

Summary
In this paper we propose a varying coefficient model for highly sparse longitudinal data that allows for error-prone time-dependent variables and time-invariant covariates. We develop a new estimation procedure, based on covariance representation techniques, that enables effective borrowing of information across all subjects in sparse and irregular longitudinal data observed with measurement error, a challenge in which there is no adequate solution currently. More specifically, sparsity is addressed via a functional analysis approach that considers the observed longitudinal data as noise contaminated realizations of a random process that produces smooth trajectories. This approach allows for estimation based on pooled data, borrowing strength from all subjects, in targeting the mean functions and auto- and cross-covariances to overcome sparse noisy designs. The resulting estimators are shown to be uniformly consistent. Consistent prediction for the response trajectories are also obtained via conditional expectation under Gaussian assumptions. Asymptotic distribution of the predicted response trajectories are derived, allowing for construction of asymptotic pointwise confidence bands. Efficacy of the proposed method is investigated in simulation studies and compared to the commonly used local polynomial smoothing method. The proposed method is illustrated with a sparse longitudinal data set, examining the age-varying relationship between calcium absorption and dietary calcium. Prediction of individual calcium absorption curves as a function of age are also examined.
Keywords: Functional data analysis, Local least squares, Measurement error, Repeated measurements, Smoothing, Sparse design
1 Introduction
Varying coefficient models (Cleveland, Grosse and Shyu, 1991; Hastie and Tibshirani, 1993) are extensions of parametric regression models that have attracted many applications in diverse scientific research areas in the last fifteen years. An example is the modeling of the time-varying relationship between virologic response and immunologic status (as measured by viral load and CD4+ status) and other covariates in AIDS clinical studies. As recently reviewed by Fan and Zhang (2008), estimation in varying coefficient models for longitudinal data is based on three main approaches: polynomial spline (Huang, Wu and Zhou, 2002; 2004), smoothing spline (Hoover et al., 1998; Chiang, Rice and Wu, 2001) and perhaps the most natural approach of all, local polynomial smoothing (Wu, Chiang and Hoover, 1998; Hoover et al., 1998; Fan and Zhang, 2000; Wu and Chiang, 2000). Qu and Li (2006) proposed penalized spline and quadratic inference functions for incorporating the correlation structure into the estimation.
Although these approaches may be more effective for densely measured longitudinal data, highly sparse longitudinal data combined with measurement error poses unique unresolved challenges. Here sparsity refers to the irregular measurement times between subjects and the availability of only a few observed repetitions per subject in longitudinal designs. With measurement error, estimation of the varying coefficient functions by applying the above methods will be biased. Measurement error is typical in studies of dietary intake (Carroll et al., 2006), such as individual calcium absorption and dietary calcium in adult women population that we consider in Section 4. Of particular interest is estimation of the age-varying relationship between calcium absorption and dietary calcium and other baseline measures, such as body surface area. In addition to inherent measurement errors, the data is sparse with subject ages ranging from 39 to 58 and due to dropouts and missed visits about 40% of the subject have only two or a single measurement. For both estimation of the varying coefficient function and prediction of individual calcium absorption curves, an effective strategy to pool information across subjects is needed.
In this paper we take a functional analysis approach to propose multiple varying coefficient modeling of noise-contaminated sparse longitudinal data, and to develop a new estimation method that allows for both cross-sectional (time-invariant) and longitudinal predictors. The main idea of the functional approach is to view the observed longitudinal data as a noise contaminated realization of a stochastic process which produces smooth trajectories. This approach is adopted to allow for pooling of information across subjects in order to strengthen the estimation from sparse data. We note that functional data analysis has been extended to sparse longitudinal data in the context of functional regression models by Yao, Müller and Wang (2005a). More recently Şentürk and Müller (2009) considered estimation in functional varying coefficient models with one covariate process that incorporates a history index. However, as the authors point out, their estimation approach is also useful for univariate varying coefficient models relating a longitudinal response process to a single longitudinal predictor process. The authors represent the varying coefficient functions using auto- and cross-covariances of the underlying stochastic processes which are then estimated based on the entire data using functional analysis approaches. We utilize similar representations for the varying coefficient functions and propose an estimation procedure for multiple predictor processes, which may include cross-sectional and longitudinal covariates. Several important distinctions of the current proposal from Şentürk and Müller's methodology are as follows. First, the current proposal is designed for multiple predictor processes. Second, cross-sectional predictors are included in the functional analysis approach proposed. We note that incorporation of cross-sectional predictor variables is not very common in functional linear models and functional data analysis. Our third new contribution is developing the estimation method to accommodate these two innovations and to study its theoretical and finite sample properties. The proposed estimation procedure enables a novel way of incorporating the within-subject correlation and handling sparse noise-contaminated longitudinal designs, which leads to improved finite sample performance relative to the commonly used local polynomial smoothing methods for varying coefficient models.
In the next section we describe the proposed estimation procedure for the multiple varying coefficient model with time-dependent and time-invariant covariates in its full generality and provide uniform consistency of the proposed estimators. Consistent prediction of the response trajectories via conditional expectation obtained under Gaussian assumptions are given in Section 3. Also given in Section 3 is the asymptotic distribution of the predicted response trajectories along with asymptotic pointwise confidence bands. In Section 4 the method is illustrated with the aforementioned sparse longitudinal data set, where we examine the age-varying relationship between calcium absorption and dietary calcium. Simulation studies, including comparisons with local polynomial smoothing, and concluding remarks follow in Section 5 and 6, respectively. Technical assumptions and proofs are given in the appendix.
2 Estimation in Multiple Varying Coefficient Models
2.1 Sparse Data and Model Representation
Consider the observed data, consisting of p time-dependent and q time-independent predictors along with a time-dependent response. The q time-independent predictors Zgi, i = 1, …, n, g = 1, …, q are assumed to have finite variance. The time-dependent predictors Xri and response Yi, i = 1, …, n, r = 1, …, p are square integrable random realizations of the smooth random processes Xr and Y respectively, both defined on a finite and closed interval domain [0, T]. Predictor and response processes X and Y have smooth mean functions μXr(t) = EXr(t), μY(t) = EY(t), and (auto-)covariance functions GXrXr(s, t) = cov{Xr(s), Xr(t)}, GYY(s, t) = cov{Y(s), Y(t)}, for s, t ∈ [0, T] and r = 1, …, p. Orthogonal expansions of the covariances, i.e. and for s, t ∈ [0, T] and r = 1, …, p follow under mild conditions, where ϕrm and ψk denote the eigenfunctions with nonincreasing eigenvalues ρrm and λk. The sparse design (SD), following Şentürk and Müller(2009), can formally be described in the following manner.
