
Fig. 3.
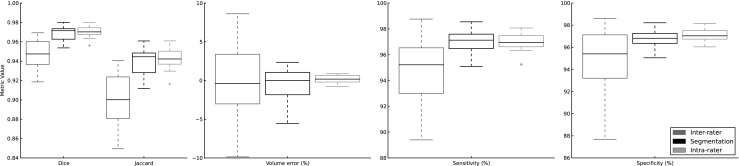
Metrics comparing interobserver variability (left, dark gray), our algorithm (middle, black), and intraobserver variability (right, light gray). For each metric except volume, the performance of our segmentation is significantly better than interobserver variability (p < 0.01) and not significantly different from intraobserver variability (p > 0.2). Considering volume, our segmentation was not significantly different from either intraobserver (p = 0.39) or interobserver (p = 0.88) variability by paired t tests