
Figure 4.
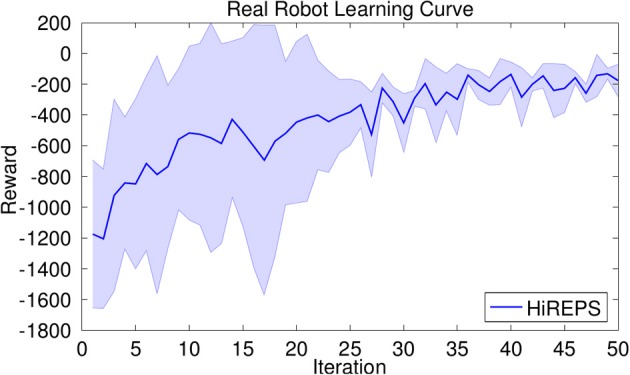
Average rewards for learning tetherball on the real robot. Mean and standard deviation of three trials. In all of the three trials, after 50 iterations the robot has found solutions to wind the ball around the pole on either side.
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
Average rewards for learning tetherball on the real robot. Mean and standard deviation of three trials. In all of the three trials, after 50 iterations the robot has found solutions to wind the ball around the pole on either side.