
Figure 5. Long-term evolution of the state of a single agent in terms of success probability and the individual probabilities to do one of the four actions.

For φ = π/4 (left) the action pair 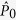 and
and 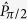 is degenerate with respect to the expected reward. For φ = π/8 (middle), i.e., not exactly between two projectors, the agent measures more often into the direction α = 0. Fluctuations in the measurement probabilities do not necessarily show in the success probability. For comparison, the ensemble averages of 1000 agents after 1000 measurements are given as dashed lines. Larger rewards λ and damping γ (both rescaled by a factor 10) decrease the timescale of the fluctuations while maintaining approximately the same time average (right). The agent jumps between different preferred action and stays for extended times.
is degenerate with respect to the expected reward. For φ = π/8 (middle), i.e., not exactly between two projectors, the agent measures more often into the direction α = 0. Fluctuations in the measurement probabilities do not necessarily show in the success probability. For comparison, the ensemble averages of 1000 agents after 1000 measurements are given as dashed lines. Larger rewards λ and damping γ (both rescaled by a factor 10) decrease the timescale of the fluctuations while maintaining approximately the same time average (right). The agent jumps between different preferred action and stays for extended times.