

Abstract
We consider the high-dimensional discriminant analysis problem. For this problem, different methods have been proposed and justified by establishing exact convergence rates for the classification risk, as well as the ℓ2 convergence results to the discriminative rule. However, sharp theoretical analysis for the variable selection performance of these procedures have not been established, even though model interpretation is of fundamental importance in scientific data analysis. This paper bridges the gap by providing sharp sufficient conditions for consistent variable selection using the sparse discriminant analysis (Mai et al., 2012). Through careful analysis, we establish rates of convergence that are significantly faster than the best known results and admit an optimal scaling of the sample size n, dimensionality p, and sparsity level s in the high-dimensional setting. Sufficient conditions are complemented by the necessary information theoretic limits on the variable selection problem in the context of high-dimensional discriminant analysis. Exploiting a numerical equivalence result, our method also establish the optimal results for the ROAD estimator (Fan et al., 2012) and the sparse optimal scaling estimator (Clemmensen et al., 2011). Furthermore, we analyze an exhaustive search procedure, whose performance serves as a benchmark, and show that it is variable selection consistent under weaker conditions. Extensive simulations demonstrating the sharpness of the bounds are also provided.
Keywords: high-dimensional statistics, discriminant analysis, variable selection, optimal rates of convergence
1 Introduction
We consider the problem of binary classification with high-dimensional features. More specifically, given n data points, {(xi, yi), i = 1, …, n}, sampled from a joint distribution of (X, Y) ∈ ℝp × {1, 2}, we want to determine the class label y for a new data point x ∈ ℝp.
Let p1(x) and p2(x) be the density functions of X given Y = 1 (class 1) and Y = 2 (class 2) respectively, and the prior probabilities π1 =
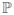 (Y = 1), π2 =
(Y = 2). Classical multivariate analysis theory shows that the Bayes rule classifies a new data point x to class 2 if and only if
(Y = 1), π2 =
(Y = 2). Classical multivariate analysis theory shows that the Bayes rule classifies a new data point x to class 2 if and only if
| (1.1) |
The Bayes rule usually serves as an oracle benchmark, since, in practical data analysis, the class conditional densities p2(x) and p1(x) are unknown and need to be estimated from the data.
Throughout the paper, we assume that the class conditional densities p1(x) and p2(x) are Gaussian. That is, we assume that
| (1.2) |
This assumption leads us to linear discriminant analysis (LDA) and the Bayes rule in (1.1) becomes
| (1.3) |
where μ = μ2 − μ1. Theoretical properties of the plug-in rule g(x; μ̂1, μ̂2, Σ̂), where (μ̂1, μ̂2, Σ̂) are sample estimates of (μ1, μ2, Σ), have been well studied when the dimension p is low (Anderson, 2003).
In high-dimensions, the standard plug-in rule works poorly and may even fail completely. For example, Bickel and Levina (2004) show that the classical low dimensional normal-based linear discriminant analysis is asymptotically equivalent to random guessing when the dimension p increases at a rate comparable to the sample size n. To overcome this curse of dimensionality, it is common to impose certain sparsity assumptions on the model and then estimate the high-dimensional discriminant rule using plug-in estimators. The most popular approach is to assume that both Σ and μ are sparse. Under this assumption, Shao et al. (2011) propose to use a thresholding procedure to estimate Σ and μ and then plug them into the Bayes rule. In a more extreme case, Tibshirani et al. (2003), Wang and Zhu (2007), Fan and Fan (2008) assume that Σ = I and estimate μ using a shrinkage method. Another common approach is to assume that Σ−1 and μ are sparse. Under this assumption, Witten and Tibshirani (2009) propose the scout method which estimates Σ−1 using a shrunken estimator. Though these plug-in approaches are simple, they are not appropriate for conducting variable selection in the discriminant analysis setting. As has been elaborated in Cai et al. (2011) and Mai et al. (2012), for variable selection in high-dimensional discriminant analysis, we need to directly impose sparsity assumptions on the Bayes discriminant direction β = Σ−1μ instead of separately on Σ and μ. In particular, it is assumed that for T = {1,…, s}. Their key observation comes from the fact that the Fisher’s discriminant rule depends on Σ and μ only through the product Σ−1μ. Furthermore, in the high-dimensional setting, it is scientifically meaningful that only a small set of variables are relevant to classification, which is equivalent to the assumption that β is sparse. On a simple example of tumor classification, Mai et al. (2012) elaborate why it is scientifically more informative to directly impose sparsity assumption on β instead of on μ (For more details, see Section 2 of their paper). In addition, Cai et al. (2011) point out that the sparsity assumption on β is much weaker than imposing sparsity assumptions Σ−1 and μ separately. A number of authors have also studied classification in this setting (Wu et al., 2009, Fan et al., 2012, Witten and Tibshirani, 2011, Clemmensen et al., 2011, Cai et al., 2011, Mai et al., 2012).
In this paper, we adopt the same assumption that β is sparse and focus on analyzing the SDA (Sparse Discriminant Analysis) proposed by Mai et al. (2012). This method estimates the discriminant direction β (More precisely, they estimate a quantity that is proportional to β.) and our focus will be on variable selection consistency, that is, whether this method can recover the set T with high probability. In a recent work, Mai and Zou (2012) prove that the SDA estimator is numerically equivalent to the ROAD estimator (Fan et al., 2012) and the sparse optimal scaling estimator (Clemmensen et al., 2011). By exploiting this result, our theoretical analysis provides a unified theoretical justification for all these three methods.
1.1 Main Results
Let n1 = |{i : yi = 1}| and n2 = n − n1. The SDA estimator is obtained by solving the following least squares optimization problem
| (1.4) |
where [n] denotes the set {1,…, n}, x̄ = n−1Σi xi and the vector z ∈ ℝn encodes the class labels as zi = n2/n if yi = 1 and zi = −n1/n if yi = 2. Here λ > 0 is a regularization parameter.
The SDA estimator in (1.4) uses an ℓ1-norm penalty to estimate a sparse v and avoid the curse of dimensionality. Mai et al. (2012) studied its variable selection property under a different encoding scheme of the response zi. However, as we show later, different coding schemes do not affect the results. When the regularization parameter λ is set to zero, the SDA estimator reduces to the classical Fisher’s discriminant rule.
The main focus of the paper is to sharply characterize the variable selection performance of the SDA estimator. From a theoretical perspective, unlike the high dimensional regression setting where sharp theoretical results exist for prediction, estimation, and variable selection consistency, most existing theories for high-dimensional discriminant analysis are either on estimation consistency or risk consistency, but not on variable selection consistency (see, for example, Fan et al., 2012, Cai et al., 2011, Shao et al., 2011). Mai et al. (2012) provide a variable selection consistency result for the SDA estimator in (1.4). However, as we will show later, their obtained scaling in terms of (n, p, s) is not optimal. Though some theoretical analysis of the ℓ1-norm penalized M-estimators exists (see Wainwright (2009a), Negahban et al. (2012)), these techniques are not applicable to analyze the estimator given in (1.4). In high-dimensional discriminant analysis the underlying statistical model is fundamentally different from that of the regression analysis. At a high level, to establish variable selection consistency of the SDA estimator, we characterize the Karush-Kuhn-Tucker (KKT) conditions for the optimization problem in (1.4). Unlike the ℓ1-norm penalized least squares regression, which directly estimates the regression coefficients, the solution to (1.4) is a quantity that is only proportional to the Bayes rule’s direction . To analyze such scaled estimators, we need to resort to different techniques and utilize sophisticated multivariate analysis results to characterize the sampling distributions of the estimated quantities. More specifically, we provide sufficient conditions under which the SDA estimator is variable selection consistent with a significantly improved scaling compared to that obtained by Mai et al. (2012). In addition, we complement these sufficient conditions with information theoretic limitations on recovery of the feature set T. In particular, we provide lower bounds on the sample size and the signal level needed to recover the set of relevant variables by any procedure. We identify the family of problems for which the estimator (1.4) is variable selection optimal. To provide more insights into the problem, we analyze an exhaustive search procedure, which requires weaker conditions to consistently select relevant variables. This estimator, however, is not practical and serves only as a benchmark. The obtained variable selection consistency result also enables us to establish risk consistency for the SDA estimator. In addition, Mai and Zou (2012) show that the SDA estimator is numerically equivalent to the ROAD estimator proposed by Wu et al. (2009), Fan et al. (2012) and the sparse optimal scaling estimator proposed by Clemmensen et al. (2011). Therefore, the results provided in this paper also apply to those estimators. Some of the main results of this paper are summarized below.
