
Figure 1.
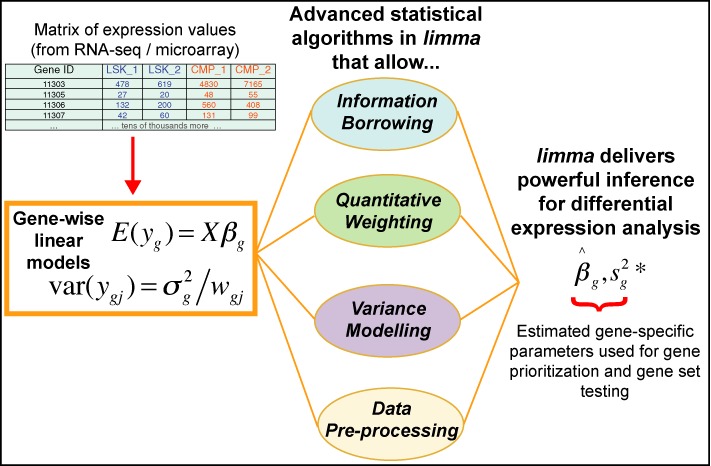
Schematic of the major components that are central to any limma analysis. For each gene g, we have a vector of gene expression values (yg) and a design matrix X that relates these values to some coefficients of interest (βg). The limma package includes statistical methods that (i) facilitate information borrowing using empirical Bayes methods to obtain posterior variance estimators (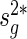 ), (ii) incorporate observation weights (wgj where j refers to sample) to allow for variations in data quality, (iii) allow variance modelling to accommodate technical or biological heterogeneity that may be present and (iv) pre-processing methods such as variance stabilization to reduce noise. These methods all help improve inference at both the gene and gene set level in small experiments.
), (ii) incorporate observation weights (wgj where j refers to sample) to allow for variations in data quality, (iii) allow variance modelling to accommodate technical or biological heterogeneity that may be present and (iv) pre-processing methods such as variance stabilization to reduce noise. These methods all help improve inference at both the gene and gene set level in small experiments.