
Figure 3.
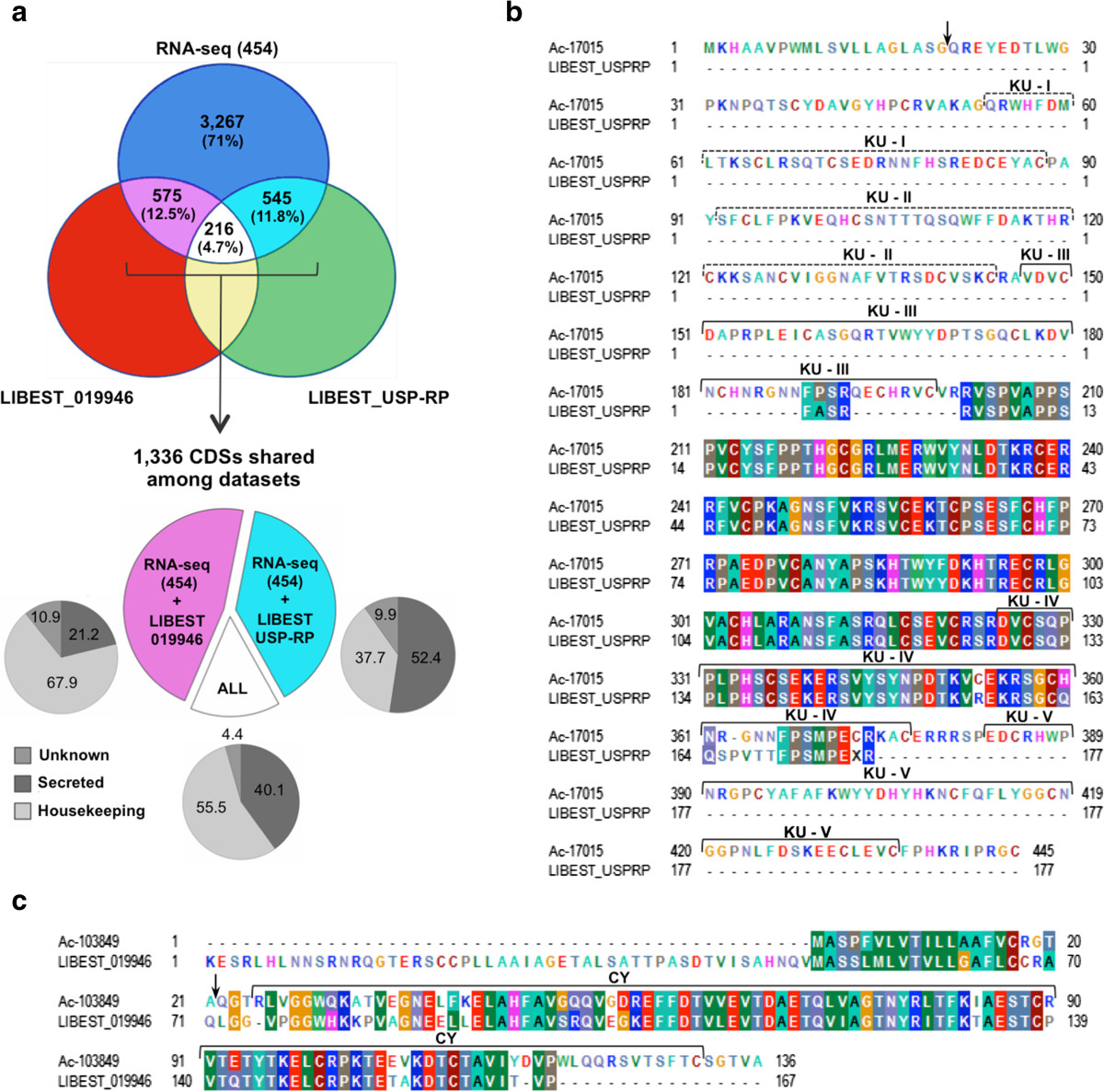
Comparison between distinct sialotranscriptome of Amblyomma cajennense tick. a) Venn diagram showing the proportion of CDSs (4,604 annotated in Additional file 3: AF3) identified in the RNA-seq (454) dataset and shared with the LIBEST_019946 (Batista et al., 2008) and LIBEST_USP-RP datasets. The values were based on the number of CDSs with significant matches to the other two datasets using the blastn algorithm. The magenta, cyan and white overlaps represent the sequences shared between the datasets. Approximately 30% of the CDSs (1,336) were contained sequences shared between two or more libraries. The proportion of shared proteins putatively secreted in the saliva, with housekeeping or unknown functions, are displayed in the small gray pie charts at the bottom. b) Sequence alignment of CDS Ac-1705 and ACGLSP02_C10 of the LIBEST_USP-RP dataset. This CDS was annotated as a putative Pentalaris protein, a serine protease inhibitor belonging to Kunitz domain superfamily. Horizontal brackets indicate the Kunitz domains (KU, 53 amino acids) along the sequences (I to V), as identified by the SMART protein database (smart00131). Dashed brackets indicate SMART hits with low scores, whereas solid brackets indicate SMART hits with high similarity scores. c) Sequence alignment of CDS Ac-103849 and ACAH15A10 of the LIBEST_019946 dataset. This CDS was annotated as a secreted Cystatin, a cysteine protease inhibitors. Horizontal brackets indicate the Cystatin-like domain (CY, 107 amino acids) identified by the SMART protein database (smart00043). In b and c, upper arrows indicate the peptide cleavage sites predicted by SignalP Server [97]. Side numbers on block alignments indicate the amino acid position in each sequence. The alignments were produced with Clustal-W using a PAM 250 matrix for amino acid coloring in BioEdit software.