Let v̂SDA denote the minimizer of (1.4). We show that if the sample size
| (1.5) |
where C is a fixed constant which does not scale with n, p and s, , and Λmin(Σ) denotes the minimum eigenvalue of Σ, then the estimated vector v̂SDA has the same sparsity pattern as the true β, thus establishing variable selection consistency (or sparsistency) for the SDA estimator. This is the first result that proves that consistent variable selection in the discriminant analysis can be done under a similar theoretical scaling as variable selection in the regression setting (in terms of n, p and s). To prove (1.5), we impose conditions that minj∈T |βj| is not too small and with α ∈ (0, 1), where N = [p]\T. The latter one is the irrepresentable condition, which is commonly used in the ℓ1-norm penalized least squares regression problem (Zou, 2006, Meinshausen and Bühlmann, 2006, Zhao and Yu, 2006, Wainwright, 2009a). Let βmin be the magnitude of the smallest absolute value of the non-zero component of β. Our analysis of information theoretic limitations reveals that, whenever , no procedure can reliably recover the set T. In particular, under certain regimes, we establish that the SDA estimator is optimal for the purpose of variable selection. The analysis of the exhaustive search decoder reveals a similar result. However, the exhaustive search decoder does not need the irrepresentable condition to be satisfied by the covariance matrix. Thorough numerical simulations are provided to demonstrate the sharpness of our theoretical results.
In a preliminary work, Kolar and Liu (2013) present some variable selection consistency results related to the ROAD estimator under the assumption that π1 = π2 = 1/2. However, it is hard to directly compare their analysis with that of Mai et al. (2012) to understand why an improved scaling is achievable, since the ROAD estimator is the solution to a constrained optimization while the SDA estimator is the solution to an unconstrained optimization. This paper analyzes the SDA estimator and is directly comparable with the result of Mai et al. (2012). As we will discuss later, our analysis attains better scaling due to a more careful characterization of the sampling distributions of several scaled statistics. In contrast, the analysis in Mai et al. (2012) hinges on the sup-norm control of the deviation of the sample mean and covariance to their population quantities, which is not sufficient to obtain the optimal rate. Using the numerical equivalence between the SDA and the ROAD estimator, the theoretical results of this paper also apply on the ROAD estimator. In addition, we also study an exhaustive search decoder and information theoretic limits on the variable selection in high-dimensional discriminant analysis. Furthermore, we provide discussions on risk consistency and approximate sparsity, which shed light on future investigations.
The rest of this paper is organized as follows. In the rest of this section, we introduce some more notation. In §2, we study sparsistency of the SDA estimator. An information theoretic lower bound is given in §3. We characterize the behavior of the exhaustive search procedure in §4. Consequences of our results are discussed in more details in §5. Numerical simulations that illustrate our theoretical findings are given in §6. We conclude the paper with a discussion and some results on the risk consistency and approximate sparsity in §7. Technical results and proofs are deferred to the appendix.
1.2 Notation
We denote [n] to be the set {1,…, n}. Let T ⊆ [p] be an index set, we denote βT to be the subvector containing the entries of the vector β indexed by the set T, and XT denotes the submatrix containing the columns of X indexed by T. Similarly, we denote ATT to be the submatrix of A with rows and columns indexed by T. For a vector a ∈ ℝn, we denote supp(a) = {j : aj ≠ 0} to be the support set. We also use ||a||q, q ∈ [1, ∞), to be the ℓq-norm defined as ||a||q = (Σi∈[n] |ai|q)1/q with the usual extensions for q ∈ {0, ∞}, that is, ||a||0 = |supp(a)| and ||a||∞ = maxi∈[n] |ai|. For a matrix A ∈ ℝn×p, we denote |||A|||∞ = maxi∈[n]Σj∈[p] |aij| the ℓ∞ operator norm. For a symmetric positive definite matrix A ∈ ℝp×p we denote Λmin(A) and Λmax(A) to be the smallest and largest eigenvalues, respectively. We also represent the quadratic form
for a symmetric positive definite matrix A. We denote In to be the n × n identity matrix and 1n to be the n × 1 vector with all components equal to 1. For two sequences {an} and {bn}, we use an =
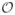 (bn) to denote that an < Cbn for some finite positive constant C. We also denote an =
(bn) to be bn ≳ an. If an =
(bn) and bn =
(an), we denote it to be an ≍ bn. The notation an = o(bn) is used to denote that
.
(bn) to denote that an < Cbn for some finite positive constant C. We also denote an =
(bn) to be bn ≳ an. If an =
(bn) and bn =
(an), we denote it to be an ≍ bn. The notation an = o(bn) is used to denote that
.
2 Sparsistency of the SDA Estimator
In this section, we provide sharp sparsistency analysis for the SDA estimator defined in (1.4). Our analysis decomposes into two parts: (i) We first analyze the population version of the SDA estimator in which we assume that Σ, μ1, and μ2 are known. The solution to the population problem provides us insights on the variable selection problem and allows us to write down sufficient conditions for consistent variable selection. (ii) We then extend the analysis from the population problem to the sample version of the problem in (1.4). For this, we need to replace Σ, μ1, and μ2 by their corresponding sample estimates Σ̂, μ̂1, and μ̂2. The statement of the main result is provided in §2.2 with an outline of the proof in §2.3.
2.1 Population Version Analysis of the SDA Estimator
We first lay out conditions that characterize the solution to the population version of the SDA optimization problem.
Let X1 ∈ ℝn1×p be the matrix with rows containing data points from the first class and similarly define X2 ∈ ℝn2×p to be the matrix with rows containing data points from the second class. We denote and to be the centering matrices. We define the following quantities
With this notation, observe that the optimization problem in (1.4) can be rewritten as
where we have dropped terms that do not depend on v. Therefore, we define the population version of the SDA optimization problem as
| (2.1) |
Let ŵ be the solution of (2.1). We are aiming to characterize conditions under which the solution ŵ recovers the sparsity pattern of β = Σ−1μ. Recall that T = supp(β) = {1,…, s} denotes the true support set and N = [p]\T, under the sparsity assumption, we have
| (2.2) |
We define βmin as
| (2.3) |
The following theorem characterizes the solution to the population version of the SDA optimization problem in (2.1).
Theorem 1
Let α ∈ (0, 1] be a constant and ŵ be the solution to the problem in (2.1). Under the assumptions that
| (2.4) |
| (2.5) |
we have with
| (2.6) |
Furthermore, we have sign(ŵT) = sign(βT).
Equations (2.4) and (2.5) provide sufficient conditions under which the solution to (2.1) recovers the true support. The condition in (2.4) takes the same form as the irrepresentable condition commonly used in the ℓ1-penalized least squares regression problem (Zou, 2006, Meinshausen and Bühlmann, 2006, Zhao and Yu, 2006, Wainwright, 2009a). Equation (2.5) specifies that the smallest component of βT should not be too small compared to the regularization parameter λ. In particular, let for some λ0. Then (2.5) suggests that ŵT recovers the true support of β as long as . Equation (2.6) provides an explicit form for the solution ŵ, from which we see that the SDA optimization procedure estimates a scaled version of the optimal discriminant direction. Whenever λ ≠ 0, ŵ is a biased estimator. However, such estimation bias does not affect the recovery of the support set T of β when λ is small enough.
We present the proof of Theorem 1, as the analysis of the sample version of the SDA estimator will follow the same lines. We start with the Karush-Kuhn-Tucker (KKT) conditions for the optimization problem in (2.1):
| (2.7) |
where ẑ ∈ ∂||ŵ||1 is an element of the subdifferential of ||·||1.
Let ŵT be defined in (2.6). We need to show that there exists a ẑ such that the vector , paired with ẑ, satisfies the KKT conditions and sign(ŵT) = sign(βT).
