

A scalable shared-control architecture for silicon-based quantum computing using topological quantum error correction.
Keywords: Silicon quantum computing, Donors in silicon, Spin qubits
Abstract
The exceptionally long quantum coherence times of phosphorus donor nuclear spin qubits in silicon, coupled with the proven scalability of silicon-based nano-electronics, make them attractive candidates for large-scale quantum computing. However, the high threshold of topological quantum error correction can only be captured in a two-dimensional array of qubits operating synchronously and in parallel—posing formidable fabrication and control challenges. We present an architecture that addresses these problems through a novel shared-control paradigm that is particularly suited to the natural uniformity of the phosphorus donor nuclear spin qubit states and electronic confinement. The architecture comprises a two-dimensional lattice of donor qubits sandwiched between two vertically separated control layers forming a mutually perpendicular crisscross gate array. Shared-control lines facilitate loading/unloading of single electrons to specific donors, thereby activating multiple qubits in parallel across the array on which the required operations for surface code quantum error correction are carried out by global spin control. The complexities of independent qubit control, wave function engineering, and ad hoc quantum interconnects are explicitly avoided. With many of the basic elements of fabrication and control based on demonstrated techniques and with simulated quantum operation below the surface code error threshold, the architecture represents a new pathway for large-scale quantum information processing in silicon and potentially in other qubit systems where uniformity can be exploited.
INTRODUCTION
For quantum information processing, the nuclear spin–½ degrees of freedom of ionized phosphorus donors in silicon offer near-perfect two-state qubit encoding (1)—there is inherently zero-state leakage and zero qubit loss due to the stability of the 31P nucleus. In recent years, there have been significant advances toward the goal of silicon quantum computing using phosphorus donor spin qubits [see the work of Zwanenburg et al. (2) for a review of the field]. Quantum control and measurement of ensemble and individual donor nuclear spins verify extremely long quantum coherence times (3–5)—more than half an hour in the “spin vacuum” of isotopically pure silicon in bulk (6). In addition, donor-based devices can be fabricated using scanning tunneling microscopy (STM) techniques with near-atomic precision (7–9). However, even if the qubits are long-lived, a full-scale universal quantum computer requires more than the ability to fabricate many high-precision qubits—quantum error correction (QEC) is mandatory for the execution of quantum algorithms such as Shor’s algorithm (10). Scale-up of quasi–one-dimensional (1D) donor arrays incorporating spin transport quantum interconnects has been proposed (11); however, the indicative QEC thresholds for such systems are extremely low [~10−6 or lower (12)]. In this respect, topological QEC (TQEC) (13–15) is a game changer—the surface code error threshold at the 1% level (15, 16) places elements of fault-tolerant quantum computing within reach of current experimental precision (5, 17–21), and there are now a number of demonstrations of QEC on small-scale qubit systems (22–24). In terms of scale-up, the implementation of TQEC, however, requires a 2D array of nearest-neighbor coupled qubits controlled with a high degree of parallelism and synchronicity. When viewed from the perspective of physical fabrication and control, the operation of N qubits in the usual independent control model implies a number of control lines exceeding N, possibly by an order of magnitude where several gates are required to control qubit confinement, readout, and qubit logic gates. The accommodation of such qubit arrays and associated circuitry in spin-based systems of donors and/or quantum dots, where the pitch due to the qubit interaction is only tens of nanometers, is therefore problematic. Recently, approaches have been suggested based on physically moving qubits over large distances (25), or hybrid donor-dot transport systems (26). In general, the introduction of quantum interconnects (27) creates more fabrication, characterization, and control complexity in the overall problem and require careful inclusion into the fault-tolerant QEC protocol. Inherent in the independent control model is the need for every quantum component (qubits, gates, readout, and interconnects) to be precisely characterized with high temporal stability.
Here, we present an alternative solution to this problem, particularly suited to donor-based spins in silicon. When viewed from the perspective of the error correction protocol itself, the surface code involves repetitions of operations between data and ancilla qubits that form the basis of stabilizer measurements in well-defined geometrical patterns across the array (28). The control and fabrication problems outlined above are invoked when one forces parallel and synchronous operation across the array into an independent qubit control model. Our approach instead recognizes that, to the extent that macroscopic factors such as 28Si purity and magnetic field homogeneity can be controlled to a high degree, the donor spin qubits are highly uniform in terms of their energy levels, electron confinement potential, spin-spin interactions, and response to externally applied (“global”) spin-control fields. Thus, they permit a high degree of shared control. We exploit this fact in the design of a 2D globally controlled architecture in which the TQEC primitives can be carried out across the array using multiplexed control lines. In addition to the simplifications in control and characterization, the design avoids electron wave function engineering (1) and quantum interconnects (11). In effect, the complexity of all quantum operations is distilled to the well-understood operation of loading and unloading electrons to and from donors, which has been demonstrated in numerous experiments (29–32).
