
Table 3. Quality measures of the reconstructed hierarchies for the “hard” synthetic data set.
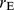
|
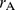
|
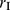
|
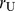
|
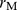
|
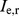
|
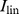
|
|
| algorithm A | 31% | 5% | 18% | 47% | 0% | 18% | 66% |
| algorithm B | 89% | 91% | 6% | 3% | 0% | 83% | 97% |
| P. Heymann & H. Garcia-Molina | 48% | 54% | 29% | 17% | 0% | 29% | 76% |
| P. Schmitz | 1% | 2% | 1% | 3% | 94% | 1% | 5% |
In this case the frequency of the initial tags was independent of their position in the exact hierarchy during the benchmark generation, and the frequency distribution followed a power-law. This change compared to the data set used in Table 2. results in significant decrease in the quality measures for most of the involved methods, as shown by the ratio of acceptable links, 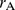 , the ratio of inverted links,
, the ratio of inverted links, 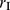 , the ratio of unrelated links,
, the ratio of unrelated links, 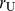 , the ratio of missing links,
, the ratio of missing links, 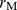 , the normalized mutual information between the exact- and the reconstructed hierarchies,
, the normalized mutual information between the exact- and the reconstructed hierarchies, 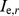 , and the linearized mutual information,
, and the linearized mutual information, 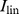 . The different rows correspond to results obtained from algorithm A, (1
. The different rows correspond to results obtained from algorithm A, (1 row), algorithm B, (2
row), algorithm B, (2 row), the method by P. Heymann & H. Garcia-Molina (3
row), the method by P. Heymann & H. Garcia-Molina (3 row), and the algorithm by P. Schmitz (4
row), and the algorithm by P. Schmitz (4 row).
row).