The explicit form of ŵT is obtained as the solution to an oracle optimization problem, specified in (2.8), where the solution is forced to be non-zero only on the set T. Under the assumptions of Theorem 1, the solution ŵT to the oracle optimization problem satisfies sign(ŵT) = sign(βT). We complete the proof by showing that the vector satisfies the KKT conditions for the full optimization procedure.
We define the oracle optimization problem to be
| (2.8) |
The solution w̃T to the oracle optimization problem (2.8) satisfies w̃T = ŵT where ŵT is given in (2.6). It is immediately clear that under the conditions of Theorem 1, sign (w̃T) = sign(βT).
The next lemma shows that the vector is the solution to the optimization problem in (2.1) under the assumptions of Theorem 1.
Lemma 2
Under the conditions of Theorem 1, we have that is the solution to the problem in (2.1), where ŵT is defined in (2.6).
This completes the proof of Theorem 1.
The next theorem shows that the irrepresentable condition in (2.4) is almost necessary for sign consistency, even if the population quantities Σ and μ are known.
Theorem 3
Let ŵ be the solution to the problem in (2.1). If we have sign(ŵT) = sign(βT), Then, there must be
| (2.9) |
The proof of this theorem follows similar argument as in the regression settings in Zhao and Yu (2006), Zou (2006).
2.2 Sample Version Analysis of the SDA Estimator
In this section, we analyze the variable selection performance of the sample version of the SDA estimator v̂ = v̂SDA defined in (1.4). In particular, we will establish sufficient conditions under which v̂ correctly recovers the support set of β (i.e., we will derive conditions under which and sign(v̂T) = sign(βT)). The proof construction follows the same line of reasoning as the population version analysis. However, proving analogous results in the sample version of the problem is much more challenging and requires careful analysis of the sampling distribution of the scaled functionals of Gaussian random vectors.
The following theorem is the main result that characterizes the variable selection consistency of the SDA estimator.
Theorem 4
We assume that the condition in (2.4) holds. Let the penalty parameter be with
| (2.10) |
where Kλ0 is a sufficiently large constant. Suppose that βmin = mina∈T |βa| satisfies
| (2.11) |
for a sufficiently large constant Kβ. If
| (2.12) |
for some constant K, then is the solution to the optimization problem in (1.4), where
| (2.13) |
with probability at least 1 −
(log−1(n)). Furthermore, sign(v̂T) = sign(βT).
Theorem 4 is a sample version of Theorem 1 given in the previous section. Compared to the population version result, in addition to the irrepresentable condition and a lower bound on βmin, we also need the sample size n to be large enough for the SDA procedure to recover the true support set T with high probability.
At the first sight, the conditions of the theorem look complicated. To highlight the main result, we consider a case where 0 < c ≤ Λmin(ΣTT) and for some constants c, C̄. In this case, it is sufficient that the sample size scales as n ≍ s log(p − s) and βmin ≳ s−1/2. This scaling is of the same order as for the Lasso procedure, where n ≳ s log(p − s) is needed for correct recovery of the relevant variables under the same assumptions (see Theorem 3 in Wainwright, 2009a). In §5, we provide more detailed explanation of this theorem and complement it with the necessary conditions given by the information theoretic limits.
Variable selection consistency of the SDA estimator was studied by Mai et al. (2012). Let C = Var(X) denote the marginal covariance matrix. Under the assumption that and ||μ||∞ are bounded, Mai et al. (2012) show that the following conditions
are sufficient for consistent support recovery of β. This is suboptimal compared to our results. Inspection of the proof given in Mai et al. (2012) reveals that their result hinges on uniform control of the elementwise deviation of Ĉ from C and μ̂ from μ. These uniform deviation controls are too rough to establish sharp results given in Theorem 4. In our proofs, we use more sophisticated multivariate analysis tools to control the deviation of from βT, that is, we focus on analyzing the quantity but instead of studying STT and μ̂T separately.
The optimization problem in (1.4) uses a particular scheme to encode class labels in the vector z, though other choices are possible as well. For example, suppose that we choose zi = z(1) if yi = 1 and zi = z(2) if yi = 2, with z(1) and z(2) such that n1z(1) + n2z(2) = 0. The optimality conditions for the vector to be a solution to (1.4) with the alternative coding are
| (2.14) |
| (2.15) |
Now, choosing , we obtain that w̃T̃, which satisfies (2.14) and (2.15), is proportional to ŵT with T̃ = T. Therefore, the choice of different coding schemes of the response variable zi does not effect the result.
The proof of Theorem 4 is outlined in the next subsection.
2.3 Proof of Sparsistency of the SDA Estimator
The proof of Theorem 4 follows the same strategy as the proof of Theorem 1. More specifically, we only need to show that there exists a subdifferential of ||·||1 such that the solution v̂ to the optimization problem in (1.4) satisfies the sample version KKT condition with high probability. For this, we proceed in two steps. In the first step, we assume that the true support set T is known and solve an oracle optimization problem to get ṽT which exploits the knowledge of T. In the second step, we show that there exists a dual variable from the subdifferential of ||·||1 such that the vector , paired with , satisfies the KKT conditions for the original optimization problem given in (1.4). This proves that is a global minimizer of the problem in (1.4). Finally, we show that v̂ is a unique solution to the optimization problem in (1.4) with high probability.
Let T̂ = supp(v̂) be the support of a solution v̂ to the optimization problem in (1.4) and T̂ = [p]\T̂. Any solution to (1.4) needs to satisfy the following Karush-Kuhn-Tucker (KKT) conditions
| (2.16) |
| (2.17) |
We construct a solution to (1.4) and show that it is unique with high probability.
First, we consider the following oracle optimization problem
| (2.18) |
The optimization problem in (2.18) is related to the one in (1.4), however, the solution is calculated only over the subset T and ||vT ||1 is replaced with . The solution can be computed in a closed form as
| (2.19) |
The solution ṽT is unique, since the matrix STT is positive definite with probability 1.
The following result establishes that the solution to the auxiliary oracle optimization problem (2.18) satisfies sign(ṽT) = sign(βT) with high probability, under the conditions of Theorem 4.
Lemma 5
Under the assumption that the conditions of Theorem 4 are satisfied, sign(ṽT) = sign(βT) and
with probability at least 1 −
(log−1(n)).
The proof Lemma 5 relies on a careful characterization of the deviation of the following quantities and from their expected values.
Using Lemma 5, we have that ṽT defined in (2.19) satisfies ṽT = v̂T. Next, we show that is a solution to (1.4) under the conditions of Theorem 4.
Lemma 6
Assuming that the conditions of Theorem 4 are satisfied, we have that
is a solution to (1.4) with probability at least 1 −
(log−1(n)).
The proof of Theorem 4 will be complete once we show that is the unique solution. We proceed as in the proof of Lemma 1 in Wainwright (2009a). Let v̌ be another solution to the optimization problem in (1.4) satisfying the KKT condition
for some subgradient q̂ ∈ ∂||v̌||1. Given the subgradient q̂, any optimal solution needs to satisfy the complementary slackness condition q̂′v̌ = ||v̌||1, which holds only if v̌j = 0 for all j such that |q̂j| < 1. In the proof of Lemma 6, we established that |q̂j| < 1 for j ∈ N. Therefore, any solution to (1.4) has the same sparsity pattern as v̂. Uniqueness now follows since ṽT is the unique solution of (2.18) when constrained on the support set T.
3 Lower Bound
Theorem 4 provides sufficient conditions for the SDA estimator to reliably recover the true set T of nonzero elements of the discriminant direction β. In this section, we provide results that are of complementary nature. More specifically, we provide necessary conditions that must be satisfied for any procedure to succeed in reliable estimation of the support set T. Thus, we focus on the information theoretic limits in the context of high-dimensional discriminant analysis.