In presenting the concept, we aim to address the physical realities as comprehensively as possible. The system is therefore detailed and analyzed across several perspectives: from the physical qubit system, including spin-based quantum gates and simulations of experimental implementations, to the operations underpinning surface code QEC and scale-up. First, we present an overview of the architecture spanning the physics of the nuclear spin qubit states, shared control, and single- and two-qubit quantum gates. From this physical basis, we analyze the implementation of the surface code on the architecture, including the conditions under which the quantum operation error rates are below threshold. As we will show, the degree of parallelism achieved in this design is high, requiring only four steps to perform surface code stabilizer measurements across the entire array, independent of the number of qubits. From simulations of the quantum operations, we determine the conditions under which the effective gate errors are below the error threshold, and we consider various sources of qubit and control inhomogeneity and their mitigation in the architecture design. In our Discussion section, we discuss scale-up to large arrays required for universal quantum computing. In the Supplementary Materials, we focus on the experimental implementation by performing 3D electrostatic simulations, paying particular attention to qubit phase synchronization and the robustness of shared-control qubit addressing given the likely level of fabrication variations. Many of the building blocks of this architecture have been experimentally demonstrated, and our simulations of the quantum operations, including the various sources of decoherence and control errors, indicate that the single- and two-qubit gate error rates under the current experimental conditions are within the expected surface code error threshold. While our simulations focussed on the specific case of dipole-only coupled qubits, a relatively small increase in the donor array density would engage the exchange interaction and increase the CNOT gate speed significantly. In our architecture, the overall fabrication and control complexity is significantly reduced: a full-scale universal quantum computer based on this design will have far fewer control lines, by several orders of magnitude, than that required for independent qubit control. The architecture thus provides a pathway to a large-scale universal quantum computer based on donor qubits in silicon, and the shared-control paradigm may be of use in other qubit systems where uniformity can be exploited.
RESULTS
Overview of the architecture
The architecture is schematically shown in Fig. 1. Quantum information is encoded on the long-lived nuclear spin–½ states of ionized P+ donors, |↑n〉 → |0〉, |↓n〉 → |1〉, which are arranged in a 2D square array. We can take advantage of the recent demonstration of 3D STM fabrication of Si:P structures (33) to break free from the geometric constraints of planar circuitry and exploit the third dimension to define three operational planes. In the upper (green) and lower (blue) planes, nanowires form a regular crisscross grid of control lines (Fig. 1A), with a width of 5 nm and a pitch of 30 nm (for definiteness). In the middle plane, the 2D lattice of P donor qubits at the same pitch is patterned with atomic precision, tunnel-coupled to phosphorus-doped quantum dots that form the islands of vertical single-electron transistor (SET) structures (Fig. 1B). The upper series of nanowires alternate as SET source (S) and upper gates (GA), whereas the lower complementary control line series alternate as SET drain (D) and lower gates (GB). Each qubit is addressed by a set of upper/lower gate crossings around each cell (Fig. 1C). In any given unit cell, the SET island facilitates donor spin loading and unloading, controlled by bias conditions defined by the associated intersections of proximal source, drain, and gates. The bias conditions can be set to independently couple the SET island to a specific neighbor donor to load/unload an electron for activation/deactivation, and the control layout allows for multiplexing this operation across the array (see the Supplementary Materials and fig. S1). Once qubits are activated, they can be controlled by externally applied (global) radio frequency (RF) and microwave (MW) fields acting on the nuclear-electron states to simultaneously perform single- and two-qubit quantum gates on the activated donor qubits, on the basis of well-understood electron spin resonance (ESR) and nuclear magnetic resonance (NMR) techniques (1). Nonactivated qubits are sufficiently detuned and remain unaffected by global control. Initialization and readout of the qubit nuclear spins follow well-established protocols on the basis of swapping the quantum information from the nuclear spin to the electron spin, together with spin-dependent electron tunneling to the SET island (5). The whole device is cooled to the millikelvin regime and operates in a static magnetic field of Bz ~ 2 T. The remainder of the paper is devoted to detailing the operation of the architecture.
Fig. 1. Physical layout of the donor-based surface code quantum computer.
