis that statistical segmentation processes generate candidate words. Statistical learning, broadly defined as learning from distributional information, is argued to play a role in many aspects of language acquisition (phonology, prosodic patterns, grammar). However, researchers know little about the output of this mechanism. In particular, it is unclear whether the representations yielded by statistical learning have any linguistic status (Saffran, 2001).2 There has been some debate about whether such learning involves language-relevant processes (Naigles, 2002, 2003; Tomasello & Akhtar, 2003). This question is difficult to address because it requires tapping infants' underlying representations of sound sequences. However, the present study indicates that infants' representations are accessible. We queried infants' representations of sound sequences by asking whether infants treat high-transitional-probability sequences from an artificial language as they treat words, that is, whether these sounds can be used in a task that is typically performed with (natural-language) words—mapping to meaning. Our results demonstrating that infants can use statistically segmented word forms as object labels support the claim that statistically segmented sound sequences are actually wordlike.
A key aspect of these findings is that experience with sound sequences affects label learning, but not because of mere exposure and resulting familiarity. Instead, the internal structure of the sound sequences is crucial. Experiment 2 demonstrated that when two types of sound sequences occur with equal frequency in a speech stream, only sequences with strong internal structure are subsequently learned as object labels. These findings indicate that simply hearing sounds together in sequence is not enough; the predictiveness of the sound sequence is key for constituting a “good word”.
The present experiments indicate that the learning mechanisms used in statistical word segmentation experiments yield representations that have linguistic status. With these experiments, we have taken a step toward demonstrating that statistical language learning is not merely a trick that infants can perform in soundproof booths, but is instead a powerful process that has significance for important tasks in language development, including linking sounds to meanings during word learning.
Acknowledgments
This research was supported by grants from the National Institute on Deafness and Other Communication Disorders (F31-DC07277) to K.G.E., from the National Institute of Child Health and Human Development (NICHD; R01HD37466) and the National Science Foundation (BCS-9983630) to J.R.S., and from NICHD (P30HD03352) to the Waisman Center. We thank Rebecca Seibel, Dana Emerson, Jessica Hay, Kelli Minor, Rebecca Porwoll, Julie Rhein, Sarah Sahni, and especially Erik Thiessen for their assistance with this research. We also thank the families who generously contributed their time.
Footnotes
It is interesting to consider why lnfants in the nonword condition failed to exhibit learning, given successes in prior experiments using label-object association tasks (e.g., Werker, Fennell, Corcoran, & Stager, 2002). We ran a series of control studies to investigate this question; these bisyllabic labels appear to be difficult to learn even in the absence of a word segmentation task. However, when the labels were presented using infant-directed intonation (rather than the original monotone) in the label-object association task, infants could learn them. This result is consistent with recent results suggesting a role for infant-directed speech in early word learning (e.g., Thiessen, Hill, & Saffran, 2005).
Indeed, statistical learning has been implicated in nonlinguistic learning by infants and in learning by nonhuman animals. The current results suggest one way that a domain-general learning mechanism may be used to generate domain-specific knowledge. We are currently testing infants' learning of nonlinguistic stimuli in a similar task.