We denote Ψ to be an estimator of the support set T, that is, any measurable function that maps the data {xi, yi}i∈[n] to a subset of {1, …, p}. Let θ = (μ1, μ2, Σ) be the problem parameters and Θ be the parameter space. We define the maximum risk, corresponding to the 0/1 loss, as
where
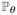 denotes the joint distribution of {xi, yi}i∈[n] under the assumption that
, and T(θ) = supp(β) (recall that β = Σ−1 (μ2 − μ1)). Let
denotes the joint distribution of {xi, yi}i∈[n] under the assumption that
, and T(θ) = supp(β) (recall that β = Σ−1 (μ2 − μ1)). Let
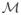 (s,
(s,
 ) be the class of all subsets of the set
of cardinality s. We consider the parameter space
) be the class of all subsets of the set
of cardinality s. We consider the parameter space
| (3.1) |
where τ > 0 determines the signal strength. The minimax risk is defined as
In what follows we provide a lower bound on the minimax risk. Before stating the result, we introduce the following three quantities that will be used to state Theorem 7
| (3.2) |
| (3.3) |
and
| (3.4) |
The first quantity measures the difficulty of distinguishing two close support sets T1 and T2 that differ in only one position. The second quantity measures the effect of a large number of support sets that are far from the support set T. The quantity τmin is a threshold for the signal strength. Our main result on minimax lower bound is presented in Theorem 7.
Theorem 7
For any τ < τmin, there exists some constant C > 0, such that
Theorem 7 implies that for any estimating procedure, whenever τ < τmin, there exists some distribution parametrized by θ ∈ Θ(Σ, τ, s) such that the probability of incorrectly identifying the set T(θ) is strictly bounded away from zero. To better understand the quantities φclose(Σ) and φfar(Σ), we consider a special case when Σ = I. In this case both quantities simplify a lot and we have φclose(I) = 2 and φfar(I) = 2s. From Theorem 7 and Theorem 4, we see that the SDA estimator is able to recover the true support set T using the optimal number of samples (up to an absolute constant) over the parameter space
where M is a fixed constant and Λmin(ΣTT) is bounded from below. This result will be further illustrated by numerical simulations in §6.
4 Exhaustive Search Decoder
In this section, we analyze an exhaustive search procedure, which evaluates every subset T′ of size s and outputs the one with the best score. Even though the procedure cannot be implemented in practice, it is a useful benchmark to compare against and it provides deeper theoretical insights into the problem.
For any subset T′ ⊂ [p], we define
The exhaustive search procedure outputs the support set T̂ that minimizes f(T′) over all subsets T′ of size s,
Define . In order to show that the exhaustive search procedure identifies the correct support set T, we need to show that with high probability g(T) > g(T′) for any other set T′ of size s. The next result gives sufficient conditions for this to happen. We first introduce some additional notation. Let A1 = T ∩ T′, A2 = T\T′ and A3 = T′\T. We define the following quantities
where and . The quantities μA3|A1 and ΣA3A3|A1are defined similarly.
Theorem 8
Assuming that for all T′ ⊆ [p] with |T′| = s and T′ ≠ T the following holds
| (4.1) |
where |T′ ∩ T| = k,
and C1, C2, C3
are constants independent of the problem parameters, we have
[T̂ ≠ T] =
(log−1(n)).
The condition in (4.1) allows the exhaustive search decoder to distinguish between the sets T and T′ with high probability. Note that the Mahalanobis distance decomposes as where and , and similarly . Therefore g(T) > g(T′) if . With infinite amount of data, it would be sufficient that a2(T′) > a3(T′). However, in the finite-sample setting, condition (4.1) ensures that the separation is big enough. If XT and XN are independent, then the expression (4.1) can be simplified by dropping the second term on the left hand side.
Compared to the result of Theorem 4, the exhaustive search procedure does not require the covariance matrix to satisfy the irrepresentable condition given in (2.4).
5 Implications of Our Results
In this section, we give some implications of our results. We start with the case when the covariance matrix Σ = I. The same implications hold for other covariance matrices that satisfy Λmin(Σ) ≥ C > 0 for some constant C independent of (n, p, s). We first illustrate a regime where the SDA estimator is optimal for the problem of identifying the relevant variables. This is done by comparing the results in Theorem 4 to those of Theorem 7. Next, we point out a regime where there exists a gap between the sufficient and necessary conditions of Theorem 7 for both the exhaustive search decoder and the SDA estimator. Throughout the section, we assume that s = o(min(n, p)).
When Σ = I, we have that βT = μT. Let
Theorem 7 gives a lower bound on μmin as
If some components of the vector μT are smaller in absolute value than μmin, no procedure can reliably recover the support. We will compare this bound with sufficient conditions given in Theorems 4 and 8.
First, we assume that for some constant C. Theorem 4 gives that is sufficient for the SDA estimator to consistently recover the relevant variables when n ≳ s log(p − s). This effectively gives μmin ≳ s−1/2, which is the same as the necessary condition of Theorem 7.
Next, we investigate the condition in (4.1), which is sufficient for the exhaustive search procedure to identify the set T. Let T′ ⊂ [p] be a subset of size s. Then, using the notation of Section 4,
Now, if |T′ ∩ T| = s − 1 and T′ does not contain a smallest component of μT, (4.1) simplifies to , since . This shows that both the SDA estimator and the exhaustive search procedure can reliably detect signals at the information theoretic limit in the case when the norm of the vector μT is bounded and μmin ≳ s−1/2. However, when the norm of the vector μT is not bounded by a constant, for example, μmin = C′ for some constant C′, Theorem 7 gives that at least n ≳ log(p − s) data points are needed, while n ≳ s log(p − s) is sufficient for correct recovery of the support set T. This situation is analogous to the known bounds on the support recovery in the sparse linear regression setting (Wainwright, 2009b).
Next, we show that the largest eigenvalue of a covariance matrix Σ can diverge, without affecting the sample size required for successful recovery of the support set T. Let for γ ∈ [0, 1). We have Λmax(Σ) = 1 + (p − 1)γ, which diverges to infinity for any fixed γ as p → ∞. Let T = [s] and set βT = β1T. This gives μT = β(1 + γ(s − 1))1T and μN = γβs1N. A simple application of the matrix inversion formula gives
A lower bound on β is obtained from Theorem 7 as . This follows from a simple calculation that establishes φclose(Σ) = 2(1 − γ) and φfar(Σ) = 2s(1 − γ) + (2s)2γ.
Sufficient conditions for the SDA estimator follow from Theorem 4. A straightforward calculation shows that
This gives that (for K large enough) is sufficient for recovering the set T, assuming that . This matches the lower bound, showing that the maximum eigenvalue of the covariance matrix Σ does not play a role in characterizing the behavior of the SDA estimator.
6 Simulation Results
In this section, we conduct several simulations to illustrate the finite-sample performance of our results. Theorem 4 describes the sample size needed for the SDA estimator to recover the set of relevant variables. We consider the following three scalings for the size of the set T:
fractional power sparsity, where s = ⌈2p0.45⌉
sublinear sparsity, where s = ⌈0.4p/log(0.4p)⌉, and
linear sparsity, where s = ⌈0.4p⌉.
For all three scaling regimes, we set the sample size as
where θ is a control parameter that is varied. We investigate how well can the SDA estimator recovers the true support set T as the control parameter θ varies.
We set
, X|Y = 1 ~
 (μ, Σ) and without loss of generality X|Y = 2 ~
(0, Σ). We specify the vector μ by choosing the set T of size |T| = s randomly, and for each a ∈ T setting μa equal to +1 or −1 with equal probability, and μa = 0 for all components a ∉ T. We specify the covariance matrix Σ as
(μ, Σ) and without loss of generality X|Y = 2 ~
(0, Σ). We specify the vector μ by choosing the set T of size |T| = s randomly, and for each a ∈ T setting μa equal to +1 or −1 with equal probability, and μa = 0 for all components a ∉ T. We specify the covariance matrix Σ as
so that . We consider three cases for the block component ΣTT:
identity matrix, where ΣTT = Is,
Toeplitz matrix, where ΣTT = [Σab]a,b∈T and Σab = ρ|a−b| with ρ = 0.1, and
equal correlation matrix, where Σab = ρ when a ≠ b and σaa = 1.
Finally, we set the penalty parameter λ = λSDA as
for all cases. We also tried several different constants and found that our main results on high dimensional scalings are insensitive to the choice of this constant. For this choice of λ, Theorem 4 predicts that the set T will be recovered correctly. For each setting, we report the Hamming distance between the estimated set T̂ and the true set T,
averaged over 200 independent simulation runs.
