
Figure 5.
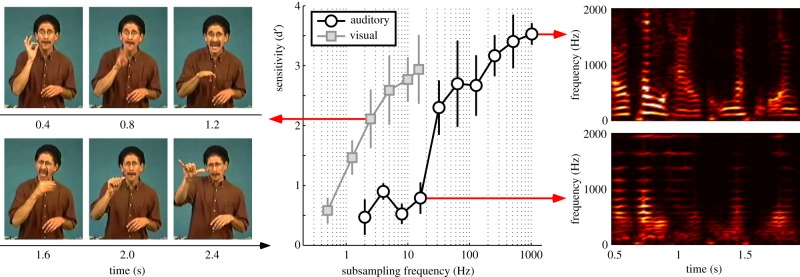
Auditory and visual vulnerability to input stream subsampling. The same participants (n = 4) watched and listened to sequences of 3 s long video and audio snippets (respectively) in different blocks while performing a two-back task (responding to a repeat of the penultimate snippet). Video snippets depicted an actor reading a children's book in American sign language, whereas audio snippets were recordings of a speaker reading an English literary classic. In each block, all snippets were temporally subsampled to the same frequency. A 2 s long excerpt from a video snippet at 2.5 frames per second is illustrated on the left, and the spectrograms of a single 2 s long excerpt from an audio stream subsampled at 1024 Hz (top) and 16 Hz (bottom) are shown on the right. The corresponding video/sound files can be downloaded from http://www.cerco.ups-tlse.fr/~rufin/audiovisual/. The two-back recognition task performance is expressed in terms of sensitivity (d‘, corresponding to the z-scored difference between hit rates—correctly detecting a two-back repeat—and false alarm rates—incorrectly reporting a two-back repeat). It is an order of magnitude more robust to temporal subsampling for vision than for audition. Error bars represent standard error of the mean across subjects. (Online version in colour.)