

Abstract
Providers of cloud environments must tackle the challenge of configuring their system to provide maximal performance while minimizing the cost of resources used. However, at the same time, they must guarantee an SLA (service-level agreement) to the users. The SLA is usually associated with a certain level of QoS (quality of service). As response time is perhaps the most widely used QoS metric, it was also the one chosen in this work. This paper presents a green strategy (GS) model for heterogeneous cloud systems. We provide a solution for heterogeneous job-communicating tasks and heterogeneous VMs that make up the nodes of the cloud. In addition to guaranteeing the SLA, the main goal is to optimize energy savings. The solution results in an equation that must be solved by a solver with nonlinear capabilities. The results obtained from modelling the policies to be executed by a solver demonstrate the applicability of our proposal for saving energy and guaranteeing the SLA.
1. Introduction
In cloud computing, SLA (service-level agreement) is an agreement between a service provider and a consumer where the former agrees to deliver a service to the latter under specific terms, such as time or performance. In order to comply with the SLA, the service provider must monitor the cloud performance closely. Studying and determining SLA-related issues are a big challenge [1, 2].
GS is designed to lower power consumption [3] as much as possible. The main objective of this paper is to develop resource scheduling approaches to improve the power efficiency of data centers by shutting down and putting idles servers to sleep, as Intel's Cloud Computing 2015 Vision [4] does.
At the same time, GS is aimed at guaranteeing a negotiated SLA and power-aware [3] solutions, leaving aside such other cloud-computing issues as variability [2], system security [3], and availability [5]. Job response time is perhaps the most important QoS metric in a cloud-computing context [1]. That is also why the QoS parameter is chosen in this work. In addition, despite good solutions having been presented by some researchers in the literature dealing with QoS [6, 7] and power consumption [8, 9], the model presented aims to obtain the best scheduling, taking both criteria into account.
This paper is focused on proposing a static green alternative to solving the scheduling problem in cloud environments. Many of the cited solutions consist of creating dynamically ad hoc VMs, depending on the workload, made up of independent tasks or a parallel job composed of communicating or noncommunicating tasks. This implies constantly creating, deleting, or moving VMs. These processes consume large amounts of time. Low ratios for return times and VM management should lead to proposing more static scheduling methods between the existing VMs. The solution described in this paper goes on this direction. However, this solution can be merged and complemented with dynamic proposals.
Our additional contribution with respect to [10] is that our solution tries to optimize 2 criteria at the same time: scheduling tasks to VMs, saving energy, and consolidating VMs to the nodes. Providing an efficient NLP solution for this problem is a novelty challenge in the cloud computing research field.
Another important contribution of this paper is method used to model the power of the virtual machines in function of their workload. Relying on the work done in [11], where the authors formulate the problem of assigning people from various groups to different jobs and who may complete them in the minimum time as a stochastic programming problem, the job completion times were assumed to follow a Gamma distribution. To model the influence of the workload, the computing power of the virtual machine is weighted by a load factor determined by an Erlang distribution (equivalent to a Gamma). Finally, a stochastic programming problem is obtained and transformed into an equivalent deterministic problem with a nonlinear objective function.
The remainder of the paper is organized as follows. Our contribution is based on the previous work presented in Section 2. In the GS section (Section 3), we present our main contributions, a sort of scheduling policy. These proposals are arranged by increasing complexity. The experimentation showing the good behavior of our cloud model is presented in the Results section (Section 4). Finally, the Conclusions and Future Work section outlines the main conclusions and possible research lines to explore in the near future.
2. Related Work
There is a great deal of work in the literature on linear programming (LP) solutions and algorithms applied to scheduling, like those presented in [12, 13]. Another notable work was performed in [14], where authors designed a Green Scheduling Algorithm that integrated a neural network predictor in order to optimize server power consumption in cloud computing. Also, the authors in [15] proposed a genetic algorithm that takes into account both makespan and energy consumption.
Shutting down servers when they are not being used is one of the most direct methods to reduce the idle power. However, the authors in [16] state that a power-off requires an additional setup cost, resulting in long system delays. Shutting down servers may sacrifice quality of service (QoS) levels, thus violating the SLA. They put the server work at a lower service rate rather than completely stopping work during idle periods. This drawback can be reduced if scheduling is performed for a large enough number of tasks, as in our case.
In [17], the authors treat the problem of consolidating VMs in a server by migrating VMs with steady and stable capacity needs. They proposed an exact formulation based on a linear program described by too small a number of valid inequalities. Indeed, this description does not allow solving, in a reasonable time or an optimal way, problems involving the allocation of a large number of items (or VMs) to many bins (or servers).