Figure 1 plots the Hamming distance against the control parameter θ, or the rescaled number of samples. Here the Hamming distance between T̂ and T is calculated by averaging 200 independent simulation runs. There are three subfigures corresponding to different sparsity regimes (fractional power, sublinear and linear sparsity), each of them containing three curves for different problem sizes p ∈ {100, 200, 300}. Vertical line indicates a threshold parameter θ at which the set T is correctly recovered. If the parameter is smaller than the threshold value, the recovery is poor. Figure 2 and Figure 3 show results for two other cases, with ΣTT being a Toeplitz matrix with parameter ρ = 0.1 and the equal correlation matrix with ρ = 0.1. To illustrate the effect of correlation, we set p = 100 and generate the equal correlation matrices with ρ ∈ {0, 0.1, 0.3, 0.5, 0.7, 0.9}. Results are given in Figure 4.
Figure 1.
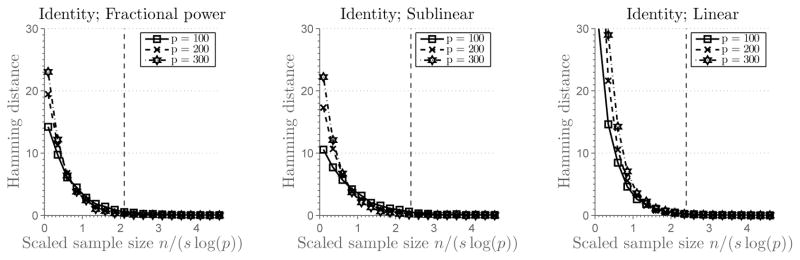
(The SDA Estimator) Plots of the rescaled sample size n/(s log(p)) versus the Hamming distance between T̂ and T for identity covariance matrix Σ = Ip (averaged over 200 simulation runs). Each subfigure shows three curves, corresponding to the problem sizes p ∈ {100, 200, 300}. The first subfigure corresponds to the fractional power sparsity regime, s = 2p0.45, the second subfigure corresponds to the sublinear sparsity regime s = 0.4p/log(0.4p), and the third ssubfigure corresponds to the linear sparsity regime s = 0.4p. Vertical lines denote a scaled sample size at which the support set T is recovered correctly.
Figure 2.
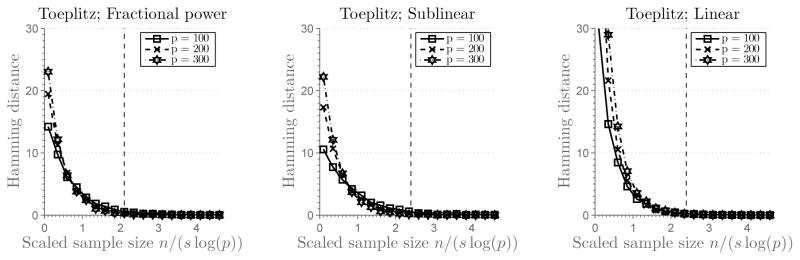
(The SDA Estimator) Plots of the rescaled sample size n/(s log(p)) versus the Hamming distance between T̂ and T for the Toeplitz covariance matrix ΣTT with ρ = 0.1 (averaged over 200 simulation runs). Each subfigure shows three curves, corresponding to the problem sizes p ∈ {100, 200, 300}. The first subfigure corresponds to the fractional power sparsity regime, s = 2p0.45, the second subfigure corresponds to the sublinear sparsity regime s = 0.4p/log(0.4p), and the third subfiguren corresponds to the linear sparsity regime s = 0.4p. Vertical lines denote a scaled sample size at which the support set T is recovered correctly.
Figure 3.
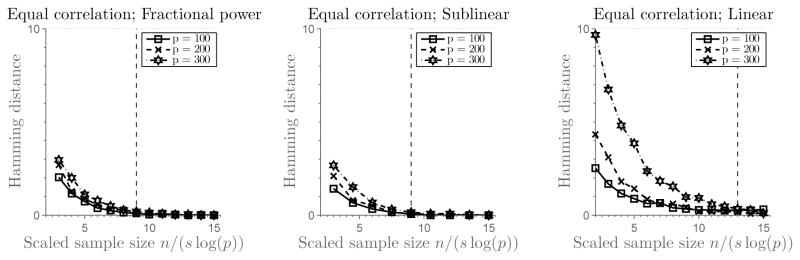
(The SDA Estimator) Plots of the rescaled sample size n/(s log(p)) versus the Hamming distance between T̂ and T for equal correlation matrix ΣTT with ρ = 0.1 (averaged over 200 simulation runs). Each subfigure shows three curves, corresponding to the problem sizes p ∈ {100, 200, 300}. The first subfigure corresponds to the fractional power sparsity regime, s = 2p0.45, the second subfigure corresponds to the sublinear sparsity regime s = 0.4p/log(0.4p), and the third subfigure corresponds to the linear sparsity regime s = 0.4p. Vertical lines denote a scaled sample size at which the support set T is recovered correctly.
Figure 4.
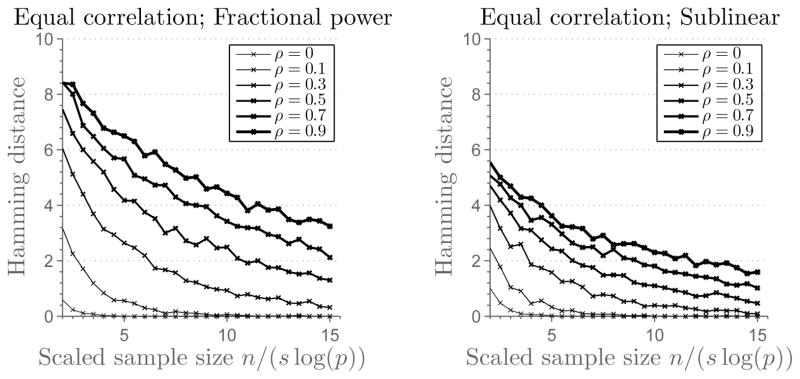
(The SDA Estimator) Plots of the rescaled sample size n/(s log(p)) versus the Hamming distance between T̂ and T for equal correlation matrix ΣTT with ρ ∈ {0, 0.1, 0.3, 0.5, 0.7, 0.9} (averaged over 200 simulation runs). The ambient dimension is set as p = 100. The first subfigure corresponds to the fractional power sparsity regime, s = 2p0.45 and the second subfigure corresponds to the sublinear sparsity regime s = 0.4p/log(0.4p).
7 Discussion
In this paper, we address the problem of variable selection in high-dimensional discriminant analysis problem. The problem of reliable variable selection is important in many scientific areas where simple models are needed to provide insights into complex systems. Existing research has focused primarily on establishing results for prediction consistency, ignoring feature selection. We bridge this gap, by analyzing the variable selection performance of the SDA estimator and an exhaustive search decoder. We establish sufficient conditions required for successful recovery of the set of relevant variables for these procedures. This analysis is complemented by analyzing the information theoretic limits, which provide necessary conditions for variable selection in discriminant analysis. From these results, we are able to identify the class of problems for which the computationally tractable procedures are optimal. In this section, we discuss some implications and possible extensions of our results.
7.1 Theoretical Justification of the ROAD and Sparse Optimal Scaling Estimators
In a recent work, Mai and Zou (2012) show that the SDA estimator is numerically equivalent to the ROAD estimator proposed by Wu et al. (2009), Fan et al. (2012) and the sparse optimal scaling estimator proposed by Clemmensen et al. (2011). More specifically, all these three methods have the same regularization paths up to a constant scaling. This result allows us to apply the theoretical results in this paper to simultaneously justify the optimal variable selection performance of the ROAD and sparse optimal scaling estimators.
7.2 Risk Consistency
The results of Theorem 4 can be used to establish risk consistency of the SDA estimator. Consider the following classification rule
| (7.1) |
where g(x; v̂) = I[v̂′ (x − (μ̂1 + μ̂2)/2) > 0] with v̂ = v̂SDA. Under the assumption that β = (βT′, 0′)′, the risk (or the error rate) of the Bayes rule defined in (1.1) is , where Φ is the cumulative distribution function of a standard Normal distribution. We will compare the risk of the SDA estimator against this Bayes risk.