(SD) For the i-th subject one has a random number Ni of repeated measurements on the rth time-dependent predictor, Xrij = Xri(Tij) + εrij, and on the response, Yij = Yi(Tij) + εij, j = 1, …, Ni, obtained at i.i.d. random time points Ti1, …, TiNi, where εrij, εij are zero mean finite variance i.i.d. measurement errors. The Ni are assumed to be i.i.d and Ni, Tij, εrij, εij are mutually independent, and also independent of the underlying processes Xri, Yi as well as Zgi. Hence the predictor and response observations can be represented as , , where ξrim, ζik are uncorrelated mean zero functional principal component scores with second moments equal to the eigenvalues ρrm and λk, respectively.
The representations in (SD) above follow from the Karhunen-Loève expansion (see Ash and Gardner, 1975), where we also assume , for the eigenvalues.
Consider the multiple varying coefficient model
| (1) |
where the varying coefficient functions, βr(t) and αg(t), are assumed to be smooth functions. Note that for each fixed t, model (1) reduces to a standard linear model. Centering the predictor and response trajectories, i.e. , and YC(t) = Y(t) − μY(t), we can express model (1) as
Note that alternatively β0(t) can be given as .
2.2 Local Linear Smoothing
A standard method for fitting varying coefficient models (Fan and Zhang, 2008) is local polynomial smoothing. For instance, local linear fitting would minimize
| (2) |
with respect to θr,0, θr,1, γg,0, γg,1, leading to β̂r(t) = θ̂r,0 and α̂g(t) = γ̂g,0 (Hoover et al., 1998). The minimization in (2) requires a specified kernel function K(·), which corresponds to a symmetric probability density function associated with a bandwidth h. Şentürk and Müller (2009) point out that local polynomial smoothing does not take advantage of the functional nature of the underlying processes. In other words, while (2) involves each repeated observation taken on a subject, it does not involve the cross product terms between the repetitions which would correspond to the underlying covariance structure. They also point out that local polynomial smoothing will be biased for the case of sparse and noise-corrupted measurements. We will demonstrate that this bias is also present in the multiple varying coefficient model through simulations.
2.3 Proposed Estimation Procedure
The proposed approach will utilize the functional nature of the covariate processes. Thus, we define the auto- and cross-covariance functions:
and GZgZg′ = cov(Zg, Zg′). Consider the following equalities that follow directly from (1)
for r′ = 1, …, p and g′ = 1, …, q. Then the varying coefficient functions of interest can be obtained as
| (3) |
where
| (4) |
and Ξt = [GYX1 (t, t), …, GYXp(t, t), GYZ1 (t), …, GYZq (t)]T. Estimation of the varying coefficient functions in (3) involves first obtaining estimates of the auto- and cross-covariances in (χt and Ξt and then using the plug-in estimator . The special case of p = 1 and q = 0 is considered by Şentürk and Müller (2009) based on the relations β1(t) = GYX(t, t)/GXX(t, t). The proposal here is adopted for multiple predictor processes in addition to cross-sectional predictors. The estimation algorithm is given through the following steps.
Mean functions. Estimate the mean functions for the predictor and response processes by smoothing the aggregated data (Tij, Xrij) and (Tij, Yij) for j = 1, …, Ni, and i = 1, …, n, with local linear fitting. Denote the estimated mean functions by μ̂Xr and μ̂Y.
- Raw covariances. Compute the raw covariances of Xr and Zg and the raw cross-covariances between (Y, Xr), (Xr, Zg) and (Y, Zg) based on all observations from the same subject, defined by
for j, ℓ = 1, …, Ni and i = 1, …, n. These raw covariances are then smoothed, giving their corresponding final estimates described in the next step. -
Smoothed covariances. (3A) The final estimates of the two-dimensional auto- and cross-covariances, namely ĜXrXr′ and ĜYXr′ are obtained by feeding the corresponding two-dimensional raw covariances, GXrXr′,i and GYXr,i from step 2, into a two dimensional local least squares smoothing algorithm.
Remark 1. For estimation of the auto-covariances GXrXr, the diagonal of the raw auto-covariance matrix is removed before the two dimensional smoothing step, in order to eliminate the effects of measurement error on the longitudinal predictors. This covariance estimation step (inspired by the approach in Yao, Muller and Wang, 2005a, b) achieves two major objectives. First, it eliminates the effect of the noise contamination on the longitudinal observations. Second, through pooling of the data across subjects, it overcomes the problems associated with the sparseness of the design. In addition, to guarantee that the estimator of GXrXr is nonnegative definite, we propose an adjusted estimator where we exclude the negative estimates of the eigenvalues and corresponding eigenfunctions in the functional principal component decomposition of the covariance function. More precisely, a nonparametric functional principal component analysis step employed on the smooth estimate of the auto-covariance surface yields estimators for ϕrm(t) and ρrm, where details are described in Appendix A.1. Then, ĜXrXr is given as . The number Mr of included eigenfunctions can be chosen by one-curve-leave-out cross-validation, the Akaike information criterion (AIC), fraction of variance explained, or similar criteria.
(3B) Similarly, the final estimates of the one-dimensional cross-covariances, namely ĜXrZg and ĜYZg, are obtained by feeding the corresponding one-dimensional raw cross-covariances, GXrZg,i and GYZg,i, into a one-dimensional local polynomial smoothing algorithm. In addition the variance estimator ĜZgZg′ is given as n−1 .
Remark 2. Explicit forms of all one- and two-dimensional smoothing estimators are assembled in Appendix A.1.
-
Plug-in estimator. Estimators for the varying coefficient functions are obtained by simply using the following plug-in estimators for χt and Ξt: . Estimator of the intercept function can be given as , as noted earlier in Section 2.1.
We note that this estimation procedure differs from the standard methods for fitting varying coefficient models, which do not take advantage of the covariance structure of underlying processes. Using this structure in the estimation process makes it possible to handle the sparsity of the longitudinal data, but also allows for incorporating additional information that is inherent in the underlying covariance structure in the estimation step.