In [18], the authors presented a server consolidation (Sercon) algorithm which consists of minimizing the number of used nodes in a data center and minimizing the number of migrations at the same time to solve the bin (or server) packing problem. They show the efficiency of Sercon for consolidating VMs and minimizing migrations. Despite our proposal (based on NLP) always finding the best solution, Sercon is a heuristic that cannot always reach or find the optimal solution.
The authors in [19] investigated resource optimization, service quality, and energy saving by the use of a neural network. These actions were specified in two different resource managers, which sought to maintain the application's quality service in accordance with the SLA and obtain energy savings in a virtual servers' cluster by turning them off when idle and dynamically redistributing the VMs using live migration. Saving energy is only applied in the fuzzy-term “intermediate load,” using fewer resources and still maintaining satisfactory service quality levels. Large neural network training times and their nonoptimal solutions could be problems that can be overcome by using other optimization techniques, such as the NLP one used in this paper.
In [10], the authors modelled an energy aware allocation and consolidation policies to minimize overall energy consumption with an optimal allocation and a consolidation algorithm. The optimal allocation algorithm is solved as a bin-packing problem with a minimum power consumption objective. The consolidation algorithm is derived from a linear and integer formulation of VM migration to adapt to placement when resources are released.
The authors of [20] presented an effective load-balancing genetic algorithm that spreads the multimedia service task load to the servers with the minimal cost for transmitting multimedia data between server clusters and clients for centralized hierarchical cloud-based multimedia systems. Clients can change their locations, and each server cluster only handled a specific type of multimedia task so that two performance objectives (as we do) were optimized at the same time.
In [21], the authors presented an architecture able to balance load into different virtual machines meanwhile providing SLA guarantees. The model presented in that work is similar to the model presented in this paper. The main difference is in the tasks considered. Now, a more complex and generalized model is presented. In addition, communicating and heterogeneous tasks as well as nondedicated environments have been taken into account.
Our proposal goes further than the outlined literature. Instead of designing a single criteria scheduling problem (LP), we design an NLP scheduling solution which takes into account multicriteria issues. In contrast to the optimization techniques of the literature, our model ensures the best solution available. We also want to emphasize the nondedicated feature of the model, meaning that the workload of the cloud is also considered. This also differentiates from the related work. This consideration also brings the model into reality, providing more reliable and realistic results.
3. GS Model
The NLP scheduling solution proposed in this paper models a problem by giving an objective function (OF). The equation representing the objective function takes various performance criteria into account.
GS tries to assign as many tasks as possible to the most powerful VMs, leaving the remaining ones aside. As we will consider clouds made up of various nodes, at the end of the scheduling process, the nodes all of whose VMs are not assigned any task can then be turned off. As SLA based on the minimization of the return time is also applied, the model also minimizes the computing and communication time of the overall tasks making up a job.
3.1. General Notation
Let a job made up of T communicating tasks (t i, i = 1,…, T), and a cloud made up of N heterogeneous nodes (Node1,…, NodeN).
The number of VMs can be different between nodes, so we use notation v n (v n = 1,…, V n, where n = 1,…, N) to represent the number of VMs located to Noden. In other words, each Noden will be made up by VMs VMn1,…, VMnVn.
Task assignments must show the node and the VM inside the nodes task t i is assigned to. In doing so, Boolean variables will also be used. The notation t nvn i is used to represent the assignment of task t i to Noden VM VMnvn.
The notation M nvn i represents the amount of Memory allocated to task t i in VM VMnvn. It is assumed that Memory requirements do not change between VMs, so M nvn i = M nvn′ i ∀n ≤ N, and v n, v n′ ≤ V n. The Boolean variable t nvn i represents the assignment of task t i to VMnvn. Once the solver is executed, the t nvn i variables will inform about the assignment of tasks to VMs. This is t nvn i = 1 if t i is assigned to VMnvn, and t nvn i = 0 otherwise.
3.2. Virtual Machine Heterogeneity
The relative computing power (Δnvn) of a VMnvn is defined as the normalized score of such a VM. Formally, consider
| (1) |
where ∑i=1 V∑k=1 ViΔivk = 1. δ nvn is the score (i.e., the computing power) of VMnvn. Although δ nvn is a theoretical concept, there are many valid benchmarks it can be obtained with (i.e., Linpack (Linpack. http://www.netlib.org/linpack/) or SPEC (SPEC. http://www.spec.org)). Linpack (available in C, Fortran and Java), for example, is used to obtain the number of floating-point operations per second. Note that the closer the relative computing power is to one (in other words, the more powerful it is), the more likely it is that the requests will be mapped into such a VM.
