
Figure 1.
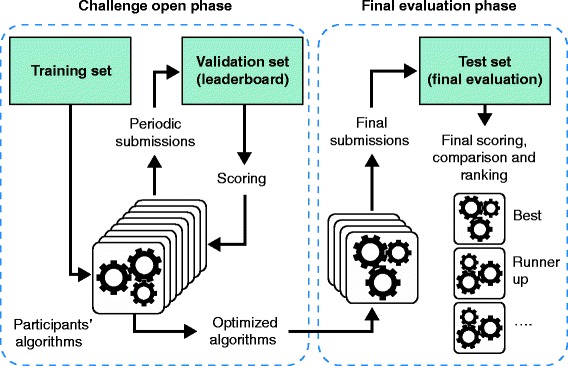
Typical design of a crowd-sourced challenge. A dataset is split into a training set, a validation (or leaderboard set) and the test set (or gold standard). Participants have access to the challenge input data and the known answers for just the training set. For the validation and test sets only, the challenge input data are provided but the answers to the challenge questions are withheld. In the challenge open phase, participants optimize their algorithms by making repeated submissions to predict the validation set answers. These submissions are scored and returned to the participants who can use the information to improve their methods. In the final evaluation phase, the optimized algorithms are submitted and evaluated against the final test set (the gold standard), and the resulting scores are used to compute the statistical significance and the ranking of the participating algorithms.