2.4 Uniform Consistency
The proposed estimators for the varying coefficient functions are uniformly consistent, as summarized in Theorem 1. The assumptions and proof can be found in the Appendix section. This result holds for sparse designs where the longitudinal predictor and response measurements are contaminated by additive measurement errors.
Theorem 1. Under Assumptions (A) in theAppendix, the varying coefficient function estimators satisfy
for r = 0, 1, …, p, and g = 1, …, q where .
In the above expression for τn, the bandwidths used in the two-dimensional smoothing step of the raw covariances to obtain the cross-covariance function ĜYXr are hr1 and hr2. Similarly, the corresponding bandwidths used in the two-dimensional smoothing step to obtain the cross-covariance surface ĜXrXr, are denoted by hXr and hXr′. Details are given in Appendix A.1. The bandwidths are required to converge to zero, and to satisfy some other restrictions outlined in Appendix A.2.
3 Prediction of Response Trajectories
Also of interest, in addition to estimation of the varying coefficient functions, is the prediction of calcium absorption trajectories as a function of age, based on dietary calcium (X*) and body surface area (Z*). More generally, prediction of an individual response trajectory Y* based on a new subject's sparse observations from the longitudinal predictor trajectories and the cross-sectional predictors is of interest. In this section, we provide consistent predictors of individual response trajectories and provide their asymptotic distribution for construction of asymptotic pointwise confidence intervals.
From the proposed model (1), the predicted response trajectory would be obtained through the following conditional expectation
| (5) |
where is the mth functional principal component score of . To estimate the predicted trajectory in (5), we note that the estimates of μY(t), βr(t) and αg(t) were described in the previous section. Also, the nonparametric functional principal component analysis step employed in the estimating the auto-covariance surface ĜXrXr yields estimators for ϕrm(t) and ρrm, where details are described in Appendix A.1. Thus, the only term remaining in (5) that requires estimation is .
Estimation of is a challenging problem since the integral cannot be approximated feasibly from the sparse trajectory .However, estimation is feasible under a Gaussian framework, following the novel work of Yao, Muller and Wang (2005b). More precisely, let be the jth measurement for the predictor function and be the observed noise-contaminated version of it at time for a random number of total measurements N*, j = 1, …, N*. Further let . Assume that the functional principal component scores , the measurement errors and are jointly Gaussian. Then the predicted is given as the best linear prediction conditional on the (N*p + q) × 1 observation vector , N*, and locations of the observations , namely
| (6) |
In (6) is the (N*p + q) × 1 mean vector with ,
| (7) |
is the (N*p + q) × 1 covariance vector with ρrm,r′m′ = cov(ξrm, ξr′m′) and . The (N*p + q) × (N*p + q) covariance matrix ΣU*. in (6) is equal to
where the N* × 1 vector , the scalars GZgZg′ are as defined Section 2.3 and the N* × N* covariance matrix for r ≠ r′ and with the (j, ℓ)th entry where δjℓ = 1 if j = ℓ and 0 if j ≠ ℓ.
Next, estimators of , , , G̃XrZg, GZgZg′ and G̃XrXr that are based on the entire data, where , are substituted in (6) to obtain a plug-in estimator for . Explicit forms of the estimator of the variance of the measurement errors, are given in Appendix A.1. The covariance ρrm,r′m′ can be estimated via ∫ ĜXrXr′(s, t)ϕ̂rm(s)ϕ̂r′m′(t)dsdt and E(ξrmZg) can be estimated by ∫ ĜXrZg(t)ϕ̂rm(t)dt using estimates of GXrXr′, GXrZg and ϕrm(t). Finally, where the numbers M1, …, Mp of included eigenfunctions can be chosen by one-curve-leave-out cross-validation, the Akaike information criterion (AIC) or the fraction of variance explained. This leads to . Hence, the predicted trajectories are given as
| (8) |
where . The following Theorem provides the consistency of the prediction for the target trajectory .
Theorem 2. Under Assumptions (A) and (B) in theAppendix, given N* and T*, for all t ∈ [0, T], the prediction for the response trajectory satisfies
Here the number Mr = Mr(n) of eigen-components included in the eigen-decomposition of for r = 1, …, p and hence (ℳ all tend to infinity as n → ∞.
Next we consider construction of asymptotic confidence bands for the response trajectory Y*, given the observed sparse and noisy data. For M1, …, Mp ≥ 1, let for r = 1, …, p and . Quantities and ξ̃*ℳ are defined similarly. Under the Gaussian assumption, given N* and T*, ξ̃*ℳ − ξ*ℳ ∼ N(0, Ωℳ), where the normality, covariance matrix Ωℳ and its plug-in estimator Ω̂ℳ are derived in the proof of Theorem 3 given in Appendix A.2. Define ϕtℳ = {β1(t)ϕ11(t), …, β1(t)ϕ1M1(t), …, βp(t)ϕp1(t), …, βp(t)ϕpMp(t)}T for t ∈ [0, T] and let ϕ̂tℳ be its estimate obtained from the data. The following Theorem 3 establishes the asymptotic distribution of the predicted trajectories , conditional on N* and T*.
Theorem 3. Under Assumptions (A), (B) and (C) in theAppendix, given N* and T*, for all t ∈ [0, T], x ∈ ℝ, the prediction for the response trajectory satisfies
where , and Φ(·) denotes the Gaussian cdf and Mr, r = 1, …, p and hence ℳ, all tend to infinity as n → ∞.
Hence, ignoring bias resulting from truncation at M1, …, Mp in , the (1 − α) 100% asymptotic pointwise confidence interval for is given by .
4 Application to Sparse Dietary Calcium Absorption Data
In a study of calcium deficiency, Heaney et al. (1989) showed a complex inverse relation between calcium intake and calcium absorption where age and body surface area are among the variables that affect calcium absorption efficiency We examine the age-varying coefficient regression of calcium absorption on intake and body surface area via the analysis of data from a longitudinal study on factors affecting calcium absorption (Davis, 2002, pg. 336). Longitudinal measurements were taken on absorption and intake among others, where repeated measurement per subject were taken in roughly five-year intervals. We analyze the data where patient ages are between 39 and 58, yielding 182 subjects with 1 to 4 repeated measurements per subject. The data is sparse and irregular due to measurement times between subjects that differed vastly and the number of total repetitions per subject is small. Figure 1 displays the observed individual trajectories of calcium intake X1(age) and absorption Y(age), along with the corresponding mean functions μ̂X and μ̂Y. An increasing trend with age is observed for intake and a decreasing trend is observed for absorption.