Recall the setting introduced in §1.1, conditioning on the data points {xi, yi}i∈[n], the conditional error rate is
| (7.2) |
Let rn = λ||βT||1 and qn = sign(βT)′ΣTT sign(βT). We have the following result on risk consistency.
Corollary 9
Let v̂ = v̂SDA. We assume that the conditions of Theorem 4 hold with
| (7.3) |
where K(n) could potentially scale with n, and . Furthermore, we assume that . Then
First, note that is sufficient for . Under the conditions of Theorem 9, we have that . Therefore, if and we have
and R(ŵ) − Ropt →P 0. If in addition
then R(ŵ)/Ropt →P 1, using Lemma 1 in Shao et al. (2011).
The above discussion shows that the conditions of Theorem 4 are sufficient for establishing risk consistency. We conjecture that substantially less restrictive conditions are needed to establish risk consistency results. Exploring such weaker conditions is beyond the scope of this paper.
7.3 Approximate sparsity
Thus far, we were discussing estimation of discriminant directions that are exactly sparse. However, in many applications it may be the case that the discriminant direction is only approximately sparse, that is, βN is not equal to zero, but is small. In this section, we briefly discuss the issue of variable selection in this context.
In the approximately sparse setting, since βN ≠ 0, a simple calculation gives
| (7.4) |
and
| (7.5) |
In what follows, we provide conditions under which the solution to the population version of the SDA estimator, given in (2.1), correctly recovers the support of large entries T. Let where ŵT is given as
with . We will show that ŵ is the solution to (2.1).
We again define βmin = mina∈T|βa|. Following a similar argument as the proof of Theorem 1, we have that holds if satisfies
| (7.6) |
In the approximate sparsity setting, it is reasonable to assume that is small compared to , which would imply that using (7.4). Therefore, under suitable assumptions we have sign(ŵT) = sign(βT). Next, we need conditions under which ŵ is the solution to (2.1).
Following a similar analysis as in Lemma 2, the optimality condition
needs to hold. Let . Using (7.5), the above display becomes
Therefore, using the triangle inequality, the following assumption
in addition to (2.4) and (7.6), is sufficient for ŵ to recover the set of important variables T.
The above discussion could be made more precise and extended to the sample SDA estimator in (1.4), by following the proof of Theorem 4. This is beyond the scope of the current paper and will be left as a future investigation.
A Proofs Of Main Results
In this section, we collect proofs of results given in the main text. We will use C, C1, C2, … to denote generic constants that do not depend on problem parameters. Their values may change from line to line.
Let
| (A.1) |
where
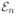 is defined in (C.1),
is defined in (C.1),
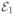 in Lemma 10,
in Lemma 10,
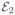 in Lemma 11,
in Lemma 11,
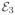 in (C.8), and
in (C.8), and
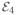 in (C.9). We have that
[
in (C.9). We have that
[
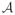 ] ≥ 1 −
log−1(n)).
] ≥ 1 −
log−1(n)).
A.1 Proofs of Results in Section 2
Proof of Lemma 2
From the KKT conditions given in (2.7), we have that is a solution to the problem in (2.1) if and only if
| (A.2) |
By construction, ŵT satisfy the first equation. Therefore, we need to show that the second one is also satisfied. Plugging in the explicit form of ŵT into the second equation and using (2.2), after some algebra we obtain that
needs to be satisfied. The above display is satisfied with strict inequality under the assumption in (2.4).
Proof of Lemma 5
Throughout the proof, we will work on the event
defined in (A.1).
Let a ∈ T be such that ṽa > 0, noting that the case when ṽa < 0 can be handled in a similar way. Let
Furthermore, let
For sufficiently large n, on the event
, together with Lemma 12, Lemma 16, and Lemma 13, we have that γ̂ ≥ γ(1 − o(1)) > γ/2 and
with probability at least 1 −
(log−1(n). Then
so that sign(ṽa) = sign(βa) if
| (A.3) |
Lemma 15 gives a bound on |δ2|, for each fixed a ∈ T, as
Therefore assumption (2.11), with Kβ sufficiently large, and a union bound over all a ∈ T implies (A.3).
Lemma 15 gives sign(βT) = sign(βT) with probability 1 −
(log−1(n)).
Proof of Lemma 6
Throughout the proof, we will work on the event
defined in (A.1). By construction, the vector
satisfies the condition in (2.16). Therefore, to show that it is a solution to (1.4), we need to show that it also satisfies (2.17).
To simplify notation, let
Recall that .
Let U ∈ ℝ(n−2)×p be a matrix with each row such that (n − 2)S = U′U. For a ∈ N, we have
where is independent of UT, and
where is independent of μ̂T. Therefore,
and finally
First, we deal with the term
Conditional on {yi}i∈[n] and XT, we have that
and
with probability at least 1 − log−1(n). On the event
, we have that
Since
and
we have that
by taking both Kλ0 and K sufficiently large.
Similarly, conditional on {yi}i∈[n] and XT, we have that
which, on the event
, gives
with probability at least 1 − log−1(n) for sufficiently large K.
Next, let
Simple algebra shows that
Therefore conditional on {yi}i∈[n] and XT, we have that
which, on the event
, gives
with probability at least 1 − log−1(n) when Kλ0 and K are chosen sufficiently large.
Piecing all these results together, we have that
A.2 Proof of Theorem 7
The theorem will be shown using standard tools described in Tsybakov (2009). First, in order to provide a lower bound on the minimax risk, we will construct a finite subset of Θ(Σ, τ, s), which contains the most difficult instances of the estimation problem so that estimation over the subset is as difficult as estimation over the whole family. Let Θ1 ⊂ Θ(Σ, τ, s), be a set with finite number of elements, so that
To further lower bound the right hand side of the display above, we will use Theorem 2.5 in Tsybakov (2009). Suppose that Θ1 = {θ0, θ1, …, θM} where T (θa) ≠ T (θb) and
| (A.4) |
then
Without loss of generality, we will consider θa = (μa, 0, Σ). Denote
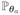 the joint distributions of {Xi, Yi}i∈[n]. Under
, we have
, Xi|Yi = 1 ~
(0, Σ) and Xi|Yi = 2 ~
(μa, Σ). Denote f (x; μ, Σ) the density function of a multivariate Normal distribution. With this we have
the joint distributions of {Xi, Yi}i∈[n]. Under
, we have
, Xi|Yi = 1 ~
(0, Σ) and Xi|Yi = 2 ~
(μa, Σ). Denote f (x; μ, Σ) the density function of a multivariate Normal distribution. With this we have
| (A.5) |
where βa = Σ−1μa. We proceed to construct different finite collections for which (A.4) holds.
Consider a collection Θ1 = {θ0, θ1, …, θp−s}, with θa = (μa, 0), that contains instances whose supports differ in only one component. Vectors are constructed indirectly through , using the relationship βa = Σ−1μa. Note that this construction is possible, since Σ is a full rank matrix. For every a, all s non-zero elements of the vector βa are equal to τ. Let T be the support and u(T) an element of the support T for which (3.2) is minimized. Set β0 so that supp(β0) = T. The remaining p–s parameter vectors are constructed so that the support of βa contains all s − 1 element in T\u(T) and then one more element from [p]\T. With this, (A.5) gives
and (3.2) gives
It follows from the display above that if
| (A.6) |
then (A.4) holds with α = 1/16.
Next, we consider another collection Θ2 = {θ0, θ1, …, θM}, where , and the Hamming distance between T (θ0) and T (θa) is equal to 2s. As before, θa = (μa, 0) and vectors are constructed so that βa = Σ−1 μa with s non-zero components equal to τ. Let T be the support set for which the minimum in (3.3) is attained. Set the vector β0 so that supp(β0) = T. The remaining vectors are set so that their support contains s elements from the set [p]\T. Now, (A.5) gives
Using (3.3), if
| (A.7) |
then (A.4) holds with α = 1/16.
Combining (A.6) and (A.7), by taking the larger β between the two, we obtain the result.
