
Figure 7.
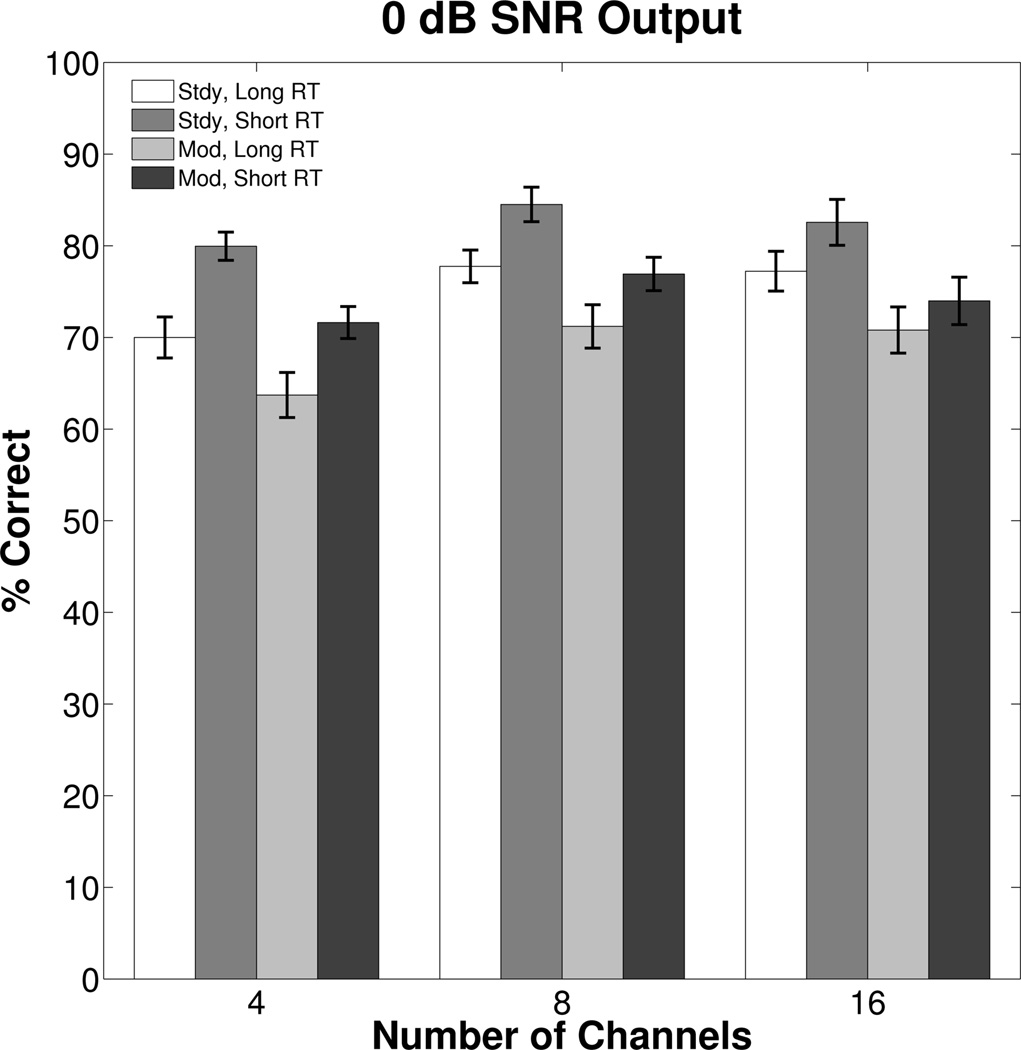
Derived mean percent correct for speech recognition when output SNR was fixed at 0 dB for each condition and listener. The same shading as in the previous figures is used to represent masker type and RT.
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
Derived mean percent correct for speech recognition when output SNR was fixed at 0 dB for each condition and listener. The same shading as in the previous figures is used to represent masker type and RT.