3.3. Task Heterogeneity
In order to model task heterogeneity, each task t i has its processing cost P nvn i, representing the execution time of task t i in VMnvn with respect to the execution time of task t i in the least powerful VMnvn (in other words, with the lowest Δnvn). It should be a good choice to maximize t nvn i P nvn i to obtain the best assignment (in other words, the OF) as follows:
| (2) |
However, there are still a few criteria to consider.
3.4. Virtual Machine Workload
The performance drop experienced by VMs due to workload saturation is also taken into account. If a VM is underloaded, its throughput (tasks solved per unit of time) will increase as more tasks are assigned to it. When the VM reaches its maximum workload capacity, its throughput starts falling asymptotically towards zero. This behavior can be modeled with an Erlang distribution density function. Erlang is a continuous probability distribution with two parameters, α and λ. The α parameter is called the shape parameter, and the λ parameter is called the rate parameter. These parameters depend on the VM characteristics. When α equals 1, the distribution simplifies to the exponential distribution. The Erlang probability density function is
| (3) |
We consider that the Erlang modelling parameters of each VM can easily be obtained empirically. The Erlang parameters can be obtained by means of a comprehensive analysis of all typical workloads being executed in the server, supercomputer, or data center to be evaluated. In the present work, a common PC server was used. To carry out this analysis, we continuously increased the workload until the server was saturated. We collected measurements about the mean response times at each workload variation. By empirical analysis of that experimentation, we obtained the Erlang that better fitted the obtained behaviour measurements.
The Erlang is used to weight the Relative computing power Δnvn of each VMnvn with its associated workload factor determined by an Erlang distribution. This optimal workload model is used to obtain the maximum throughput performance (number of task executed per unit of time) of each VMnvn. In the case presented in this paper, the x-axis (abscisas) represents the sum of the Processing cost P nvn i of each t i assigned to every VMnvn.
Figure 1 shows an example in which we depict an Erlang with α = 76 and λ = 15. The Erlang reaches its maximum when X = 5. Provided that the abscissas represent the workload of a VM, a workload of 5 will give the maximum performance to such a VM in terms of throughput. So we are not interested in assigning less or more workload to a specific VMnvn because otherwise, this would lead us away from the optimal assignment.
Figure 1.
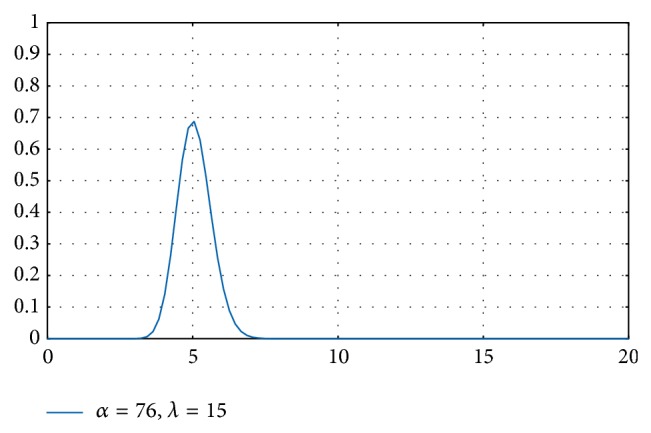
Erlang plots for different α and λ values.
Given an Erlang distribution function with fixed parameters α and λ, it is possible to calculate the optimal workload in which the function reaches the maximum by using its derivative function:
| (4) |
Accordingly, the optimal workload of the Erlang example in Figure 1, with α = 76 and λ = 15, is
| (5) |
Finally, in our case, provided that the VM workload, defined as the sum of the processing costs (P nvn i) of the tasks assigned to a particular VM, must be an N number, the optimal workload (x) is
| (6) |
Provided that Boolean variable t nvn i = 1 is a boolean variable informing of the assignment of t i to VMnvn, and t nvn i = 0 if not, the Erlang-weighted Δnvn would be
| (7) |
3.5. Task Communication and VM Selection
In this section, the VM selection is also considered. In doing so, each VM can be selected from a range of N nodes, forming a federated cloud. We want to obtain an OF that considers the scheduling of heterogeneous and communicating tasks to N heterogeneous nodes made up of different numbers of heterogeneous VMs.