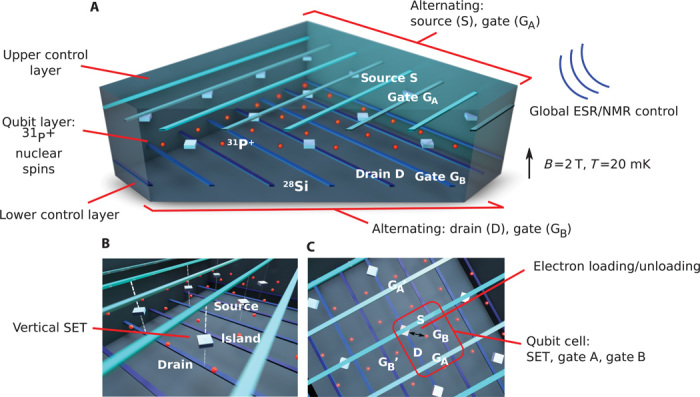
(A) The system comprises three layers. The 2D donor qubit array resides in the middle layer. A mutually perpendicular (crisscross) pattern of control gates (initially chosen to be 5 nm in width and 30 nm in pitch) in the upper and lower planes form a regular grid of (3D) cells. In the upper plane, the control lines alternate as source (S) and gate A (GA), and in the bottom plane, the control gates alternate as drain (D) and gate B (GB). (B) In the middle plane directly below each intersection of S and D lines is a STM fabricated Si:P monolayer quantum dot, which forms the island of a vertically defined SET facilitating electron loading/unloading and readout. (C) A single P donor is located at the center of each cell defined by the boundaries of GA, GB, S, and D lines. In the noninteracting memory state, the qubit states are encoded on the long-lived zero-leakage/zero-loss spin states of the spin-½ P nucleus (31P+). A specific qubit is activated/deactivated by applying voltages to the proximal gates (S, D, GA, GB, GA′, and GB′) to create the local bias condition to load/unload an electron onto the donor or to place the system into the readout configuration (see the Supplementary Materials and fig. S1). By virtue of the shared-control lines, this process can be carried out in parallel at multiple locations. Activation switches on the hyperfine interaction on single donors, and spin-spin interactions for neighboring activated donors, allowing single- and two-qubit gates to be carried out via global ESR and/or NMR control. Nonactivated qubits are detuned from these control fields and remain unaffected. The computer operates at millikelvin temperatures in a background static field of ~2 T.
Single-qubit gates
The nuclear spin states of the qubit in the P+ “memory” configuration (Fig. 2A) precess according to the usual Zeeman Hamiltonian
| (1) |
where gn = 1.13 is the nuclear g factor for phosphorus (1), μn is the nuclear dipole moment, Bz is the static magnetic field in the z direction, and Zn is the Pauli Z-operator acting on the nuclear spin (throughout this paper, the subscripts n and e refer to nuclear and electron spins, respectively). In the absence of a bound electron on the donor, the hyperfine interaction is identically zero, and in high-purity 28Si, the quantum coherence time of the qubit in this memory configuration is much longer than the operational time scale of the architecture. The uniformity of the qubit energy levels, and hence resonant frequency in the memory configuration, ℏωmem = ΔEmem = 2gnμnBz (denoted RF0 in Fig. 2A), is therefore limited only by the purity of the silicon substrate and the homogeneity of the magnetic field.
Fig. 2. Schematic of single-qubit states, activation, and initialization/readout.

(A) Single donor qubit cell and SET island (side view), addressed by the intersection of source/drain gates and proximal gates. In the memory state, the donor is ionized (P+) and the energy splitting between the computational states is ΔEmem = 2gnμnBz (designated RF0). (B) The qubit is activated by loading a spin-down electron, where RF NMR (RF1 and RF2) and MW ESR (MW1 and MW2) transitions allow global nuclear/electron spin control, leaving unactivated qubits unaffected. (C) Top view showing the control lines biased to activate a qubit (deactivation occurs in reverse). Shared control allows qubits to be activated at multiple locations. (D) Readout is performed by swapping the nuclear state to the electron spin and placing the SET-donor system in the spin-dependent tunneling position (5). Readout signals from S/D lines are time-correlated to pinpoint the qubit cell and, by generalization, allow readout across multiple qubit cells. (E) Phase-matched (PM) loading/unloading incorporated into quantum operations. For load/unload configurations, voltages on gates (S, D, GA, GB, GA′, and GB′) are pulsed to only allow SET-donor tunneling during intervals t, which are phase-locked to the hyperfine frequency 1/tA = 2A/h, preventing stochastic phase accumulation on the nuclear spin when the electron loads/unloads (see the Supplementary Materials).
