
Figure 2.
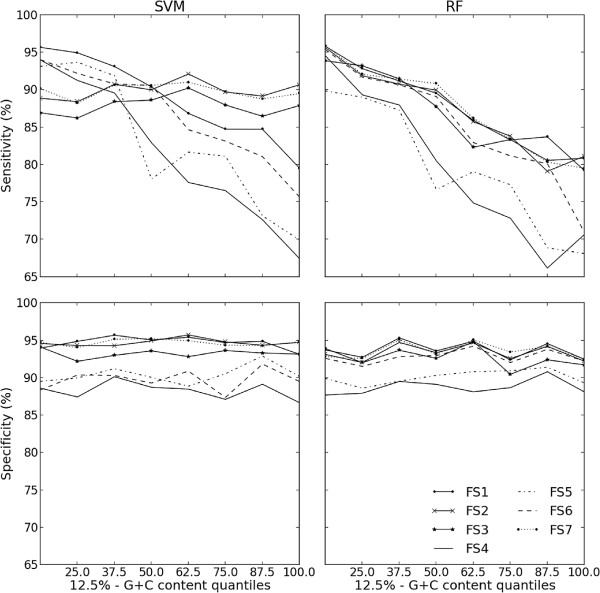
Predictive performance of classifiers throughout 12.5%-quantile distribution of G+C content. The prediction of the secondary structure of G+C-rich sequences is more challenging. This figure shows that the classification of G+C-rich pre-miRNA sequences is also more complex. As the G+C content increased, the sensitivity dropped, except when SVM was trained with feature sets including %G+C-based features (FS1, FS2 and FS7).