The communication cost (in time) between tasks t i and t j when in the same VM is denoted by C ij and should be passed to the solver as an argument. For reasons of simplicity, all communication links are considered to have the same bandwidth and latency. Notation C nvn ij represents the communication cost between task t i residing in VMnvn with another task t j (located in the same VM or elsewhere). Provided equivalent bandwidth between any two VMs, C nvn ij = C nvn′ ji ∀v, v′ ≤ V. In other words, the communication cost does not depend on the VM or the links used between the VMs.
VM communication links are considered with the same bandwidth capacity. Depending on its location, we multiply the communication cost between tasks t i and t j by a given communication slowdown. If t i and t j are located in the same VM, the communication slowdown (denoted by Csnvn) is 1. If t j is assigned to another VM in the same node than t i (, the Communication slowdown () will be in the range [0,…, 1]. Finally, if t j is assigned to another VM located in another node (), the corresponding communication slowdown term () will also be in the range [0,…, 1]. and should be obtained with respect to Csnvn. In other words, and are the respective reduction (in percentage) in task communication between VMs located in the same and different nodes compared with task communication inside the same VM. To sum up, .
According to task communication, the idea is to add a component in the OF that penalizes (enhances) the communications performed between different VMs and different nodes. Grouping tasks inside the same VM will depend on not only their respective processing cost (P nvn i) but also the communication costs C nvn ij and communication slowdowns Csnvn, , and . We reward the communications done in the same VM but less so the ones done in different VMs while still in the same node. Finally, communications between nodes are left untouched, without rewarding or penalizing.
In the same way, if we modelled the OF in function of the tak heterogeneity in (2), the communication component will be as follows (only the communication component of the OF is shown):
| (8) |
And the OF function will be
| (9) |
3.6. Choosing SLA or Energy Saving
It is important to highlight that the optimization goal is two criteria (SLA and energy in our case). Thus, the user could prioritize the criteria. Assignments are performed starting from the most powerful VM. When this becomes saturated, task assignment continues with the next most powerful VM, regardless of the node it resides in. When this VM resides in another node (as in our case), the energy-saving criteria will be harmed. It would be interesting to provide a means of increasing criteria preferences in the model presented.
In order to highlight specific criteria (i.e., energy saving), one more additional component must be added to the OF. This component must enhance the assignment of tasks to the same node by assigning tasks to the most powerful nodes and not only to the most powerful VMs as before. This is the natural procedure to follow, because the OF is a maximum. Thus, the likelihood of less powerful nodes becoming idle increases and this gives the opportunity to power them off, hence saving energy.
The additional component can be defined in a similar way as for the relative VM computing power (Δnvn) of a VMnvn. Instead, we obtain the relative node computing power of a Noden (Θn) as the normalized summatory of their forming VMs. Θn will inform about the computing power of Noden.
For N nodes, Θn is formally defined as
| (10) |
where ∑n=1 NΘn = 1. To obtain Θn, the parallel Linpack version (HPL: high performance Linpack) can be used. It is the one used to benchmark and rank supercomputers for the TOP500 list.
Depending on the importance of the energy saving criteria, a weighting factor should be provided to Θn. We simply call this factor energy Energy Ξ. The Ξ will be in the range (0,…, 1]. For an Ξ0, our main criteria will be energy saving, and for Ξ = 1, our goal is only SLA. Thus, the resulting energy component will be ΘnΞ. Thus, for a given Noden with Θn, we must weigh the energy saving criteria of such a node by the following factor:
| (11) |
The resulting OF function will be
| (12) |
3.7. Enforcing SLA
For either prioritized criteria, SLA or energy saving, there is a last consideration to be taken into account.
Imagine the case where tasks do not communicate. Once they are assigned to a node, one would expect them to be executed in the minimum time. In this case, there is already no need to group tasks in the VM in decreasing order of power in the same node, because this node is no longer eligible to be switched off. A better solution in this case would be to balance the tasks between the VMs of such a node in order to increase SLA performance. Note that this not apply in the communicating tasks due to the communication slowdown between VMs.
To implement this, we only need to assign every noncommunicating tasks without taking the relative computing power (Δnvn) of each VM into account.
We only need to replace Δnvn in (12) by Δ, defined as
| (13) |
For the case of noncommunicating tasks, by assigning a Δ = 1, all the VMs have the same relative computing power Δnvn. Thus, tasks are assigned in a balanced way.
