
Figure 1.
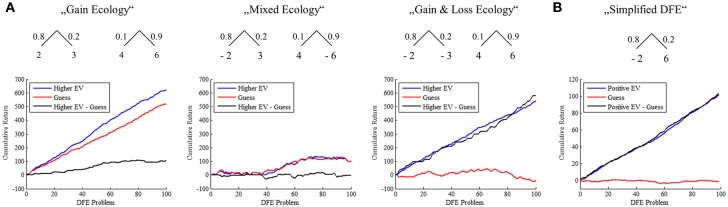
(A) Simulation of the superiority of a higher EV choice strategy over random choice across different DFE ecologies. The panels depict the cumulative return of two decision makers obtaining final samples from two urns according to a “higher expected value” choice rule and a random choice rule. Across different ecologies the “higher EV” choice rule outperforms the random choice rule, the amount by which depending on the specific DFE ecology. More specifically, in the “Gain Ecology” two binary payoff distributions were uniformly sampled from the space ℕ10×ℕ10×[0, 1] and “final” samples obtained from either the binary payoff distribution with the higher expected value (“higher EV”) or from either payoff distribution with equal probability (“Guess”). The cumulative returns of the “higher EV” choice rule outperform the random choice rule from approximately 40 DFE problems on in this realization. In the “Mixed Ecology,” two binary payoff distributions were uniformly sampled from {−10, −9, …, 9, 10} × {−10, −9, …, 9, 10} × [0, 1]. While the random choice rule results in approximately equal gains and loss and thus a cumulative return centered around 0, the higher EV choice rule yields cumulative gains. Finally, in the “Gain and Loss Ecology” one binary payoff distribution was sampled from ℕ10×ℕ10×[0, 1], while the other was sampled from {−10, −9, …, −1} × {−10, −9, …, −1} × [0, 1]. Again, the random choice rule results in approximately equal gains and loss, while the higher EV rule always prefers the binary payoff distribution with the positive expected value in the final choice. (B) Simulation of the SSP and the superiority of the positive EV choice strategy over random choice. Agreeing to sample from a single binary distribution for monetary return, when the expected value of the distribution is positive, yields positive cumulative return, randomly agreeing to sample regardless of whether the expected value is positive or is not positive yields virtually no cumulative return. Throughout panels of Figure 1 the realizations shown correspond to average cumulative returns over 1000 repetitions of the 100 DFE problem sampling and choice procedures.