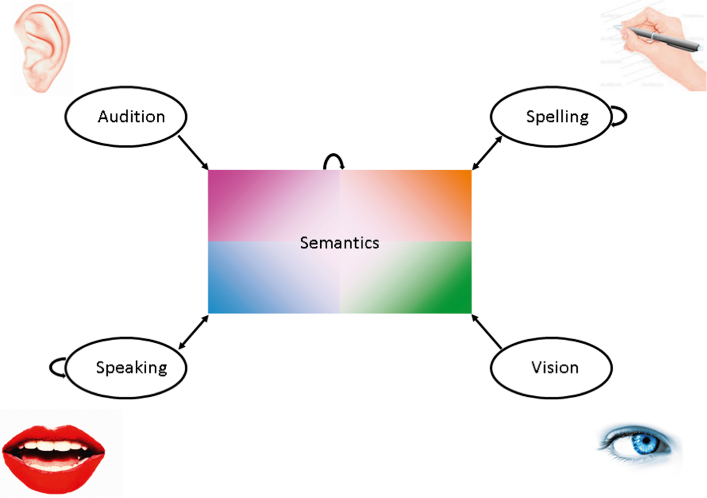
Figure 3. A version of the previous model of visual and auditory word recognition and production containing one large set of hidden units. Learning in the network occurs under a topographic bias that favours short connections. This allows graded modality specificity to emerge in the network, such that units close to a particular input or output participate more in tasks involving them, while units close to the centre are increasingly amodal.