3.8. Model Formulation
Finally, the OF function and their constraints are presented. The best task scheduling assignment to VMs which takes all the features into account (GS policy) is formally defined by the following nonlinear programming model:
| (14a) |
| (14b) |
| (14c) |
Equation (14a) is the objective function (OF) to be maximized. Note that OF is an integer and nonlinear problem. Inequality in (14b) and equality in (14c) are the constraints of the objective function variables. Given the constants T (the total number of requests or tasks), and M v for each VMnvn, the solution that maximizes OF will obtain the values of the variables t nvn i, representing the number of tasks assigned to VMnvn. Thus, the t nvni obtained will be the assignment found by this model.
OF takes into account the processing costs (P nvn i) and the communication times (C nvn ij) of the tasks assigned to each VMnvn and the communication slowdowns between VMs and nodes . Csnvn = 1. Δ is defined in Section 3.7. And E(∑j=1 T t nvn j P nvn j; α, λ) represents the power slowdown of each VM due to its workload (defined in Section 3.4).
To sum up, for the case when the workload is made up of noncommunicating tasks, if we are interested in prioritizing the SLA criteria, OF 3.5 should be applied. If, on the contrary, the goal is to prioritize energy saving, OF (14a) should be used instead.
4. Results
In this section, we present the theoretical results obtained from solving the scheduling problems aimed at achieving best task assignment. Two representative experiments were performed in order to test the performance of GS.
The experiments were performed by using the AMPL (AMPL. A Mathematical Programming Language. http://ampl.com) language and the SCIP (SCIP. Solving Constraint Integer Programs. http://scip.zib.de) solver. AMPL is an algebraic modeling language for describing and solving high-complexity problems for large-scale mathematical computation supported by many solvers. Integer and nonlinear (our model type) problems can be solved by SCIP, one of the solvers supported by AMPL.
Throughout all the experimentation, the Erlang arguments were obtained empirically by using the strategy explained in Section 3.4.
As the objective of this section is to prove the correctness of the policy, only a small set of tasks, VMs, and nodes was chosen. The size of the experimental framework was chosen to be as much representative of actual cases as possible, but at the same time, simple enough to be used as an illustrative example. So, the experimental framework chosen was made up of 2 different nodes: one of them comprised 3 VMs and the other 1 VM; see Figure 2. The objective of this simulation was to achieve the best assignment for 3 tasks. Table 1 shows the processing cost P nvn i, relating the execution times of the tasks in each VM. To show the good behavior of the model presented, each task has the same processing cost independently of the VM. The model presented can be efficiently applied to real cloud environments. The only weak point is that the model is static. That means that homogenous and static workload conditions must be stable in our model. Job executions in different workload sizes can be saved in a database system, providing a means for determining the SLA of such a job in future executions.
Figure 2.
Cloud architecture.
Table 1.
Task processing costs.
| Task t i | Processing costs P nvn i | Value |
|---|---|---|
| t 1 | P 11 1, P 12 1, P 13 1, P 21 1 | 1 |
| t 2 | P 1 2, P 12 2, P 13 2, P 21 2 | 5 |
| t 3 | P 11 3, P 12 3, P 13 3, P 21 3 | 1 |
|
| ||
| Total processing cost (∑iP nvn i) | 7 | |
4.1. Without Communications
In this section, a hypothetical situation without communication between tasks is evaluated. In this situation, our scheduling policy tends to assign the tasks to the most powerful set of virtual machines (i.e., with the higher relative computing power Δnvn, considering their individual saturation in this choice). This saturation becomes critical when more and more tasks are added. Here, the most important term is the Erlang function, since it models the behaviour of every virtual machine. Thus, taking this into account, our scheduler knows the exact weight of tasks it can assign to the VMs in order to obtain the best return times. This phenomenon is observed in the following examples.
4.1.1. Without Communications and High Optimal Erlang
Table 2 shows the parameters used in the first example. The amount of Memory allocated to each task t i in every VM M nvn (as we supposed this amount to be equal in all the VMs, we simply call it M i). The relative computing power (Δnvv) of each VM and finally the α and λ Erlang arguments. Note that all the VMs have the same Erlang parameters. The parameters were chosen this way because any VM saturates with the overall workload assigned. In other words, the total processing cost 7 is lower than the optimal Erlang workload 16.
Table 2.
