
Figure 8.
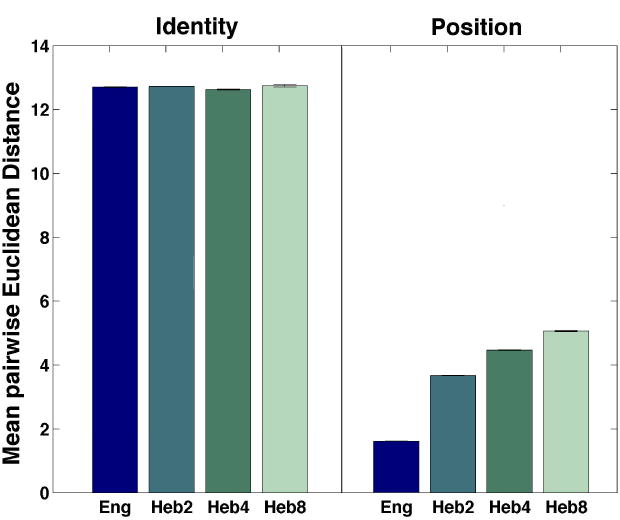
Mean Euclidean distances between pairs of hidden representations of non-words differing from each other by letter position or letter identity in Simulation 2a. ‘Eng’: English; ‘Heb’: Hebrew. The number besides the label ‘Heb’ refers to the number of anagrams per letter string in the Hebrew-like condition. The error bars represent the standard error of the mean across the two runs of the simulation. Some error bars are too tiny to be identifiable.