Figure 1.

(a) Observed individual trajectories (dashed) and the smoothed estimate of the mean function μ̂X (thick solid) for calcium intake. (b) Observed individual trajectories (dashed) and the smoothed estimate μ̂Y of the mean function for calcium absorption (thick solid). (c) Boxplot of baseline body surface area values of the 182 female patients.
We fit the age varying coefficient model
of Y (calcium absorption) on X1 (calcium intake) and Z1 (baseline body surface area; see Figure 1) using the proposed estimation procedure and kernel linear smoothing, as described in Section 2.2. The resulting estimated varying coefficient functions from both methods are displayed in Figure 2, along with 90% bootstrap percentile confidence intervals. Bootstrap confidence intervals are constructed from 500 bootstrap samples, generated by resampling subjects. Bandwidths for the smoothing of the cross-sectional mean functions, the covariance functions (GX1Z1 and GYZ1), the covariance surface (GX1X1), and the cross-covariance surface (GYX1) were selected by generalized cross-validation.
Figure 2.

(a) Estimated varying coefficient function β0(age) from the proposed varying coefficient model fit (solid) along with 90% bootstrap confidence intervals (dotted) for the calcium absorption data. Estimated functions from the varying coefficient model fits using kernel linear smoothing (dashed) are also displayed. (b) Estimated varying coefficient function β1(age), the slope function of calcium intake, from both fits along with 90% bootstrap confidence intervals. (c) Estimated varying coefficient function α1(age), the slope function of the cross-sectional variable body surface area, from both fits along with 90% bootstrap confidence intervals.
The estimated varying coefficient functions from both approaches, displayed in Figures 2, suggest a significant negative relationship between calcium intake and absorption. While the inverse relationship between intake and absorption is declining with age (Figure 2b), especially after age 45 in the kernel linear fit, such a decline is not observed in the proposed fit. Both methods indicate a significant positive effect of baseline body surface area on absorption, for ages between 43 and 55. While the effect is slowly becoming positive with age in both methods, the effect estimated by the kernel linear fit is much larger in magnitude. These differences in the estimated varying coefficients for the kernel linear method are attributed to the estimation bias of the kernel linear method because of potential measurement error and for lack of efficiency due to the fact that it does not incorporate the underlying correlation structure into the estimation. These issues are further investigated in the simulation studies of Section 5. The estimated positive and negative relations of calcium absorption with intake and body surface area respectively, are consistent with earlier findings (Heaney et al., 1989).
Next, we illustrate the prediction of calcium absorption trajectories as described in Section 3, based on sparse longitudinal intake trajectories along with baseline body surface area. The numbers of eigenfunctions used in the expansion of the predictor trajectories given in (8) were chosen by AIC; further details on these choices can be found in Yao, Müller and Wang (2005a). The predicted trajectories for 4 randomly selected subjects are given in Figure 3. The trajectories show a decline in calcium absorption with age, which is the same pattern as observed in the estimated smooth mean function of Figure 1. Overlaying the predictions are 90% approximate confidence intervals, as proposed in Section 3, along with observed calcium absorption values and predictions obtained from kernel linear smoothing. Predictions and the confidence intervals are obtained with the predicted subject's predictor trajectory left out. The predicted values obtained from kernel linear smoothing are similar to those obtained from the proposed method, where the average absolute prediction error from both kernel linear smoothing and the proposed method are 0.0612 and 0.0643, respectively.
Figure 3.

Observed values (circles) for calcium absorption (not used for prediction), predicted curves (solid) and 90% pointwise confidence bands (dotted), for four randomly selected patients, where bands and predicted curves are based on one-curve-leave-out analysis. Also displayed (+) are predicted values from the kernel linear smoothing estimation.
Note that even though the kernel linear smoothing estimation procedure cannot target the true underlying varying coefficient functions in the analysis of sparse noise-contaminated longitudinal data as will be demonstrated in the simulations of Section 5, this does not translate into predictions of the response values. This is a well known phenomenon in nonparametric measurement error models, where in the nonparametric regression model Y = g(X) + ε, the predictor X is measured with additive measurement error U yielding the observations W = X + U. Even though the nonparametric estimation of g(·) needs to adjust for the additive measurement error, the prediction of future response values can be obtained without adjusting for the additive measurement error via estimation of E(Y|X + U) = E(Y|W). See Carroll et al. (2006), Carroll and Hall (1988), Stefanski and Carroll (1990) and Carroll, Delaigle and Hall (2009) for further details and discussions on similar issues. Finally, we note an important distinction: although the kernel linear smoothing and the proposed estimation methodology yield similar predictions, the proposed method has the distinctive advantage of providing predicted response trajectories for the entire length of the study, while kernel linear smoothing and other methods can only provide pointwise predictions.
5 Simulation Studies
We assess the finite sample performance of the proposed estimation algorithm and compare its performance to that of kernel linear smoothing via three simulation studies. While the first simulation set-up corresponds to highly sparse designs, the second set-up reflects denser longitudinal designs. The first two simulation set-ups involve a varying coefficient model with one longitudinal and one cross-sectional covariate similar to the data analysis. We study the performance of the proposed estimation algorithm for a varying coefficient model with two longitudinal and two cross-sectional predictors in the third simulation for sparse longitudinal data. We report results for all set-ups based on 500 Monte Carlo runs.
