
Figure 3.
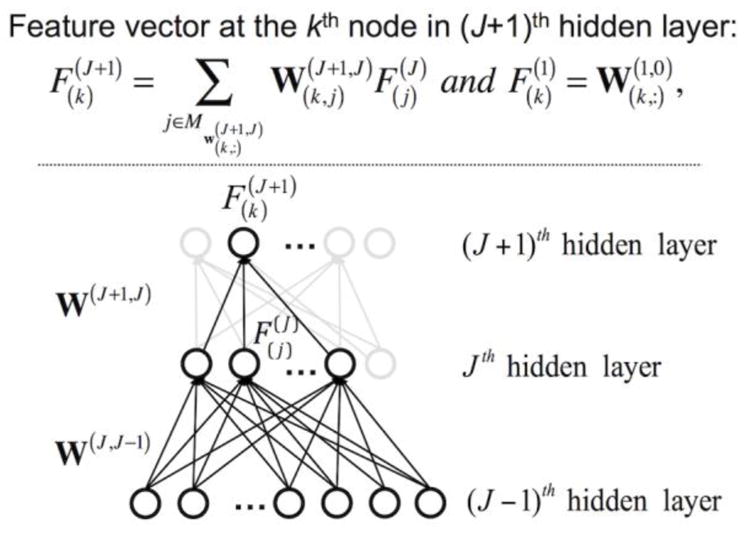
Feature vector representation from the trained DNN weights. The learned feature vector, , at the kth hidden node in the (J+1)th hidden layer is defined from a linear combination of the feature vectors in the Jth hidden layer (please refer to the detailed description in the Methods section). Input layer is defined as the 0th layer.