An electron is loaded in a spin-down state to the corresponding donor from the proximate SET island to activate a specific qubit (Fig. 2B). This is achieved by first applying a small negative voltage to both of the S and D lines that intersect at the desired SET. This raises the Fermi level of the SET in question, bringing it close to the electrochemical potential required to load an electron onto one of the nearby donors. A combination of voltages applied to the gates (GA, GB, GA′, and GB′) lowers the potential of the target donor so that an electron will transfer to it. 3D electrostatic simulations of the combination of voltages required to execute read, load, and unload operations (see the Supplementary Materials and fig. S1) show that the bias control conditions are robust against donor placement variations of several nanometers, well within current STM-based fabrication tolerances (7, 34). When an electron is loaded to a donor, the hyperfine interaction is immediately switched on, and the Hamiltonian of the qubit in this activated configuration becomes
| (2) |
where and the hyperfine interaction for P donors in silicon is (2A/h) = 58.5 MHz (35). The activated-qubit states and resonant frequencies are schematically shown in Fig. 2B. In the electron spin-down sector, the resonant frequency of the qubit (denoted RF1 in Fig. 2B) changes to ℏωact = ΔEact = E|1↓〉 − E|0↓〉 = ΔEmem + 2A, detuned from spectator qubits in the memory configuration by an amount 2A. Given the relatively low voltages applied to these structures, the Stark shift of the donor levels and the hyperfine interaction will be negligible (7), and the value of A will be highly uniform given that the extremely narrow linewidth of P donor nuclear spins in ensemble measurements (3) is dominated by field inhomogeneity. The resonant frequency of the qubit nuclear spin in the “activated” configuration is thus digitally switched (36) and therefore provides a precise method of addressing qubits for global NMR control. The crisscross control array allows multiple qubits to be activated in parallel and brought into resonance with the global RF/MW spin-control fields to effect any single-qubit gate en masse over the activated set. Meanwhile, qubits in the memory configuration are sufficiently off-resonance and remain spectators to the process. Single-qubit operations on nuclear and/or electron spins are thus performed via the global application of the following Hamiltonian (1)
| (3) |
where ωMW,RF are the frequencies of the applied fields tuned to the relevant transitions of the activated electron/nuclear spin system (Fig. 2B) and BMW,RF are the respective field strengths. Assuming a RF field strength of BRF = 1 mT, the corresponding X gate (π rotation) time on the nuclear spin qubit is ~21 μs. Rotations of the nuclear spin around the y axis may also be achieved with a RF field π/2 out of phase to x-axis rotations. Using combinations of rotations around these two orthogonal axes, any single-qubit rotation of the nuclear spin may be achieved using this global control, including robust control pulses such as BB1 (37), which can correct for residual control errors (such as small inhomogeneities in A) and/or global decoupling pulses. Similarly, the electron spin can be controlled via resonant MW fields.
The procedure for qubit initialization and readout, schematically shown in Fig. 2D, is based on the protocol for donor nuclear spin readout demonstrated by Pla et al. (5). Qubit readout can be carried out in parallel over the array by time-correlating current signals in the S and D lines. Either the near-coincidence readout events that occur at cell locations that cannot be uniquely resolved in the first pass can be ignored (allowing the QEC protocol to compensate) or the measurement at those locations can be repeated with minimal overhead effect on QEC because the qubit memory time is much longer than the overall readout protocol.
The activation (and deactivation) process is key to qubit addressing and operation and is governed by the donor island tunneling process. The ability to load, unload, and read an individual electron from a donor has been demonstrated in several experiments (29–32); with donor placement to near single atomic site precision (7), the mean tunneling time between donor and SET island can be engineered from sub-nanoseconds to milliseconds. However, in addition to variations in the mean tunnel rate due to donor placement, quantum tunneling is a naturally stochastic process. As soon as the electron is present on the donor in the activated configuration, the qubit nuclear spin begins to acquire a (well-defined) phase due to the hyperfine interaction. If the time at which the electron tunnels to the donor is not known, because of the stochastic nature of the tunneling process, the abrupt change in the strength of hyperfine at a random time gives rise to an unknown phase accumulation on the qubit state and can be a source of dephasing. It is possible to engineer tunneling rates to be faster than the hyperfine interaction; however, this could be problematic for readout with SET sensitivities at the level (30). To overcome this issue, we introduce a new concept of a phase matched (PM) pulsed loading sequence applied to the appropriate control lines (see Fig. 2E). The system is placed into the load/unload configuration during discrete intervals, Δt, that are short compared to the hyperfine time scale. The period between these intervals tA is PM to the difference in frequency, 1/tA = (ΔEact − ΔEmem)/h = 2A/h, between the nuclear spin precession frequencies of active (loaded) and memory (unloaded) qubit configurations. The PM scheme thereby restricts the stochastic tunneling events to be synchronous with the natural phase cycle of the qubit. The qubit activation/deactivation process is now semideterministic—one does not need to know exactly when the electron tunneled, only that the PM sequence is long enough for the probability of tunneling to be high and for the residual phase error [~(π2/3)(Δt/tA)2] to be low with respect to the surface code error threshold. Qubits may now activate/deactivate at different times in the PM sequence because of residual control variations in each qubit cell; however, phase matching is maintained, and by timing all pulses with respect to a common clock, qubit phases will remain synchronous across the entire array. As we will see, the PM scheme is remarkably robust against variations in the inherent tunneling times and voltage control conditions that may arise owing to limits on donor placement and control line fabrication/alignment (see the Supplementary Materials and fig. S2).