In the first study the number of measurements per subject are randomly chosen with equal probability from {1, 2, 3, 4} for each of n = 182 subjects, similar to the calcium absorption data, to reflect highly sparse designs. The locations Tij of the measurements for the i-th subject are generated uniformly from [0, 10]. The predictor process X is generated according to (SD) of Section 2.1 with mean function μX(t) = t + sin(t), two eigenfunctions,
and
, for 0 ≤ t ≤ 10 and two eigenvalues, ρ1 = 2 and ρ2 = 1, respectively. The functional principal components ξim (m = 1, 2) are generated from
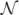 (0, ρm), and the mean zero additive measurement error εij is assumed to be Gaussian with variance 0.2. The cross-sectional variable Z1 is generated from
(0, 1), where it is the marginal component from a bivariate normal distribution for (Z1i, ξi2) with cov(Z1, ξ2) = 0.3, to allow for correlation between X1 and Z1. The response trajectories are generated from
(0, ρm), and the mean zero additive measurement error εij is assumed to be Gaussian with variance 0.2. The cross-sectional variable Z1 is generated from
(0, 1), where it is the marginal component from a bivariate normal distribution for (Z1i, ξi2) with cov(Z1, ξ2) = 0.3, to allow for correlation between X1 and Z1. The response trajectories are generated from
| (9) |
according to (1), where β0(t) = 10 sin(π + tπ/5), β1(t) = sin(πt/10), α1(t) = t/10. The functional error Vi in (9) is constructed from the same two eigenfunctions as used for X(t), with Gaussian functional principal components generated with eigenvalues ρ1 = 0.2 and ρ2 = 0.1. The observed measurements on the response are further contaminated with additive measurement errors according to Yij = Yi(Tij) + εij, where εij are i.i.d. zero mean Gaussian errors with variance 0.2. Under the second simulation set-up, the variables are generated in the same way as the first set-up, except at still irregular but denser (non-sparse) measurement times, with the total number of repeated measurements generated uniformly from {5, …, 15}. The average number of repeated measurements per subject is 10 for the dense case, compared to less than 3 observations per subject for the highly sparse case.
We compare the performance of the proposed estimation algorithm with the performance of kernel linear smoothing under the sparse and denser set-ups using mean absolute deviation error (MADE) and weighted average squared error (WASE) , defined respectively as
where T = 10, range(βr) is the range of the function βr(t) and range(α1) is defined similarly. We also consider the unweighted average squared error (UASE) to compare the estimators, where UASE is defined the same way as WASE, but without weights in the denominator. Bandwidths involved in smoothing of the mean functions and the auto- and cross-covariance surfaces are chosen by generalized cross-validation.
Results from sparse and denser simulation set-ups are given in Figures 4 and Figure 5, respectively. More specifically, plot (d) in both figures are boxplots of logarithms of the ratios of MADE, WASE and UASE values of the proposed method over the kernel linear smoothing approach. The proposed estimators lead to improved finite sample performance for both sparse and denser cases with respect to all three error criteria. More specifically, the proposed estimators have improved performance in (85, 77, 71)% of the Monte Carlo runs for sparse design according to (MADE, WASE, UASE) criterion respectively, while they lead to improved performance in all Monte Carlo runs according to all three criteria in the case of denser design. This can be attributed to the fact that the proposed method adjusts for noise contaminated measurements and incorporates information inherent in the underlying correlation structure of the longitudinal processes. The estimated varying coefficient functions based on the proposed method and the kernel linear approach are provided in Figure 4 (a)-(c) and Figure 5 (a)-(c) for both simulation scenarios. Displayed are the cross-sectional medians of the estimated varying coefficient functions for the proposed method and the kernel linear method, together with estimated functions corresponding to the 5% and 95% cross-sectional percentiles for the proposed method. The kernel linear smoothing fits deviate from the underlying true functions for both sparse and denser simulation set-ups. The bias is especially apparent in the estimation of β1(t) (e.g. see Figure 5(b)) and is also apparent in the estimation of β0(t). The (median) estimated functions of the proposed method target the corresponding true functions closely for both simulation scenarios (highly sparse and dense data), and for dense data case note that they essentially coincide with the true functions. This is not surprising since from the highly sparse case to the dense case, there is an average of 4-fold increase in the number of repeated observations per subject. However, the bias of estimated functions via the kernel linear method remains due to the measurement error.
Figure 4.

First simulation set-up given in (9) with highly sparse design: (a) The cross-sectional median curves of the proposed estimates (grey) along with 5% and 95% cross-sectional percentiles (dotted) overlaying the true varying coefficient function β0(t) (solid). Also displayed are the cross-sectional median curves from fits using kernel linear smoothing (dash-dotted). Similarly, for (b) β1(t) and (c) α1(t). (d) Boxplots for the logarithm of the ratios of error measures (MADE, WASE and UASE) for proposed estimates over kernel linear smoothing. Values smaller than zero show that the proposed method is superior.
Figure 5.

Second simulation set-up given in (9) with denser design: (a) The cross-sectional median curves of the proposed estimates (grey) along with 5% and 95% cross-sectional percentiles (dotted) overlaying the true varying coefficient function β0(t) (solid). Also displayed are the cross-sectional median curves from fits using kernel linear smoothing (dash-dotted). Similarly, for (b) β1(t) and (c) α1(t). (d) Boxplots for the logarithm of the ratios of error measures (MADE, WASE and UASE) for proposed estimates over kernel linear smoothing. Values smaller than zero show that the proposed method is superior.
In addition, we studied the coverage level of the proposed asymptotic confidence intervals for the predicted response trajectories given in Section 3 under the sparse set-up of the first simulation. Pointwise confidence intervals are constructed at a grid of time points at the 95% level, where coverage levels are averaged over number of subjects in 100 Monte Carlo runs. The estimated coverage levels are given in Figure 6 for sample sizes, n = 182, 400 and 1000. A boundary effect is observed in the estimated coverage levels given over time, where the coverage level approaches the targeted 95% for the middle time range and the region for the boundary effect gets smaller with increasing sample size. For example, excluding boundary regions (time 0-1 and 9-10), the coverage is between 83% and 96% for the time region 1-9 for n = 1000.
Figure 6.

Estimated coverage levels for the 95% asymptotic confidence intervals of the predicted response trajectory proposed in Section 3 under the sparse design of the first simulation for n = 182 (dotted), n = 400 (dash-dotted) and n = 1000 (solid).
