
Figure 6. Predicted evolution of the value responses according to an RL simulation.

Each panel shows the difference between the values of the optimal and non-optimal options, as a function of trial during a block, during the F (left panel) and I (right panel) of the main task. For the simulation we used a temporal discounting choice model, where the subjective value of each action (V) is updated by the temporally discounted prediction errors (R) resulting from both the immediate and the final rewards [12]. The simulations included all 5 task states (fixation, first step, re-fixation, second step, re-fixation with final reward), and calculated action values at each state according to the equation: 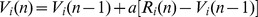 where Vi(n) is the subjective value of action i after the nth time that action was selected, and α represents the learning rate. R is an internal estimate of the experienced reinforcement, specified by:
where Vi(n) is the subjective value of action i after the nth time that action was selected, and α represents the learning rate. R is an internal estimate of the experienced reinforcement, specified by: 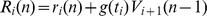 where r is the actual reward magnitude given at stage i, g is the hyperbolic temporal discounting function [7], and
where r is the actual reward magnitude given at stage i, g is the hyperbolic temporal discounting function [7], and 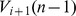 is the value of the next state before it is updated. Action selection was made using a ‘soft-max’ function, with a temperature parameter that introduced stochasticity in the monkeys’ choices. We did not fit the model to the data, but chose the model parameters so as to roughly replicate the monkeys’ behavioral pattern. However, we stress that the specific choice of the model parameters (learning rates, temporal discount and temperature) does not affect our argument, because all the parameters affect learning at both steps and produce the same qualitative pattern of results. This computational framework does not contain task-dependent learning control and thus by definition cannot produce state-specific learning allocation.
is the value of the next state before it is updated. Action selection was made using a ‘soft-max’ function, with a temperature parameter that introduced stochasticity in the monkeys’ choices. We did not fit the model to the data, but chose the model parameters so as to roughly replicate the monkeys’ behavioral pattern. However, we stress that the specific choice of the model parameters (learning rates, temporal discount and temperature) does not affect our argument, because all the parameters affect learning at both steps and produce the same qualitative pattern of results. This computational framework does not contain task-dependent learning control and thus by definition cannot produce state-specific learning allocation.