A.3 Proof of Theorem 8
For a fixed T, let Δ(T′) = f(T) − f(T′) and
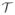 = {T′ ⊂ [p]: |T′| = s, T′ ≠ T}. Then
= {T′ ⊂ [p]: |T′| = s, T′ ≠ T}. Then
Partition , where μ̂1 contains the variables in T ∩ T′, and . Similarly, we can partition the covariance matrix STT and ST′T′. Then,
where and (see Section 3.6.2 in Mardia et al., 1979). Furthermore, we have that
| (A.8) |
The two terms are correlated, but we will ignore this correlation and use the union bound to lower bound the first term and upper bound the second term. We start with analyzing , noting that the result for the second term will follow in the same way. By Theorem 3.4.5 in Mardia et al. (1979), we have that
and independent of (S12, S11, μ̂). Therefore S22|1 is independent of μ̃2|1 and Theorem 3.2.12 in Muirhead (1982) gives us that
As in Lemma 10, we can show that
For μ̃2|1, we have
where , independent of μ̂1, and . Conditioning on μ̂1 and S1, we have that
where . Since μ̂2|1 is independent of (S12, S11, μ̂1), we have that
Let . Then
Therefore, conditioned on (μ̂1, S11),
with probability 1 − 2η. Similarly,
with probability 1 − 2η. Finally, Lemma 12 gives that with probability 1 − 2η.
Set . For any T′ ⊂ [p], where |T′| = s and |T′ ∩ T | = k, we have that
The right hand side in the above display is bounded away from zero with probability under the assumptions. Therefore,
which completes the proof.
B Proof of Risk Consistency
In this section, we give a proof of Corollary 9. From Theorem 4 we have that with v̂T defined in (2.13). Define
To obtain a bound on the risk, we need to control
| (B.1) |
for i ∈ {1, 2}. Define the following quantities
Under the assumptions, we have that
The last equation follows from Lemma 12. Note that δ̃2 =
(rn). From Lemma 13, we have that δ̃1 = op(1).
We have , since Lemma 13 gives δ̃1 = op(1), and
Therefore . With this, we have
| (B.2) |
where the last line follows from . Next
and similarly
Combining these two estimates, we have
| (B.3) |
From (B.2) and (B.3), we have that
| (B.4) |
Finally, a simple calculation gives,
| (B.5) |
Combining the equation (B.4) and (B.5), we have that
This completes the proof.
C Technical Results
We provide some technical lemmas which are useful for proving the main results. Without loss of generality, π1 = π2 = 1/2 in model (1.2). Define
| (C.1) |
where n1, n2 are defined in §1. Observe that n1 ~ Binomial(n, 1/2), which gives
[{n1 ≤ n/4}] ≤ exp(−3n/64) and
[{n1 ≥ 3n/4}] ≤ exp(−3n/64) using standard tail bound for binomial random variable (Devroye et al., 1996, p. 130). Therefore
| (C.2) |
The analysis is performed by conditioning on y and, in particular, we will perform analysis on the event
. Note that on
, 16/9n−1 ≤ n/(n1n2) ≤ 16n−1. In our analysis, we do not strive to obtain the sharpest possible constants.
C.1 Deviation of the Quadratic Scaling Term
In this section, we collect lemmas that will help us deal with bounding the deviation of from .
Lemma 10
Define the event
| (C.3) |
for some constants C1, C2 > 0. Assume that s = o(n), then
[
(η)] ≥ 1 − η for n sufficiently large.
Proof of Lemma 10
Using Theorem 3.2.12 in Muirhead (1982)
(D.4) gives
with probability at least 1 − η. Since s = o(n), the above display becomes
| (C.4) |
for n sufficiently large.
Lemma 11
Define the event
| (C.5) |
Assume that βmin ≥ cn−1/2, then
[
(η)] ≥ 1 − 2η for n sufficiently large.
Proof of Lemma 11
Recall that . Therefore
Using (D.5), we have that
| (C.6) |
with probability 1 − η. The second inequality follows since we are working on the event
, and the third inequality follows from the fact that βmin ≥ cn−1/2. A lower bound follows from (D.6),
| (C.7) |
with probability 1 − η.
Lemma 12
On the event
(η) ∩
(η) the following holds
Proof of Lemma 12
On the event
(η) ∩
(η), using Lemma 10 and Lemma 11, we have that
A lower bound is obtained in the same way.
C.2 Other Results
Let the event
(η) be defined as
| (C.8) |
Since
is a multivariate normal with mean
and variance
, we have
[
(η)] ≥ 1 − η.
Furthermore, define the event
(η) as
| (C.9) |
Since
, we have
[
(η)] ≥ 1 − η.
The next result gives a deviation of from .
Lemma 13
The following inequality
| (C.10) |
holds with probability at least 1 −
(log−1(n)).
Proof
Using the triangle inequality
| (C.11) |
For the first term, we write
| (C.12) |
Let
and
Using Theorem 3 of Bodnar and Okhrin (2008), we compute the density of conditional on μ̂T and obtain that
where
Lemma 20 gives
with probability at least 1 − log−1(n). Combining with Lemma 14, Lemma 11, and (C.9), we obtain an upper bound on the RHS of (C.12) as
| (C.13) |
with probability at least 1 −
(log−1(n)).
The second term in (C.11) can be bounded using (C.9) with η = log−1(n). Therefore, combining with (C.13), we obtain
| (C.14) |
with probability at least 1 −
(log−1(n)), as desired.
Lemma 14
There exist constants C1, C2, C3, and C4 such that each of the following inequalities hold with probability at least 1 − log−1(n):
| (C.15) |
| (C.16) |
| (C.17) |
| (C.18) |
Proof
Theorem 3.2.12. in Muirhead (1982) states that
Using Equation (D.4),
with probability 1 − (2s log(n))−1. Rearranging terms in the display above, we have that
and
A union bound gives (C.15) and (C.16).
Equations (C.17) and (C.18) are shown similarly.
Lemma 15
There exist constants C1, C2 > 0 such that the following inequality
| (C.19) |
holds with probability at least 1 −
(log−1(n)).
Proof
Using the triangle inequality, we have
| (C.20) |
For the first term, we write
| (C.21) |
As in the proof of Lemma C.10, we can show that
where
Lemma 20 and an application of union bound gives
with probability at least 1 −
(log−1(n)). Combining Lemma 11, Lemma 14 and Equation (C.8) with η = log−1(n), we can bound the right hand side of (C.21) as
| (C.22) |
with probability at least 1 −
(log−1(n)).
The second term in (C.20) is handled by (C.8) with η = log−1(n). Combining with (C.22), we obtain
| (C.23) |
with probability at least 1 −
(log−1(n)). This completes the proof.
Lemma 16
The probability of the event
is at least 1 − 2log−1(n) for n sufficiently large.
Proof
Write
| (C.24) |
As in the proof of Lemma C.10, we can show that
where
Therefore,
| (C.25) |
with probability 1 − (s log(n))−1. Combining Lemma 14 and (C.25), we can bound the right hand side of Equation (C.24) as
where the second inequality follows from
An application of the union bound gives the desired result.
D Tail Bounds For Certain Random Variables
In this section, we collect useful results on tail bounds of various random quantities used throughout the paper. We start by stating a lower and upper bound on the survival function of the standard normal random variable. Let Z ~
(0, 1) be a standard normal random variable. Then for t > 0
| (D.1) |
Next, we collect results concerning tail bounds for central χ2 random variables.
Lemma 17 (Laurent and Massart (2000))
Let . For all x ≥ 0,
| (D.2) |
| (D.3) |
Lemma 18 (Johnstone and Lu (2009))
Let , then
| (D.4) |
The following result provides a tail bound for non-central χ2 random variable with non-centrality parameter ν.
Lemma 19 (Birgé (2001))
Let , then for all x > 0
| (D.5) |
| (D.6) |
The following Lemma gives a tail bound for a t-distributed random variable.
Lemma 20
Let X be a random variable distributed as
where td denotes a t-distribution with d degrees of freedom. Then
with probability at least 1 − η.
Proof
Let Y ~
(0, 1) and
be two independent random variables. Then X is equal in distribution to
Using (D.1),
with probability at least 1 − η/2. (D.4) gives
with probability at least 1 − η/2. Therefore, for sufficiently large d,
Contributor Information
Mladen Kolar, Email: mladenk@cs.cmu.edu.
Han Liu, Email: hanliu@princeton.edu.
