
Fig. 1.
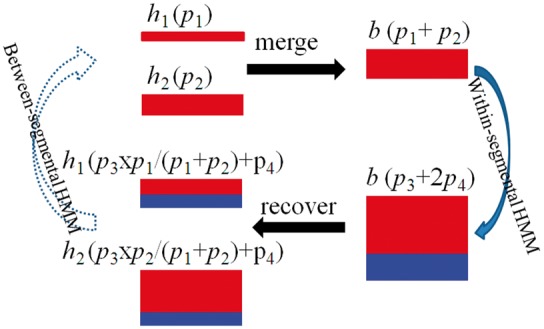
Illustration of the MAR algorithm. Two haplotypes are presented for simplicity. They are of same type and are merged into one block b. Initially the two haplotypes have the probability p1 and p2. Initial block probability is the sum of the two haplotype probabilities p1 + p2. Within-segmental HMMs are performed on the block. Block probability is partitioned into two components p3 and 2p4. The contribution of each haplotype in p3 is proportional to its initial probability, and the contribution in p4 is equal. At the end of the segment, the two haplotype probabilities are recovered with p3 and p4. Between-segmental HMM is then performed on individual haplotypes