
Figure 2.
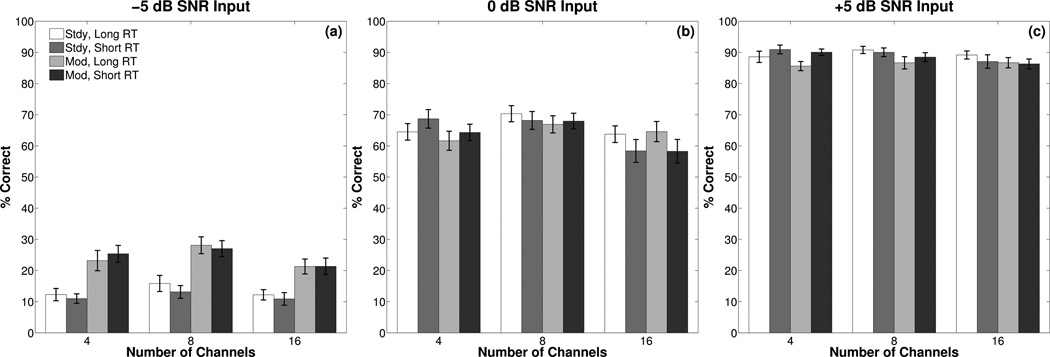
Mean percent correct recognition of keywords in the IEEE sentences for each condition. Each panel shows results for one input SNR. Bars are grouped by number of channels. Recognition in the presence of the steady masker is shown by the first pair of bars in each group and recognition in the presence of the modulated masker is shown by the second pair bars in each group. Lighter-shaded bars represent the long RTs and darker-shaded bars represent the short RTs. In this and later figures, error bars represent the standard error of the mean.