
Table 2. Single-trial classification accuracy [%], based on 8-fold cross validation for each paradigm and subject.
| Subject | RC | RASP | RASP-F | |
| NSF | SF | |||
| 1 | 93.7 | 88.8 | 86.8 | 90.6 |
| 2 | 96.1 | 96.6 | 98.0 | 98.6 |
| 3 | 90.8 | 89.6 | 91.8 | 94.8 |
| 4 | 79.1 | 76.5 | 81.6 | 85.2 |
| 5 | 89.8 | 89.3 | 88.8 | 91.9 |
| 6 | 89.2 | 82.8 | 91.7 | 94.3 |
| 7 | 88.3 | 86.1 | 81.9 | 89.9 |
| 8 | 87.4 | 87.3 | 90.1 | 90.4 |
| 9 | 90.1 | 82.2 | 91.7 | 97.7 |
| 10 | 80.1 | 89.0 | 92.8 | 95.2 |
| 11 | 89.8 | 93.4 | 96.4 | 97.4 |
| 12 | 76.0 | 87.1 | 85.8 | 92.6 |
| 13 | 85.4 | 87.6 | 95.2 | 95.8 |
| 14 | 90.8 | 89.9 | 96.9 | 97.9 |
| 15 | 79.2 | 79.6 | 91.9 | 93.4 |
| Mean | 87.1 | 87.1 | 90.7 | 93.7*** |
RC stands for Row Column, RASP for random set presentation, RASP-F for random set presentation with face stimuli, NSF stands for non-self face stimuli, while SF stands for self-face stimuli. The three stars indicates the level of significant improvement (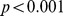 ) for NSF vs. SF., based on a sign test with the hypothesis of equal means.
) for NSF vs. SF., based on a sign test with the hypothesis of equal means.