For the third simulation, the number of measurements per subject are randomly chosen with equal probability from {4, 5, 6, 7, 8} for each of n = 400 subjects where the locations Tij of the measurements for the i-th subject are generated uniformly from [0, 10]. The first longitudinal predictor process X1 is generated with the same mean function and eigenbasis as in the first two simulations with ρ1 = 1 and ρ2 = 1, while the second longitudinal predictor X2 is generated with mean function μX2(t) = −(t − 5)2/2, two basis functions, ϕ1(t) = (t − 5)/5 and ϕ2(t) = 3((t − 5)/5)2 − 1)/2, for 0 ≤ t ≤ 10 and with mean zero variance 1 Gaussian coefficients. The mean zero additive measurement error εrij is assumed to be Gaussian with variance 0.2 for both predictor processes. In order to allow for correlations between the two longitudinal and two cross-sectional predictors, the two cross-sectional variables Z1 and Z2 are generated from Gaussian distributions with means 1 and 2, variances 2 and 2 respectively, where they are marginal components from a six dimensional multivariate normal vector containing the two random coefficients of the two longitudinal predictors and the two cross-sectional predictors, i.e. (ξ1i1, ξ1i2, ξ2i1, ξ2i2, Z1i, Zg2). The 6 × 6 covariance matrix is equal to
The response trajectories are generated from
| (10) |
according to (1), where β0(t) = 50 sin(π + tπ/5), β1(t) = 5 sin(πt/10), β2(t) = 5 cos(πt/4), α1(t) = t/2 and α2(t) = (t − 5)2/20. The functional error Vi in (10) is constructed from the same two eigenfunctions as used for X1(t), with Gaussian functional principal components generated with eigenvalues ρ1 = 0.2 and ρ2 = 0.1. The additive measurement error on the response is generated from zero mean Gaussian distribution with variance 0.2. Boxplots of logarithms of the ratios of MADE, WASE and UASE values of the proposed method over the kernel linear smoothing approach along with cross-sectional medians and 5% and 95% percentiles of the estimated varying coefficient functions based on the proposed method and the medians of the kernel linear approach are provided in Figure 7. The proposed method performs better than the kernel linear smoothing according to all three criterion in 95% of the total Monte Carlo runs. The superior performance of the proposed method can be seen especially in the estimated β0 and the two slope varying coefficient functions β1 and β2 corresponding to longitudinal predictors measured with additive measurement error. The estimated median curves for the kernel linear smoother deviate from the true curves, not being able to handle measurement error in covariates.
Figure 7.

Third simulation set-up given in (10): (a) The cross-sectional median curves of the proposed estimates (grey) along with 5% and 95% cross-sectional percentiles (dotted) overlaying the true varying coefficient function β0(t) (solid). Also displayed are the cross-sectional median curves from fits using kernel linear smoothing (dash-dotted). Similarly for (b) β1(t) (c) β2 (d) α1(t) (e) α2(t). (f) Boxplots for the logarithm of the ratios of error measures (MADE, WASE and UASE) for proposed estimates over kernel linear smoothing. Values smaller than zero show that the proposed method is superior.
6 Discussion
In this work we proposed a multiple varying coefficient model in the context of highly sparse longitudinal data, where the longitudinal response and predictor processes are measured with error. The method is motivated by a study of calcium absorption and dietary calcium intake. We note that the proposed estimation algorithm is applicable to cases with possibly different time grids for each longitudinal covariate of a subject. Most longitudinal regression methods such as local polynomial smoothing require that the longitudinal predictors be observed at concurrent times as the longitudinal response variable. In practice this requirement may not be met either by design or due to common challenges with follow-up measurements over time and/or make-up measurements because of missed follow-up occasions. One example is multi-center studies where all covariates may not be observed at all centers, resulting in missing response or predictor values. While, in most longitudinal regression methods observations with a missing pair are discarded, in the proposed estimation procedure the observed measurements with missing pairs also contribute to the estimation algorithm and no observation is discarded due to the unique representation of the varying coefficient functions and the component-wise nature of the algorithm. This could lead to favorable properties of the proposed estimation algorithm in case of missing covariates especially for sparse designs, where imputation via smoothing techniques would not be feasible.
Acknowledgments
We are extremely grateful to two anonymous referees, the associate editor and editor for helpful remarks that improved the paper. Support for this work includes the National Institute of Health grants UL1RR024922, RL1AG032119 and RL1AG032115 and grant UL1 RR024146 from the National Center for Research Resources.
Appendix
A.1 Details on Estimation Procedures
Explicit forms of the proposed mean and covariance estimators, functional principal components decompositions and measurement error variance estimators are given as follows. Define the local linear scatterplot smoother for μXr(t) through minimizing
with respect to η0, ηl, leading to μ̂X(t) = η̂0. Other one-dimensional smoothing estimators of the proposed estimation algorithm, namely μ̂Y(t), ĜXrZg and ĜYZg can be defined similarly.
For the two-dimensional smoothers, recall , and define the local linear surface smoother for GXrXr′(s, t) through minimizing
| (11) |
where f{η, (s, t), (Tij, Tiℓ)} = η0 + ηl(s − Tij) + η2(t − Tiℓ), with respect to η = (η0, η1, η2), yielding ĜXrXr′ (s, t) = η̂0. The two-dimensional smoother in the estimation of GYXr is defined similarly.
For the estimation of the auto-covariance GXrXr, i.e. r = r′, the second sum in (11) is taken over 1 ≤ j ≠ ℓ ≤ Ni, to leave the noise contaminated diagonal raw covariance elements out of the smoothing procedure. For the eigen-decomposition of the auto-covariance surface GXrXr, the eigenquations, are solved under orthonormal constraints on the eigenfunctions, where is not the final but only the smooth estimator of the covariance function. To arrive at the final auto-covariance estimator, we exclude the negative estimates of the eigenvalues and corresponding eigenfunctions in the functional principal component decomposition of the covariance function, i.e. .
In the original smoothing estimator of the auto-covariance surface leading to , for estimation of var(εr), a local quadratic component is fit orthogonal to the diagonal of GXrXr and a local linear component is fit in the direction of the diagonal, resulting in a surface estimate where the diagonal will be denoted by Gr(s). In addition, a separate local linear smoother is fit only to the diagonal values {GXrXr(t, t) + var(εr)} denoted by V̂X(t). The estimator of var(εr) is given as the difference between the above two smoothing estimators for the diagonal terms, by , if var(εr) > 0, and var(εr) = 0 otherwise.
A.2. Assumptions and Proofs
Assumptions (A1–A6) are needed for all three theorems, (B1–B2) are needed for the consistency of the predicted response trajectories of Theorem 2 and their asymptotic distribution in Theorem 3, while (C) is only needed for the distributional result of Theorem 3.
-
(A1)
The cross-sectional predictors Zgi are iid for i = 1, …, n with var(Zgi) > 0 for g = 1, …, q.
-
(A2)
The covariance matrices χt defined in (4) are nonsingular for t ∈ [0, T].