Control-NOT gate
The interaction underpinning the two-qubit Control-NOT (CNOT) gate between neighboring qubits is based on natural electron-electron spin interactions and controlled by the timing of electron load/unload operations. In the absence of bound electrons, the spin-dipole interaction between the nuclear spins of memory qubits is negligible. However, when electrons are loaded on adjacent sites, the spin-spin interaction between activated donor pairs increases by more than six orders of magnitude because of the larger magnetic moment of the electron. By swapping the states of the nuclear and electron spins on a given donor, using global control, the electron spin-spin interaction directly couples the qubit data and forms the basis of the two-qubit CNOT gate. The electronic spin-spin interaction can be based on either dipole or exchange interactions, depending on the overall dimensions and placement of gate structures, and the CNOT gate can be made insensitive to donor placement variations by incorporating robust control (38, 39). Here, we explicitly consider the case of dipole-mediated gates, which is the dominant interaction at a separation of 30 nm. At smaller spacings, the faster exchange interaction would dominate.
The sequence of operations involved in the CNOT gate between any pair of neighboring qubits is described in Fig. 3 (A to H). The CNOT gate can be understood as two Hadamard gates directly applied to the target qubit through global control on the nuclear spin, sandwiching a control-Z operation [conjugation by Hadamard gates transforms Z into X and therefore converts the control-Z into a control-X (CNOT) gate]. The qubit-qubit interaction is mediated by the electron-electron spins after the qubits are activated using the gates shown in Fig. 3 (B and E), and nuclear spins states are swapped to the electron spins using RF/MW control (3) (Fig. 3F). As a result of the electron-nuclear spin swap operation, the nuclear spins of the neighboring donors are oppositely aligned as a result of the X gate applied to the target qubit electron after the first load phase (Fig. 3C). Therefore, flip-flops between electron spins carrying the qubit data are highly suppressed because they are out of resonance with one another, and only phase is accumulated in the interaction. During the interaction, a spin echo sequence is applied, which serves to refocus any inhomogeneous magnetic field affecting the electron spins [guaranteeing that the overall CNOT gate fidelity is governed by T2(e) rather than the much shorter T2*(e)]. These X gates commute with the interaction and thus do not change the timing of the control-Z phase accumulation. Finally, the qubit data on the electron spins are swapped back into the nuclear spins and the electrons are unloaded (Fig. 3H) to place the qubits back in the memory configuration. At this stage, it is also possible that the electrons could be read out, and this information then used to check the CNOT operation and/or incorporated into the error correction protocol. As spin control is carried out by global RF and MW fields, the CNOT gate can be carried out on many pairs of qubits in parallel through the multiplexed control lines. The activation of the target qubit followed by the control qubit occurs in sequential steps and hence can be carried out on neighboring qubit cells (see the Supplementary Materials for details of the voltage conditions). Because we do not precisely know when the electron loads onto the CNOT control qubit, that is, the start of the electron-electron spin interaction, we apply a global decoupling pulse, which in this case decouples the dipole interaction by applying rotations around the dipole magic angle (40), applied in phase with the PM loading cycle to ensure that the electron spins have the correct alignment for the CNOT gate interaction at the end of the loading phase.
Fig. 3. Overview of the two-qubit CNOT gate.

(A) Circuit-process diagram for a CNOT between target/control nuclear spin qubits (n1/n2), mediated by the spin-spin interaction between loaded electrons (e1/e2). (B) The target qubit is activated using the gates (S, D, GA, GB, GA′, and GB′). (C) A global ESR X gate flips the loaded electron spin to the up state, thereby distinguishing the target qubit resonant frequency from the control qubit when activated. (D) A Hadamard gate, H, is applied to the data on the target qubit nuclear spin. During the subsequent control qubit load process (E), a global decoupling pulse is applied, in phase with the PM loading cycle, to switch off the (nonqubit) electron-electron interaction until required. The electron and nuclear spin states are swapped (F), marking the beginning of the two-qubit interaction mediated by the (qubit-encoded) electron-electron interaction (G). With exactly opposite nuclear spins, the interaction is an Ising ZZ coupling executing a control-Z (CZ) gate. The X gates extend electron spin coherence during this interaction phase. At the completion of the CZ gate, the qubit data are swapped back to the nuclear spins, and the second Hadamard gate on the target qubit converts the CZ gate to a CNOT. (H) The electrons are unloaded to deactivate the control and target qubits. Memory (spectator) donors are unaffected by these operations.