References
- Anderson TW. Wiley Series in Probability and Statistics. 3. Wiley-Interscience [John Wiley & Sons]; Hoboken, NJ: 2003. An introduction to multivariate statistical analysis. [Google Scholar]
- Bickel Peter J, Levina Elizaveta. Some theory of Fisher’s linear discriminant function, ‘naive Bayes’, and some alternatives when there are many more variables than observations. Bernoulli. 2004;10(6):989–1010. doi: 10.3150/bj/1106314847. URL http://dx.doi.org/10.3150/bj/1106314847. [DOI] [Google Scholar]
- Birgé Lucien. State of the art in probability and statistics (Leiden, 1999), volume 36 of IMS Lecture Notes Monogr. Ser. Inst. Math. Statist; Beachwood, OH: 2001. An alternative point of view on Lepski’s method; pp. 113–133. URL http://dx.doi.org/10.1214/lnms/1215090065. [DOI] [Google Scholar]
- Bodnar Taras, Okhrin Yarema. Properties of the singular, inverse and generalized inverse partitioned Wishart distributions. J Multivariate Anal. 2008;99(10):2389–2405. doi: 10.1016/j.jmva.2008.02.024. URL http://dx.doi.org/10.1016/j.jmva.2008.02.024. [DOI] [Google Scholar]
- Cai Tony, Liu Weidong, Luo Xi. A constrained ℓ1 minimization approach to sparse precision matrix estimation. J Amer Statist Assoc. 2011;106(494):594–607. doi: 10.1198/jasa.2011.tm10155. URL http://dx.doi.org/10.1198/jasa.2011.tm10155. [DOI] [Google Scholar]
- Clemmensen Line, Hastie Trevor, Witten Daniela, Ersbøll Bjarne. Sparse discriminant analysis. Technometrics. 2011;53(4):406–413. doi: 10.1198/TECH.2011.08118. URL http://dx.doi.org/10.1198/TECH.2011.08118. [DOI] [Google Scholar]
- Devroye Luc, Györfi László, Lugosi Gábor. A probabilistic theory of pattern recognition, volume 31 of Applications of Mathematics (New York) Springer-Verlag; New York: 1996. [Google Scholar]
- Fan Jianqing, Fan Yingying. High-dimensional classification using features annealed independence rules. Ann Statist. 2008;36(6):2605–2637. doi: 10.1214/07-AOS504. URL http://dx.doi.org/10.1214/07-AOS504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan Jianqing, Feng Yang, Tong Xin. A road to classification in high dimensional space: the regularized optimal affine discriminant. J R Stat Soc Ser B Stat Methodol. 2012;74(4):745–771. doi: 10.1111/j.1467-9868.2012.01029.x. URL http://dx.doi.org/10.1111/j.1467-9868.2012.01029.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnstone Iain M, Lu Arthur Yu. On consistency and sparsity for principal components analysis in high dimensions. J Amer Statist Assoc. 2009;104(486):682–693. doi: 10.1198/jasa.2009.0121. URL http://dx.doi.org/10.1198/jasa.2009.0121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kolar Mladen, Liu Han. Feature selection in high-dimensional classification. JMLR W&CP: Proceedings of The 30th International Conference on Machine Learning; 2013. pp. 100–108. [Google Scholar]
- Laurent B, Massart P. Adaptive estimation of a quadratic functional by model selection. Ann Statist. 2000;28(5):1302–1338. doi: 10.1214/aos/1015957395. URL http://dx.doi.org/10.1214/aos/1015957395. [DOI] [Google Scholar]
- Mai Qing, Zou Hui. A note on the connection and equivalence of three sparse linear discriminant analysis methods. Technometrics. 2012 (just-accepted) [Google Scholar]
- Mai Qing, Zou Hui, Yuan Ming. A direct approach to sparse discriminant analysis in ultra-high dimensions. Biometrika. 2012;99(1):29–42. doi: 10.1093/biomet/asr066. URL http://dx.doi.org/10.1093/biomet/asr066. [DOI] [Google Scholar]
- Mardia Kantilal Varichand, Kent John T, Bibby John M. Multivariate analysis. Academic Press [Harcourt Brace Jovanovich Publishers]; London: 1979. Probability and Mathematical Statistics: A Series of Monographs and Textbooks. [Google Scholar]
- Meinshausen Nicolai, Bühlmann Peter. High-dimensional graphs and variable selection with the lasso. Ann Statist. 2006;34(3):1436–1462. doi: 10.1214/009053606000000281. URL http://dx.doi.org/10.1214/009053606000000281. [DOI] [Google Scholar]
- Muirhead Robb J. Aspects of multivariate statistical theory. John Wiley & Sons Inc; New York: 1982. Wiley Series in Probability and Mathematical Statistics. [Google Scholar]
- Negahban Sahand N, Ravikumar Pradeep, Wainwright Martin J, Yu Bin. A unified framework for high-dimensional analysis of m-estimators with decomposable regularizers. Statistical Science. 2012;27(4):538–557. [Google Scholar]
- Shao Jun, Wang Yazhen, Deng Xinwei, Wang Sijian. Sparse linear discriminant analysis by thresholding for high dimensional data. Ann Statist. 2011;39(2):1241–1265. doi: 10.1214/10-AOS870. URL http://dx.doi.org/10.1214/10-AOS870. [DOI] [Google Scholar]
- Tibshirani Robert, Hastie Trevor, Narasimhan Balasubramanian, Chu Gilbert. Class prediction by nearest shrunken centroids, with applications to DNA microarrays. Statist Sci. 2003;18(1):104–117. doi: 10.1214/ss/1056397488. URL http://dx.doi.org/10.1214/ss/1056397488. [DOI] [Google Scholar]
- Tsybakov Alexandre B. Springer Series in Statistics. Springer; New York: 2009. Introduction to nonparametric estimation. URL http://dx.doi.org/10.1007/b13794. Revised and extended from the 2004 French original, Translated by Vladimir Zaiats. [DOI] [Google Scholar]
- Wainwright Martin J. Sharp thresholds for high-dimensional and noisy sparsity recovery using ℓ1-constrained quadratic programming (Lasso) IEEE Trans Inform Theory. 2009a;55(5):2183–2202. doi: 10.1109/TIT.2009.2016018. URL http://dx.doi.org/10.1109/TIT.2009.2016018. [DOI] [Google Scholar]
- Wainwright Martin J. Information-theoretic limits on sparsity recovery in the high-dimensional and noisy setting. IEEE Trans Inform Theory. 2009b;55(12):5728–5741. doi: 10.1109/TIT.2009.2032816. URL http://dx.doi.org/10.1109/TIT.2009.2032816. [DOI] [Google Scholar]
- Wang S, Zhu J. Improved centroids estimation for the nearest shrunken centroid classifier. Bioinformatics. 2007;23(8):972. doi: 10.1093/bioinformatics/btm046. [DOI] [PubMed] [Google Scholar]
- Witten Daniela M, Tibshirani Robert. Covariance-regularized regression and classification for high dimensional problems. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2009 Jun;71(3):615–636. doi: 10.1111/j.1467-9868.2009.00699.x. URL http://dx.doi.org/10.1111/j.1467-9868.2009.00699.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Witten Daniela M, Tibshirani Robert. Penalized classification using Fisher’s linear discriminant. J R Stat Soc Ser B Stat Methodol. 2011;73(5):753–772. doi: 10.1111/j.1467-9868.2011.00783.x. URL http://dx.doi.org/10.1111/j.1467-9868.2011.00783.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wu Michael C, Zhang Lingsong, Wang Zhaoxi, Christiani David C, Lin Xihong. Sparse linear discriminant analysis for simultaneous testing for the significance of a gene set/pathway and gene selection. Bioinformatics. 2009;25(9):1145–1151. doi: 10.1093/bioinformatics/btp019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Peng, Yu Bin. On model selection consistency of Lasso. J Mach Learn Res. 2006;7:2541–2563. [Google Scholar]
- Zou Hui. The adaptive lasso and its oracle properties. J Amer Statist Assoc. 2006;101(476):1418–1429. doi: 10.1198/016214506000000735. URL http://dx.doi.org/10.1198/016214506000000735. [DOI] [Google Scholar]