
Figure 3. Model comparison using likelihood gain over the independent model.
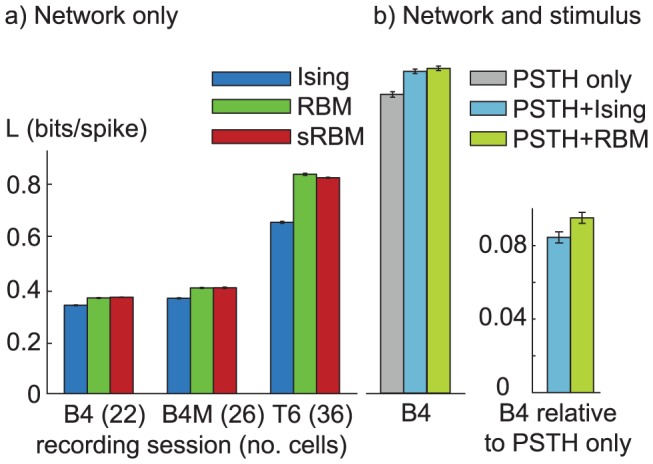
Likelihoods are normalized to bits/spike to account for different population size as well as firing rate. (a) The change in performance with dataset size (22 cells for session B4, 26 cells for MU, and 36 cells for T6) is thus due to additional structure captured from larger populations. B4 and T6 are spike sorted, B4M is a multiunit dataset. All three models outperform the independent model by 0.4–0.8 bits/spike. The higher-order models with hidden units give a small (0.03–0.04 bits/spike, about 10%) improvement over the Ising model for the small datasets, growing to 0.18 bits/spike, about 28%, for the dataset with the large population size. (b) Including stimulus terms provides a large gain in likelihood, even the stimulus PSTH term alone outperforms the network models by a large margin for this dataset. There is still a significant gain by including coupling terms. The difference between the second order Ising model and higher-order RBM is particularly visible in the right hand plot which shows the gain relative to the PSTH only model. All error bars indicate one standard deviation over repeated estimation on different random subsets of the data for training and validation and random initializations of AIS estimation.