Without communications. High optimal Erlang. VM configurations.
| Node | VMnvn | M i | Δnvv | Erlang |
|---|---|---|---|---|
| 1 | VM11 | 10 | 0.75 | α = 3, λ = 8 |
| 1 | VM12 | 10 | 0.35 | α = 3, λ = 8 |
| 1 | VM13 | 10 | 0.1 | α = 3, λ = 8 |
| 2 | VM21 | 10 | 0.85 | α = 3, λ = 8 |
Table 3 shows the solver assignment results. The best scheduling assigns all the tasks to the same VM (VM21, the only VM in node 2), because this VM has the biggest relative computing power (Δnvv). This result is very coherent. Due to the lack of communications, the model tends to assign tasks to the most powerful VM while its workload does not exceed the Erlang optimum (a workload of 10 tasks). As in our case, the total workload is 7, and VM21 could host even more tasks.
Table 3.
Without communications. High optimal Erlang. Solver assignment.
| Node | VMnvn | Task assignment |
|---|---|---|
| 1 | VM11 | 0 |
| 1 | VM12 | 0 |
| 1 | VM13 | 0 |
| 2 | VM21 | t 1, t 2, t 3 |
4.1.2. Without Communications, Low Optimal Erlang, and Preserving SLA
In this example (see Table 4), the VMs have another Erlang. However, the task processing costs do not change, so they remain the same as in Table 1. In this case, each VM becomes saturated when the assignment workload weight is higher than 5 (because 5 is the optimal workload).
Table 4.
Without communications. Low optimal Erlang. Preserving SLA. VM configurations.
| Node | VMnvn | M i | Δnvv | Erlang |
|---|---|---|---|---|
| 1 | VM11 | 10 | 0.75 | α = 5, λ = 1 |
| 1 | VM12 | 10 | 0.35 | α = 5, λ = 1 |
| 1 | VM13 | 10 | 0.1 | α = 5, λ = 1 |
| 2 | VM21 | 10 | 0.85 | α = 5, λ = 1 |
The best assignment in this case is the one formed by the minimum set of VMs with the best relative computing power Δnvv (see Table 5 column Task Assignment SLA). The assignment of the overall tasks to only one VM (although it was the most powerful one) as before will decrease the return time excessively, due to its saturation.
Table 5.
Without communications. Low optimal Erlang. Preserving SLA. Solver assignment.
| Node | VMnvn | SLA | Energy |
|---|---|---|---|
| Task assignment | Task assignment | ||
| 1 | VM11 | t 1, t 3 | t 2 |
| 1 | VM12 | 0 | t 1, t 3 |
| 1 | VM13 | 0 | 0 |
| 2 | VM21 | t 2 | 0 |
4.1.3. Without Communications, Low Optimal Erlang, and Preserving Energy Saving
Provided that the most important criterion is the energy saving, the assignment will be somewhat different (see Table 5, column Task Assignment Energy). In this case, OF (14a) with Ξ = 1 was used. Then, as expected, all the tasks were again assigned to VM21 of Node2.
4.2. With Communications
Starting from the same VM configuration shown on Table 4, in this section we present a more real situation where the costs of communications between tasks are also taken into account. It is important to highlight that in some situations, the best choice does not include the most powerful VMs (i.e., with the highest relative computing power Δnvn). Thus, the results shown in this section must show the tradeoff between relative computing power of VM, workload scheduling impact modeled by the Erlang distribution, and communication efficiency between tasks.
4.2.1. High Communication Slowdown
This example shows the behaviour of the model under large communication costs between VMs (see Table 6). This table shows the communication costs between tasks (C ij) and the communication slowdown when communications are done between VMs in the same node () and the penalty cost when communications are performed between different nodes (). Note that the penalties are very high (0.2 and 0.1) when the communications are very influential.
Table 6.
High slowdown. Communication configurations.
| Task t i | Task t j | Communication costs C ij |
|---|---|---|
| t 1 | t 2 | 0.2 |
| t 1 | t 3 | 0.6 |
| t 2 | t 3 | 0.3 |
| 0.2 | ||
| 0.1 | ||
The solver assignment is shown in Table 7. In order to avoid communication costs due to slowdowns, the best assignment tends to group tasks first in the same VM and second in the same node. Although VM21 should become saturated with this assignment, the high communication cost compensates the loss of SLA performance, allowing us to switch off node 1.
Table 7.
High slowdown. Solver assignment.
| Node | VMnvn | Task assignment |
|---|---|---|
| 1 | VM11 | 0 |
| 1 | VM12 | 0 |
| 1 | VM13 | 0 |
| 2 | VM21 | t 1, t 2, t 3 |
4.2.2. Low Communication Slowdown
Now, this example shows the behaviour of our policy under more normal communication conditions. Here, the communication penalties between the different VMs or nodes are not as significant as in the previous case because and are higher. Table 8 shows the communication costs between tasks and the penalty cost if communications are performed between VMs in the same node () or between different nodes ().