Provided the overall electron-electron interaction strength is much smaller than the hyperfine interaction A, the same pulse sequence applies to the CNOT gate with exchange interactions (up to the details of the decoupling sequence during the target qubit loading phase). With the control qubit and target qubit having distinct transition frequencies, the CNOT gate design also allows for the inclusion of an interaction correction protocol, for example, BB1-based schemes (38, 39), which provides robustness to a priori unknown variations in the spin-spin interaction (dipole or exchange) given donor placement precision by STM at the lattice site level (7).
Surface code operations
For QEC on the surface code, the 2D array is set up in an alternating arrangement of data and ancilla qubits, upon which repetitive X and Z stabilizer measurements are carried out (13–16, 28, 41) (Fig. 4A). A local stabilizer measurement in the syndrome extraction process involves a sequence of CNOT gates between any given ancilla qubit (CNOT target) and its four neighboring data qubits (CNOT controls), sequentially cycling north, west, east, and south, followed by measurement of the ancilla. In terms of the basic architecture operations—electron loading/unloading, global electron/nuclear control, interaction, and readout—we show in Fig. 4B the sequence of steps for a Z stabilizer measurement (for simplicity, global ESR/NMR operations in the CNOTs are not shown). The X stabilizer case is similar in the essentials. These measurements must occur with a high degree of parallelism over the array to capture the high threshold of the surface code—at this key point, the power of the design with shared-control lines and global ESR/NMR becomes apparent. Figure 4 (C to G) shows the Z stabilizer measurement sequence over multiple ancilla/data qubit groups in terms of the control lines activated. To avoid stray qubit-qubit interactions and accommodate the set of gates distinguishing the ancilla positions, we perform the stabilizer measurement at every fourth ancilla position. To carry out the set of stabilizer measurements across the entire lattice, we therefore need only four steps, independent of the number of qubits. Ancilla readout at the end of each step requires S-D correlation over only one-quarter of the array. Multicell coincidences can be identified and resolved by repeating the ancilla measurements in the affected cells, adding only a small overhead as the probability of subsequent multiple-cell ambiguities exponentially decreases. The ideal surface code (memory) threshold at pth ~ 1% (16) is based on a single-step process (for each of the X and Z stabilizer measurements); however, we do not expect this to significantly change on our architecture because the inherent qubit memory time is many orders of magnitude longer than the operation time scales and will comfortably accommodate the four-step stabilizer process and readout.
Fig. 4. Surface code operations on the 2D array.

(A) A small section of the surface code, highlighting Z and X stabilizer measurements for QEC. (B) Circuit/process diagram for the measurement of the Z stabilizer on an ancilla qubit with respect to its data qubit neighbors. Electron spins are shown as dotted lines; nuclear spins are shown as solid lines. (C to G) The voltage control lines (S, green; D, blue; GA/GB, gray; GA′/GB′, light gray) required for the loading and unloading of the electrons. (C) shows the loading configuration for syndrome ancilla qubits across one-quarter of the lattice, whereas (D) to (G) show the loading configurations to implement the CNOT sequence to neighboring data qubits [north (D), west (E), east (F), and south (G)] required in the surface code stabilizer measurements. By moving to the other ancilla sublattices and repeating, the syndrome measurement across the entire lattice is achieved in four steps.
The analysis so far has focused on the stabilizer measurements required for one round of QEC across the entire lattice and sets the basis for higher-order protocols on the surface code. Logical qubit operations are topologically more complex; however, the physical operations required of the architecture are in essence particular geometric patterns of stabilizer measurements. As we have seen, the geometric layout places some constraint on which donors can be activated in parallel; hence, not every geometric pattern can be created in a single step. However, simple geometric patterns, such as lines and rectangles, can be created in one or two steps. More complex patterns can be created by sequentially combining these simple geometric patterns to load electrons and construct more complex regions and patterns. The required geometric patterns for the implementation of TQEC can thus be created in parallel using a finite number of steps, independent of the number of qubits. The intrusion into the error threshold is minimal owing to the extremely long qubit memory time.