The longitudinal predictor and response trajectories (Tij, Xrij) and (Tij, Yij), i = 1, …, n, j = 1, …, Ni, r = 1, …, p are assumed to have the same distribution as (
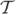 , Xr) and (
, Y) with joint densities gr(t, x) and h(t, y). The observation times Tij are i.i.d. with density f
(t). Let T1 and T2 be i.i.d. T and Xr1 and Xr2 be the repeated measurements of Xr made on the same subject at times T1 and T2, and assume (Tij, Tiℓ, Xrij, Xriℓ), 1 ≤ j ≠ ℓ ≤ Ni, is identically distributed as (T1, T2, Xr1, Xr2) with joint density function gXrXr(t1, t2, x1, x2). It is analogously assumed that the response measurements (Tij, Tiℓ, Yij, Yiℓ), 1 ≤ j ≠ ℓ ≤ Ni, are identically distributed with joint density function gYY(t1, t2, y1, y2). The following regularity conditions are assumed on f(t), gr(t, x), h(t, y), gXrXr(t1, t2, x1, x2) and gYY(t1, t2, y1, y2).
, Xr) and (
, Y) with joint densities gr(t, x) and h(t, y). The observation times Tij are i.i.d. with density f
(t). Let T1 and T2 be i.i.d. T and Xr1 and Xr2 be the repeated measurements of Xr made on the same subject at times T1 and T2, and assume (Tij, Tiℓ, Xrij, Xriℓ), 1 ≤ j ≠ ℓ ≤ Ni, is identically distributed as (T1, T2, Xr1, Xr2) with joint density function gXrXr(t1, t2, x1, x2). It is analogously assumed that the response measurements (Tij, Tiℓ, Yij, Yiℓ), 1 ≤ j ≠ ℓ ≤ Ni, are identically distributed with joint density function gYY(t1, t2, y1, y2). The following regularity conditions are assumed on f(t), gr(t, x), h(t, y), gXrXr(t1, t2, x1, x2) and gYY(t1, t2, y1, y2). -
(A3)
Let p1, p2 be integers with 0 ≤ p1, p2 ≤ p = p1 + p2 = 2. The derivative (dp/dtp)f
(t) exists and is continuous on [0, T] with f(t) > 0 on [0, T], (dp/dtp)gr(t, x) and (dp/dtp)h(t, y) exist and are continuous on [0, T] × ℝ, and
(t1, t2, x1, x2) and
(t1, t2, y1, y2) exist and are continuous on [0, T]2 × ℝ2. -
(A4)
The number of measurements Ni made on the ith subject is a random variable such that , where N is a positive discrete random variable with P(N > 1) > 0. The observation times and measurements are assumed to be independent of the number of observations for any subset Ji ∈ {1, …, Ni} and for all i = 1, …, n, i.e. {Tij, Yij, Xrij, Zgi : j ∈ Ji} is independent of Ni.
Let K1(·) be the nonnegative, mean zero, finite variance, compactly supported kernel function used in the estimating μXr, μY, GYZg, GXrZg and K2(·, ·) be the bivariate kernel function with similar properties used in estimating the covariance surfaces GXrXr′, GYXr. Explicit forms for the estimators of these quantities are given in Appendix A.3.
-
(A5)
The Fourier transform κ1(t) = ∫ e−iutK1(u)du of K1(u) and κ2(t, s) = ∫e−(iut+ivs)K2(u, υ)dudυ of K2(u, υ) are absolutely integrable, i.e. ∫|κ1(t)|dt < ∞ and ∫ ∫ |κ2(t, s)|dtds < ∞.
Let bXr, bY be the bandwidths used for estimating μ̂Xr, μ̂Y, (hXr, hXr′) be the bandwidths for estimating ĜXrXr′, (hr1, hr2) be the bandwidths for obtaining ĜYXr, hg for obtaining ĜYZg and hrg for ĜXrZg′, where all bandwidths depend on n.
-
(A6)
As n → ∞, bXr → 0, bY → 0, hg → ∞ and hrg → ∞, , , , and , , and . Without loss of generality hXr/hXr′ → 1, hr1/hr2 → 1 and , and and .
-
(A7)
Assume that the fourth moments of Y and X, centered at μY(t) and μX(t) are finite, i.e. E[{Y − μY(T)}4] < ∞, E[{(X − μX(T)}4] < ∞.
-
(A8)
The number of included eigenfunctions in (8), M1, …, Mp are integer valued sequences that depend on sample size n such that inft∈[0,T]Mr(n) → ∞ and both inft∈[0,T]Mr(n) and supt∈[0,T]Mr(n) satisfy the rate conditions given in assumption (B5) of Yao, Müller and Wang (2005a).
-
(A9)
The autocovariance operator AGr generated by the continuously differentiable covariance function GXrXr(s, t) is positive definite.
-
(B1)
The number and locations of the measurements for a subject or cluster remain unaltered as the sample size n → ∞.
-
(B2)
For all 1 ≤ i ≤ n, m ≥ 1, 1 ≤ r ≤ p, 1 ≤ g ≤ q and 1< j < Ni, the functional principal component scores ξrim, the cross-sectional predictors Zgi and the measurement errors εrij in (SD) are jointly Gaussian.
-
(C)
There exists a continuous positive definite function ωt such that ωtℳ as defined in Theorem 3 satisfies ωtℳ → ωt as M1, …, Mp … ∞.
Proof of Theorem 1. Uniform consistency of μ̂Xr(t) and μ̂Y(t) follow from Theorem 1 of Yao, Muller and Wang (2005b) and that of ĜXrZg(t) and ĜYZg(t) can be shown similar to the consistency of μ̂Xr(t) and μ̂Y(t) for r = 1, …, p, g = 1, …, q. The properties of AGr in (A9) imply that ρrm are all positive. Hence and are asymptotically equivalent since by Theorem 2 of Yao, Müller and Wang (2005b). The uniform consistency of ĜXrXr(s, t) follows from uniform consistency of the eigenvalue and eigenfunction estimators shown in Theorem 2 of Yao, Müller and Wang (2005b). For the rate conditions on Mr, we refer the reader to assumption (B5) of Yao, Müller and Wang (2005a) and note that further details on theoretical properties of functional principal component analysis can be found in Silverman (1996), Hall and Hosseini-Nasab (2009) and Hall et al. (2006). Uniform consistency of the cross-covariance estimators ĜXrXr′(s, t) and ĜYXr(s, t) follow from Lemma A1 of Yao, Müller and Wang (2005a). Combining these results implies uniform consistency of χ^t and Ξ̂t and Theorem 1 follows.
