
Figure 3.
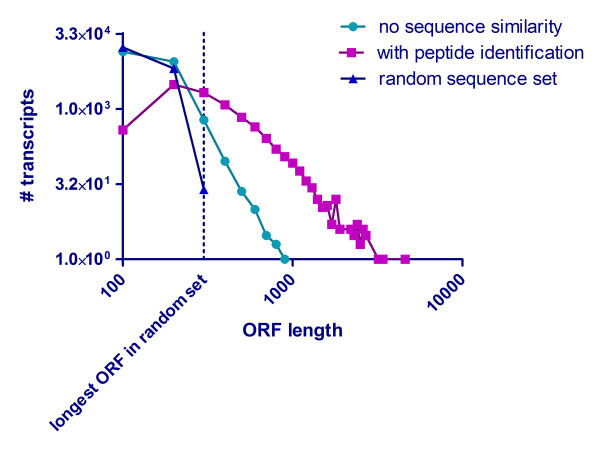
Estimation of coding potential in non-annotated transcripts. ORF coding potential in a randomly generated transcript set, verified transcripts without sequence annotation, and sequences with high quality annotations. All three transcript sets containing sequences longer than 400 bp were translated in six reading frames. The longest ORF per transcript was plotted against the number of transcripts per dataset. Note that a significant number of ORFs from the dataset without annotation (cyan line) exceeds the maximum ORF length of the randomly generated transcript. The non-annotated group contains an identical number of total transcripts with identical sequence length (blue line), indicating the existence of potential newt proteins that were not identified by proteomics.