Gate operation, error threshold, and sources of nonuniformity
To validate the operation of the quantum computer below the surface code threshold, we performed numerical simulations of each of the quantum gates, including the potential sources of error. In isotopically purified silicon, direct spin dephasing of the memory state has been effectively eliminated. In lieu of explicit pulse optimization, the dominant sources of error arise from loading/unloading errors, as well as residual electron spin dephasing while qubits are activated [restricted to T2(e) by the CNOT design]. We initially separate out the loading process (that is, “bare” operation) and take BAC ~ 1 mT and T2(e) ~ 2 s (42), corresponding to single-qubit operation times and errors of TX (bare) ~ 21 μs and εX (bare) ~ 5 × 10−5, respectively. These parameters match well with current experimental capabilities (5, 29–31). For the CNOT gate under these global control conditions and 30-nm donor separation, we obtain TCNOT (bare) ~ 300 μs and εCNOT (bare) ~ 10−3, respectively. To include the load/unload process, we simulated the PM protocol for a range of SET-donor tunneling times (τ) and PM pulse window duration (Δt). In Fig. 5A, we show the overall PM error εPM (including the residual hyperfine phase error) and total time TPM for the loading process (simulations of the PM unloading protocol give similar results). The results show that there is a relatively large region of parameter space, that is, values of τ, Δt, and TPM, where the PM loading error is below the TQEC threshold, and the activation process is robust to the details of the donor-SET tunnel rate and pulse window width.
Fig. 5. Simulations of PM qubit activation and the CNOT gate.

(A) Total PM loading error with respect to the surface code threshold, including residual qubit dephasing, as a function of PM pulse window, t, and overall pulse train length, TPM, for a range of SET-donor tunneling rates τ = 100, 500, and 1000 ns. (B) CNOT gate error and total operation time (including PM loading and unloading operations) for PM pulse window widths Δt = 0.2, 0.4, 0.6, and 0.8 ns [fixed parameters: τ = 500 ns, 30 nm qubit spacing, and T2(e) = 2 s (42)].
In comparison to the bare gate operation times, we see that the total single-qubit operation times and error rates will be dominated by the qubit activation/deactivation processes. The results also show that as long as the PM pulse train is sufficiently long, the system is robust against variations in the tunneling time τ resulting from fabrication and voltage control variations. The complete CNOT gate incorporating the PM sequences was simulated in the superoperator formalism, and the results for a qubit spacing of 30 nm, including the PM loading/unloading processes, are shown in Fig. 5B. For a reasonable choice of the SET-donor tunnel time of τ ~ 500 ns, commensurate with achievable readout time scales, we have εCNOT < pth for a range of parameters in the region TCNOT ~ 600 μs and Δt ~ 0.6 ns. The CNOT gate could be made significantly faster through nano-electronic design optimization and/or higher donor densities. The introduction of strain in the silicon substrate would also be beneficial because it mitigates the variation of the exchange interaction caused by interference between the six degenerate valley states (43–45). Strain also reduces the magnitude of the hyperfine interaction (46, 47), thereby allowing both the PM pulse window duration, Δt, and pulse period, tA, to increase relative to the tunneling time τ, while essentially maintaining the same error rate and overall PM loading/unloading time, TPM.
The architecture is predicated on a high degree of uniformity inherent in the P donor quantum system, and with this in mind, the design incorporates robustness against various sources of nonuniformity, which we discuss in turn. Macroscopic and materials properties such as magnetic field and isotopic purity can be engineered to a high degree, with current measurements of the nuclear spin T2* greater than 100 μs (3), providing very narrow linewidths. The effect of residual higher-order Zeeman and/or hyperfine inhomogeneities on qubit operations, for example, in the local resonance frequencies due to the nuclear quadrupole moment coupling to strain or in the global fields themselves, can be mitigated by a combination of broadband and/or well-established robust control techniques (37). An example of this is the incorporation of refocusing pulses into the CNOT gate. In the PM activation protocol, B-field inhomogeneities do not contribute to the phase error to first order—local variations in the hyperfine constant, A, are the main source of error. In principle, such errors can be alleviated by the inclusion of refocusing pulses in the PM protocol, which cancel phase accumulation due to any variations in A between donors. Given that the nuclear spin linewidths already at the kilohertz level are dominated by Zeeman effects, the error due to inherent variations in A will be minor and, if required, can be corrected with a small number of refocusing pulses.