Proof of Theorem 2. For fixed M1, …, Mp and ℳ, let and recall that .
Observe the following decomposition
where it follows similar to Lemma 3 of Yao, Muller and Wang (2005b) that as M1, …, Mp → ∞ and n → ∞. The uniform consistency of μ̂Y(t) follows from Theorem 1 of Yao, Müller and Wang (2005b). Hence, using Theorem 1 of Section 2.4, Theorem 3 and (17) of Yao, Müller and Wang (2005b) and Slutsky's Theorem, it follows that as n → ∞ and Theorem 2 follows.
Proof of Theorem 3. Define and note the following decomposition
It follows from the proof of Theorem 2 that limn→ ∞ supt∈[0,T] .
Define the ℳ × (N*p+q) matrix
where
is as defined in (7). Since
,
. Hence,
, where D = cov(ξ*ℳ|N*, T*) is the ℳ × ℳ matrix with (r, r′)th partition, a Mr × Mr′ matrix
. Let
, where D̂ and
and Σ̂U* are estimated based on the entire data with
, Ê(ξrmZg) and ξ̂rm,r′m′ as defined in Section 3. It follows that under the Gaussian assumption for a fixed M1, …, Mp ≥ 1, ξ̃*ℳ − ξ*ℳ ∼
(0, Ωℳ). Hence,
Under Assumption (C), letting M1, …, Mp → ∞ leads to . From the Karhunen-Loéve Theorem, we have
as M1, …, Mp → ∞. Hence, . From Theorem 1 of Section 2.4 and Lemma 1 of Yao, Müller and Wang (2005a), it follows that limMl, …, Mp→∞ limn→∞ω̂tℳ = ωt. Theorem 3 follows by Slutsky's Theorem.
Contributor Information
Damla Şentürk, Email: dsenturk@stat.psu.edu.
Danh V. Nguyen, Email: ucdnguyen@ucdavis.edu.
References
- Ash RB, Gardner MF. Topics in Stochastic Processes. New York: Academic Press; 1975. [Google Scholar]
- Carroll RJ, Delaigle A, Hall P. Nonparametric prediction in measurement error models. Journal of the American Statistical Association. 2009;104:993–1003. doi: 10.1198/jasa.2009.tm07543. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carroll RJ, Hall P. Optimal rates of convergence for deconvolving a density. Journal of the American Statistical Association. 1988;83:1184–1186. [Google Scholar]
- Carroll RJ, Ruppert D, Stefanski LA, Crainiceanu CM. Measurement error in nonlinear models: A modern perspective. 2nd. Baco Raton: Chapman and Hall CRC Press; 2006. [Google Scholar]
- Chiang CT, Rice JA, Wu CO. Smoothing spline estimation for varying coefficient models with repeatedly measured dependent variables. Journal of the American Statistical Association. 2001;96:605–619. [Google Scholar]
- Cleveland WS, Grosse E, Shyu WM. Statistical Models in S, J. M. Chambers and T. J. Hastie. Pacific Grove: Wadsworth & Brooks; 1991. Local regression models; pp. 309–376. [Google Scholar]
- Davis CS. Statistical methods for the analysis of repeated measurements. New York: Springer; 2002. [Google Scholar]
- Fan J, Zhang W. Simultaneous confidence bands and hypothesis testing in varying-coefficient models. Scandinavian Journal of Statistics. 2000;27:715–731. [Google Scholar]
- Fan J, Zhang W. Statistical methods with varying coefficient models. Statistics and its Interface. 2008;1:179–195. doi: 10.4310/sii.2008.v1.n1.a15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hall P, Hosseini-Nasab M. Theory for high-order bounds in functional principal components analysis. Journal of the Royal Statistical Society B. 2009;68:109–126. [Google Scholar]
- Hall P, Müller HG, Wang JL. Properties of principal component methods for functional and longitudinal data analysis. The Annals of Statistics. 2006;34:1493–1517. [Google Scholar]
- Hastie T, Tibshirani R. Varying coefficient models. Journal of the Royal Statistical Soceity B. 1993;55:757–796. [Google Scholar]
- Heaney RP, Recker RR, Stegman MR, Moy AJ. Calcium absorption in women: relationships to calcium intake, estrogen status, age. Journal of Bone and Mineral Research. 1989;4:469–475. doi: 10.1002/jbmr.5650040404. [DOI] [PubMed] [Google Scholar]
- Hoover DR, Rice JA, Wu CO, Yang LP. Nonparametric smoothing estimates of time-varying coefficient models with longitudinal data. Biometrika. 1998;85:809–822. [Google Scholar]
- Huang JZ, Wu CO, Zhou L. Varying-coefficient models and basis function approximations for the analysis of repeated measurements. Biometrika. 2002;89:111–128. [Google Scholar]
- Huang JZ, Wu CO, Zhou L. Polynomial spline estimation and inference for varying coefficient models with longitudinal data. Statistica Sinica. 2004;14:763–788. [Google Scholar]
- Qu A, Li R. Quadratic inference functions for varying coefficient models with longitudinal data. Biometrics. 2006;62:379–391. doi: 10.1111/j.1541-0420.2005.00490.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Şentürk D, Müller HG. Technical report. Department of Statistics, Penn State University, University; 2009. Functional varying coefficient models for longitudinal data. [Google Scholar]
- Silverman BW. Smoothed functional principal components analysis by choice of norm. The Annals of Statistics. 1996;24:1–24. [Google Scholar]
- Stefanski LA, Carroll RJ. Deconvoluting kernel density estimators. Statistics. 1990;21:165–184. [Google Scholar]
- Wu CO, Chiang CT. Kernel smoothing on varying coefficient models with longitudinal dependent variable. Statist Sinica. 2000;10:433–456. [Google Scholar]
- Wu CO, Chiang CT, Hoover DR. Asymptotic confidence regions for kernel smoothing of a varying-coefficient model with longitudinal data. Journal of the American Statistical Association. 1998;93:1388–1402. [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional linear regression analysis for longitudinal data. Annals of Statistics. 2005a;3:2873–2903. [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association. 2005b;100:577–590. [Google Scholar]