
Figure 5.
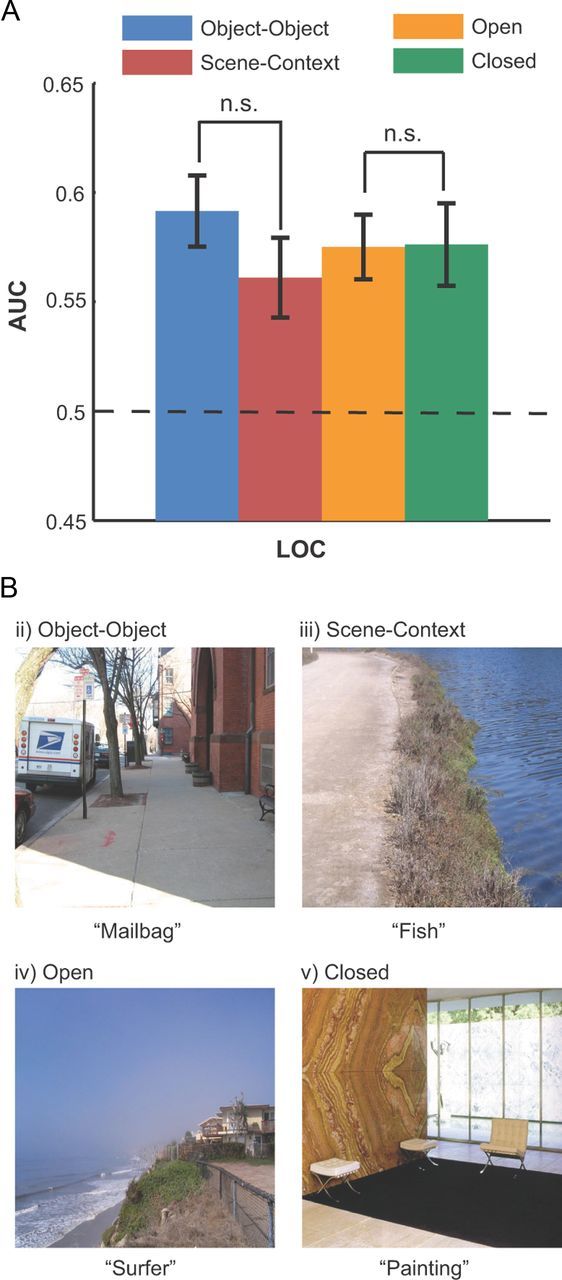
A, MVPA performance (AUC) predicting the contextual location of subsets of images containing contextual information based on scene context or object–object co-occurrence, or images with open or closed scenes (B). Images were classified based on the majority opinion of 10 raters. There is no significant difference between the subcategories' AUC (p > 0.5; FDR corrected). Error bars indicate SEM.