Table 8.
Low slowdown. Communication configurations.
| Task ti | Task tj | Communication costs Cij |
|---|---|---|
| t 1 | t 2 | 0.2 |
| t 1 | t 3 | 0.6 |
| t 2 | t 3 | 0.3 |
| 0.9 | ||
| 0.8 | ||
In this case, the solver got as a result two hosting VMs (see Table 9) formed by the VM11 (with the assigned tasks t 2 and t 3) and VM21 with task t 1. In this case, due to the low differences between the different communication slowdowns, task assignment was distributed between the two nodes.
Table 9.
Low slowdown. Solver assignment.
| Node | VMnvn | Task assignment |
|---|---|---|
| 1 | VM11 | t 1, t 3 |
| 1 | VM12 | 0 |
| 1 | VM13 | 0 |
| 2 | VM21 | t 2 |
4.2.3. Moderate Communication Slowdown
We simulated a more normal situation, where the communication slowdown between nodes is higher than the other ones. From the same example, it was only reduced to 0.4 (see Table 10). As expected, the resulting solver assignment was different from that in the previous case. Theoretically, this assignment should assign tasks to the powerful unsaturated VMs, but as much as possible to the VMs residing on the same node. The solver result was exactly what was expected. Although the most powerful VM is in node 2, the tasks were assigned to the VMs of node 1, because they all fit in the same node. That is the reason why a less powerful node like node 1, but one with more capacity, is able to allocate more tasks than node 2 due to the communication slowdown between nodes. These results are shown in Table 11.
Table 10.
Moderate slowdown. Communication configurations.
| Task t i | Task t j | Communication costs C ij |
|---|---|---|
| t 1 | t 2 | 0.2 |
| t 1 | t 3 | 0.6 |
| t 2 | t 3 | 0.3 |
| 0.9 | ||
| 0.4 | ||
Table 11.
Moderate slowdown. Solver assignment.
| Node | VMnvn | Tasks assignment |
|---|---|---|
| 1 | VM11 | t 2, t 3 |
| 1 | VM12 | t 1 |
| 1 | VM13 | 0 |
| 2 | VM21 | 0 |
5. Conclusions and Future Work
This paper presents a cloud-based system scheduling mechanism called GS that is able to comply with low power consumption and SLA agreements. The complexity of the model developed was increased, thus adding more factors to be taken into account. The model was also tested using the AMPL modelling language and the SCIP optimizer. The results obtained proved consistent over a range of scenarios. In all the cases, the experiments showed that all the tasks were assigned to the most powerful subset of virtual machines by keeping the subset size to the minimum.
Although our proposals still have to be tested in real scenarios, these preliminary results corroborate their usefulness.
Our efforts are directed towards implementing those strategies in a real cloud environment, like the OpenStack [22] or OpenNebula [23] frameworks.
In the longer term, we consider using some statistical method to find an accurate approximation of the workload using well-suited Erlang distribution functions.
Acknowledgments
This work was supported by the MEYC under Contracts TIN2011-28689-C02-02. The authors are members of the research groups 2009-SGR145 and 2014-SGR163, funded by the Generalitat de Catalunya.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
References
- 1.Aversa R., Di Martino B., Rak M., Venticinque S., Villano U. Performance Prediction for HPC on Clouds. Cloud Computing: Principles and Paradigms. New York, NY, USA: John Wiley & Sons; 2011. [Google Scholar]
- 2.Iosup A., Yigitbasi N., Epema D. On the performance variability of production cloud services. Proceedings of the 11th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid '11); May 2011; pp. 104–113. [DOI] [Google Scholar]
- 3.Varia J. Architection for the Cloud: Best Practices. Amazon Web Services; 2014. [Google Scholar]
- 4. Intel cloud computing 2015 vision, http://www.intel.com/content/www/us/en/cloud-computing/cloudcomputing-intel-cloud-2015-vision.html.
