
Figure 7.
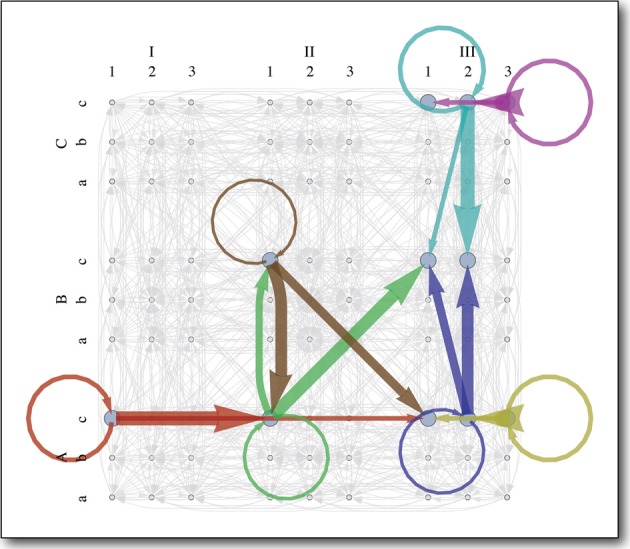
The learned single-arm MDP planner. The 4D state space is labeled as follows: shoulder flexion/extension (1,2,3), arm abduction/adduction (a,b,c), lateral/medial arm rotation (I,II,III), elbow flexion/extension (A,B,C). Each color represents an interesting state-action, which often takes the agent to some unexpected state. Each arrow of a particular color represents a state transition probability and the weight of the arrow is proportional to the magnitude of that probability. Arrows in gray represent boring state-actions. These work as expected, reliably taking the agent to the intended goal state, to which they point.