
Figure 2. Kernel analysis curves of model representations.

Precision, one minus loss (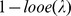 ), is plotted against complexity, the inverse of the regularization parameter (
), is plotted against complexity, the inverse of the regularization parameter (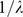 ). Shaded regions indicate the standard deviation of the measurement over image set randomizations, which are often smaller than the line thickness. The Zeiler & Fergus 2013, Krizhevsky et al. 2012 and HMO models are all hierarchical deep neural networks. HMAX [41] is a model of the ventral visual stream and the V1-like [35] and V2-like [42] models attempt to replicate response properties of visual areas V1 and V2, respectively. These analyses indicate that the task we are measuring proves difficult for V1-like and V2-like models, with these models barely moving from 0.0 precision for all levels of complexity. Furthermore, the HMAX model, which has previously been shown to perform relatively well on object recognition tasks, performs only marginally better. Each of the remaining deep neural network models performs drastically better, with the Zeiler & Fergus 2013 model performing best for all levels of complexity. These results indicate that the visual object recognition task we evaluate is computationally challenging for all but the latest deep neural networks.
). Shaded regions indicate the standard deviation of the measurement over image set randomizations, which are often smaller than the line thickness. The Zeiler & Fergus 2013, Krizhevsky et al. 2012 and HMO models are all hierarchical deep neural networks. HMAX [41] is a model of the ventral visual stream and the V1-like [35] and V2-like [42] models attempt to replicate response properties of visual areas V1 and V2, respectively. These analyses indicate that the task we are measuring proves difficult for V1-like and V2-like models, with these models barely moving from 0.0 precision for all levels of complexity. Furthermore, the HMAX model, which has previously been shown to perform relatively well on object recognition tasks, performs only marginally better. Each of the remaining deep neural network models performs drastically better, with the Zeiler & Fergus 2013 model performing best for all levels of complexity. These results indicate that the visual object recognition task we evaluate is computationally challenging for all but the latest deep neural networks.