- 5.Martinello M., Kaâniche M., Kanoun K. Web service availability—impact of error recovery and traffic model. Reliability Engineering & System Safety. 2005;89(1):6–16. doi: 10.1016/j.ress.2004.08.003. [DOI] [Google Scholar]
- 6.Vilaplana J., Solsona F., Abella F., Filgueira R., Rius J. The cloud paradigm applied to e-Health. BMC Medical Informatics and Decision Making. 2013;13(1, article 35) doi: 10.1186/1472-6947-13-35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Vilaplana J., Solsona F., Teixidó I., Mateo J., Abella F., Rius J. A queuing theory model for cloud computing. The Journal of Supercomputing. 2014;69(1):492–507. doi: 10.1007/s11227-014-1177-y. [DOI] [Google Scholar]
- 8.Beloglazov A., Buyya R. Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in Cloud data centers. Concurrency Computation Practice and Experience. 2012;24(13):1397–1420. doi: 10.1002/cpe.1867. [DOI] [Google Scholar]
- 9.Kliazovich D., Bouvry P., Khan S. U. GreenCloud: a packet-level simulator of energy-aware cloud computing data centers. The Journal of Supercomputing. 2012;62(3):1263–1283. doi: 10.1007/s11227-010-0504-1. [DOI] [Google Scholar]
- 10.Ghribi C., Hadji M., Zeghlache D. Energy efficient VM scheduling for cloud data centers: exact allocation and migration algorithms. Proceedings of the 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing (CCGrid '13); May 2013; pp. 671–678. [DOI] [Google Scholar]
- 11.Khan M. F., Anwar Z., Ahmad Q. S. Assignment of personnels when job completion time follows gamma distribution using stochastic programming technique. International Journal of Scientific & Engineering Research. 2012;3(3) [Google Scholar]
- 12.Lérida J. L., Solsona F., Hernández P., Giné F., Hanzich M., Conde J. State-based predictions with self-correction on Enterprise Desktop Grid environments. Journal of Parallel and Distributed Computing. 2013;73(6):777–789. doi: 10.1016/j.jpdc.2013.02.007. [DOI] [Google Scholar]
- 13.Goldman A., Ngoko Y. A MILP approach to schedule parallel independent tasks. Proceedings of the International Symposium on Parallel and Distributed Computing (ISPDC '08); July 2008; Krakow, Poland. pp. 115–122. [DOI] [Google Scholar]
- 14.Vinh T., Duy T., Sato Y., Inoguchi Y. Performance evaluation of a green scheduling algorithm for energy savings in cloud computing. Proceedings of the IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW '10); April 2010; Atlanta, Ga, USA. pp. 1–8. [DOI] [Google Scholar]
- 15.Mezmaz M., Melab N., Kessaci Y., Lee Y. C., Talbi E.-G., Zomaya A. Y., Tuyttens D. A parallel bi-objective hybrid metaheuristic for energy-aware scheduling for cloud computing systems. Journal of Parallel and Distributed Computing. 2011;71(11):1497–1508. doi: 10.1016/j.jpdc.2011.04.007. [DOI] [Google Scholar]
- 16.Ouyang Y. C., Chiang Y. J., Hsu C. H., Yi G. An optimal control policy to realize green cloud systems with SLA-awareness. The Journal of Supercomputing. 2014;69(3):1284–1310. doi: 10.1007/s11227-014-1190-1. [DOI] [Google Scholar]
- 17.Ferreto T. C., Netto M. A. S., Calheiros R. N., de Rose C. A. F. Server consolidation with migration control for virtualized data centers. Future Generation Computer Systems. 2011;27(8):1027–1034. doi: 10.1016/j.future.2011.04.016. [DOI] [Google Scholar]
- 18.Murtazaev A., Oh S. Sercon: server consolidation algorithm using live migration of virtual machines for green computing. IETE Technical Review (Institution of Electronics and Telecommunication Engineers, India) 2011;28(3):212–231. doi: 10.4103/0256-4602.81230. [DOI] [Google Scholar]
- 19.Monteiro A. F., Azevedo M. V., Sztajnberg A. Virtualized Web server cluster self-configuration to optimize resource and power use. Journal of Systems and Software. 2013;86(11):2779–2796. doi: 10.1016/j.jss.2013.06.033. [DOI] [Google Scholar]
- 20.Lin C.-C., Chin H.-H., Deng D.-J. Dynamic multiservice load balancing in cloud-based multimedia system. IEEE Systems Journal. 2014;8(1):225–234. doi: 10.1109/JSYST.2013.2256320. [DOI] [Google Scholar]
- 21.Vilaplana J., Solsona F., Mateo J., Teixido I. Service-Oriented Computing—ICSOC 2013 Workshops. Vol. 8377. Springer International Publishing; 2014. SLA-aware load balancing in a web-based cloud system over OpenStack; pp. 281–293. (Lecture Notes in Computer Science). [Google Scholar]
- 22.OpenStack http://www.openstack.org/
- 23.OpenNebula http://www.opennebula.org.