
Figure 3.
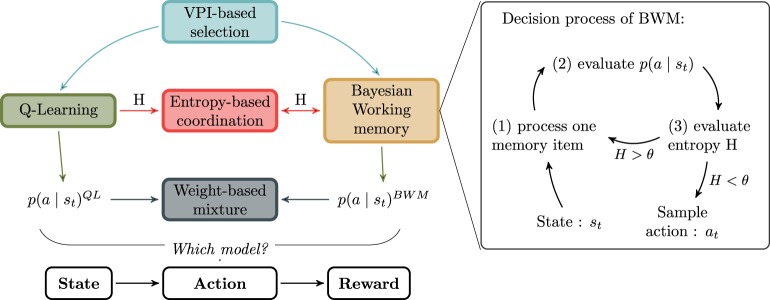
Relationship between models. The goal-directed and habitual strategy are respectively the Bayesian Working Memory (BWM) and the Q-Learning algorithm (QL). Between BWM and QL, the different models for the strategies interaction are respectively VPI-based selection, Entropy-based coordination or Weight-based mixture. In the right box, the decision process of BWM is decomposed into three stages. The purpose of the cycle is to reduce iteratively the entropy H computed over action probabilities.