References
- Aslin RN, Saffran JR, Newport EL. Computation of conditional probability statistics by 8-month-old infants. Psychological Science. 1998;9:321–324. [Google Scholar]
- Bates E, Dale P, Thal D. Individual differences and their implications for theories of language development. In: Fletcher P, MacWhinney B, editors. Handbook of child language. Oxford, England: Basil Blackwell; 1995. pp. 96–151. [Google Scholar]
- Brent MR, Siskind JM. The role of exposure to isolated words in early vocabulary development. Cognition. 2001;81:B33–B44. doi: 10.1016/s0010-0277(01)00122-6. [DOI] [PubMed] [Google Scholar]
- Cohen LB, Atkinson DJ, Chaput HH. Habit 2000: A new program for testing infant perception and cognition (Version 2.2.5c) Austin: University of Texas; 2000. Computer software. [Google Scholar]
- Hollich G. Combining techniques to reveal emergent effects in infants' segmentation, word learning, and grammar. Language and Speech. 2006;49:3–19. doi: 10.1177/00238309060490010201. [DOI] [PubMed] [Google Scholar]
- Hollich G, Jusczyk PW, Luce PA. Lexical neighborhood effects in 17-month-old word learning; Paper presented at the 26th Annual Boston University Conference on Language Development; Boston, MA. 2002. Nov, [Google Scholar]
- Jusczyk PW, Hohne EA, Bauman A. Infant's sensitivity to allophonic cues for word segmentation. Perception & Psychophysics. 1999;61:1465–1476. doi: 10.3758/bf03213111. [DOI] [PubMed] [Google Scholar]
- Jusczyk PW, Houston DM, Newsome M. The beginnings of word segmentation in English-learning infants. Cognitive Psychology. 1999;39:159–207. doi: 10.1006/cogp.1999.0716. [DOI] [PubMed] [Google Scholar]
- Killeen PR. An alternative to null-hypothesis significance tests. Psychological Science. 2005;16:345–353. doi: 10.1111/j.0956-7976.2005.01538.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mattys SL, Jusczyk PW. Phonotactic cues for segmentation of fluent speech by infants. Cognition. 2001;78:91–121. doi: 10.1016/s0010-0277(00)00109-8. [DOI] [PubMed] [Google Scholar]
- Naigles LR. Form is easy, meaning is hard: Resolving a paradox in early child language. Cognition. 2002;86:157–199. doi: 10.1016/s0010-0277(02)00177-4. [DOI] [PubMed] [Google Scholar]
- Naigles LR. Paradox lost? No, paradox found! Reply to Tomasello and Akhtar (2003) Cognition. 2003;88:325–329. doi: 10.1016/s0010-0277(03)00048-9. [DOI] [PubMed] [Google Scholar]
- Saffran JR. Words in a sea of sounds: The output of infant statistical learning. Cognition. 2001;81:149–169. doi: 10.1016/s0010-0277(01)00132-9. [DOI] [PubMed] [Google Scholar]
- Saffran JR, Aslin RN, Newport EL. Statistical learning by 8-month-old infants. Science. 1996;274:1926–1928. doi: 10.1126/science.274.5294.1926. [DOI] [PubMed] [Google Scholar]
- Saffran JR, Graf Estes K. Advances in child development and behavior. Vol. 34. New York: Elsevier; 2006. Mapping sound to meaning: Connections between learning about sounds and learning about words; pp. 1–38. [DOI] [PubMed] [Google Scholar]
- Saffran JR, Werker JF, Werner LA. The infant's auditory world: Hearing, speech, and the beginnings of language. In: Siegler R, Kuhn D, editors. Handbook of child development. Vol. 6. New York: Wiley; 2006. pp. 58–108. [Google Scholar]
- Stager CL, Werker JF. Infants listen for more phonetic detail in speech perception than in word-learning tasks. Nature. 1997;388:381–382. doi: 10.1038/41102. [DOI] [PubMed] [Google Scholar]
- Swingley D. On the phonological encoding of novel words by one-year-olds; Paper presented at the 27th Annual Boston University Conference on Language Development; Boston, MA. 2002. Nov, [Google Scholar]
- Swingley D. Statistical clustering and the contents of the infant vocabulary. Cognitive Psychology. 2005;50:86–132. doi: 10.1016/j.cogpsych.2004.06.001. [DOI] [PubMed] [Google Scholar]
- Thiessen ED, Hill EA, Saffran JR. Infant-directed speech facilitates word segmentation. Infancy. 2005;7:53–71. doi: 10.1207/s15327078in0701_5. [DOI] [PubMed] [Google Scholar]
- Tomasello M, Akhtar N. What paradox? A response to Naigles (2002) Cognition. 2003;88:317–323. doi: 10.1016/s0010-0277(03)00048-9. [DOI] [PubMed] [Google Scholar]
- Werker JF, Cohen LB, Lloyd VL, Casasola M, Stager CL. Acquisition of word-object associations by 14-month-old infants. Developmental Psychology. 1998;34:1289–1309. doi: 10.1037//0012-1649.34.6.1289. [DOI] [PubMed] [Google Scholar]
- Werker JF, Fennell CT, Corcoran KM, Stager CL. Infants' ability to learn phonetically similar words: Effects of age and vocabulary size. Infancy. 2002;3:1–30. [Google Scholar]
- Woodward AL, Aslin RN. Segmentation cues in maternal speech to infants; Paper presented at the biennial meeting of the International Conference on Infant Studies, Montreal; Quebec, Canada. 1990. Apr, [Google Scholar]