
Figure 3.
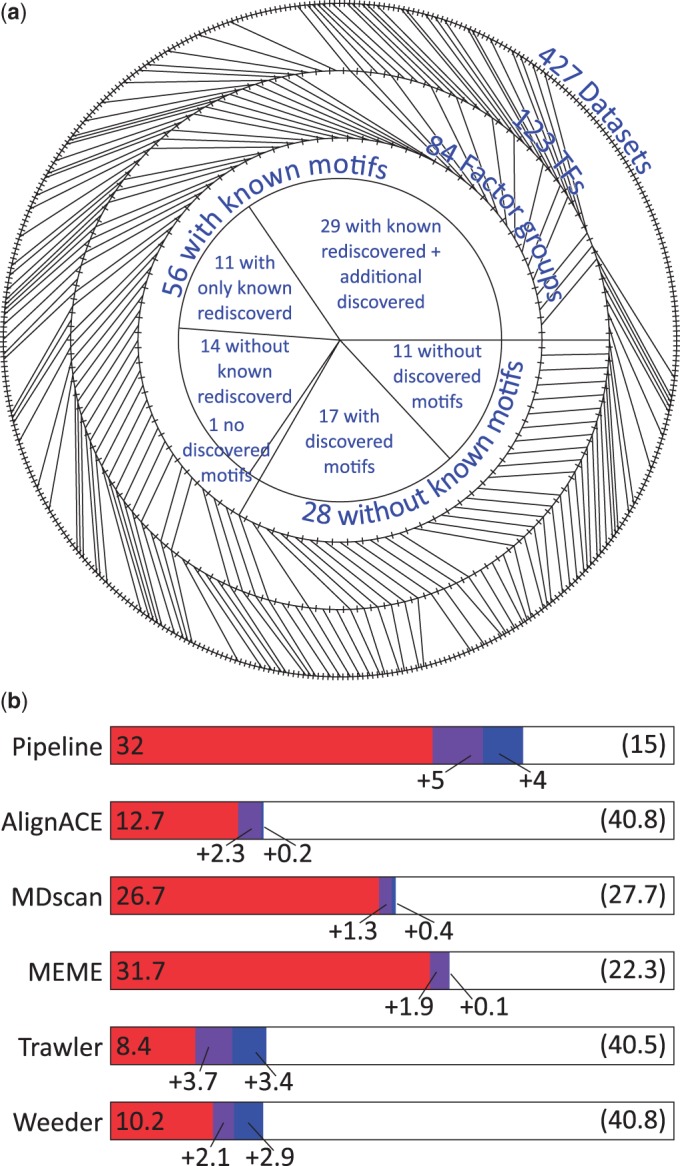
(a) Summary of input data used. The outside ring indicates the experimental data sets (one tick for each of 427), which are separated into 123 transcription factors (second ring). The TFs are further grouped into 84 factor groups (third ring). We are able to find a matching discovered motif for 41 of the 56 factor groups with a known motif; 29 of these 41 factor groups have additional discovered motifs that may be associated with cofactors. For all but 1 of the 15 factor groups where the known motif is not recovered we still find enriched discovered motifs. We also discovered enriched motifs for 17 of the 28 factor groups without a known motif. (b) Recovery of known motifs by each of the discovery tools. Performance of discovery in terms of number of factor groups for which the known motif was recovered. A motif is considered a match if it matches any of the known motifs for a factor group (see Supplementary Methods for details on how matches are computed). The number of additional factors that have a match is shown with each additional motif (only three motifs are taken from each individual method, whereas we have up to 10 for the pipeline). The number of factor groups with no motif match is shown in parenthesis. When multiple data sets exist for a factor group, the fraction that matches is used in computing its contribution for computing the performance of the individual tools.