A more significant source of nonuniformity arises from variations in donor position and/or number and fabrication yield. At present, it has been shown that we can pattern a single donor with ±1 lattice spacing positional accuracy (7). This technique requires reliably creating a three-dimer patch on a hydrogen-terminated silicon surface by scanning probe lithography and adsorbing three PH2 molecules into this desorption site. Advances in feedback-controlled STM lithography (48) allow single hydrogen atoms to be removed one by one, and density functional theory has revealed a reproducible chemical pathway to incorporating single P atoms within this patch (7). We have shown by 3D electrostatic simulations (see the Supplementary Materials and fig. S1) that the voltage control conditions of the array are essentially unaffected by variations in donor position of several nanometers, within this placement precision currently at the one– to two–lattice site (~1 nm) level. Although the donor placement variations will lead to a range of SET-donor couplings, the PM sequence is inherently robust against different tunneling times (Fig. 5A). For the CNOT gate, the incorporation of robust control techniques compensates for the associated variations in the donor-donor spin coupling (38, 39). All architectures must deal with qubit loss and/or defects—in our case, the latter is the dominant issue. Although advances in STM lithography (49) will improve the lithography for single donor yield, statistically, there will be times when a donor does not incorporate. These defect qubit positions may be identified by the lack of an electron transition to the donor site when the appropriate control voltages are applied and may then be avoided and treated as a deterministic loss mechanism in modifications of the TQEC protocol (50–52).
The SET regions use heavily doped phosphorus in silicon with high uniformity that can be patterned with sub-nanometer resolution using the STM. In these monolayer structures, the carrier density is extremely high, well above the metal-insulator transition, with an average donor separation <1 nm (53). The associated impurity band has a well-defined Fermi energy (54), and the uniformity of the carrier density is evidenced by the fact that in the electrostatic modeling where these regions are treated as metallic, we find good agreement with transport data (8). Although it remains to be seen how one might optimize the SET island geometry, we expect atomic-scale variations in SET island shape to be smoothed out by the overall electronic envelope governed by the ~2-nm Bohr radius (55, 56).
DISCUSSION
In terms of scale-up to a full-scale universal quantum computer, the shared-control paradigm has allowed the placement of qubits in a 2D array at high density, and the total number of control lines required for N qubits is reduced to . Hence, the physical size of the qubit array for a full-scale universal quantum computer is relatively small—at this 30-nm separation, an array of size 150 μm × 150 μm will accommodate N = 25 × 106 physical qubits and, with respect to the surface code threshold, is well within current tolerances for magnetic field homogeneity over macroscopic distances (57). In comparison to the scale-up of independent qubit control schemes, such an array would be controlled by only 104 lines carrying identical and globally timed PM signals, representing a significant reduction in the sheer number of control lines (by three to four orders of magnitude) and signal complexity. In the shorter term, opportunities exist for non–error-corrected quantum simulators on the basis of this shared-control design, taking full advantage of the very long donor qubit coherence times. Here, the requirements for qubit interactions and timing are far less stringent, and one can imagine qubit arrays at the N ~ 100 to 1000 level operating in the interesting regime where the quantum coherence time is longer than the total computation time.
The achievable size of the quantum computer will be ultimately determined by material and macroscopic control uniformity and careful engineering and fabrication optimization of the device layers. Ab initio studies of the incorporation process (34) indicate pathways for scaling up STM placement of donors, whereas the architecture design has a high degree of inherent robustness to inhomogeneities—the shared gate control, PM protocol, and CNOT gate specifically allow for a degree of variation in donor placement, alignment, and voltage control. Advances in subsurface STM imaging of donors (58) indicate the potential to provide information in general on the donor layer yield and alignment with nanowire arrays. During operation, “defected” qubit positions (for example, missing or non–single donors) could be identified via the vertical SETs in charge sensor mode and incorporated into the QEC procedure (50–52).
In conclusion, we have presented an architecture for a universal quantum computer in silicon specifically designed to implement surface code QEC. Qubits are stored in the long-lived nuclear spin degree of freedom of phosphorus donors. Our design embraces the natural uniformity of the atomic donor system, permitting the introduction of a multiplexed crisscross control paradigm for the implementation of parallel quantum operations, as demanded by the surface code, while incorporating robustness to inhomogeneities. By construction, the architecture avoids the need for the complex control circuitry to independently control every qubit and interaction and requires no quantum state engineering or quantum interconnects. By using well-established global ESR/NMR control, all quantum operations are reduced to highly parallelizable local electron loading/unloading operations, carried out by applying well-defined voltage pulses to specific gates in the crisscross gate array. Overall quantum phase and operation synchronicity is maintained across the array by timing the voltage pulses applied. The essential operations required in the surface code—stabilizer measurements—can be carried out over the array in a small number of steps, independent of the number of qubits N. The architecture will benefit from future engineering-level optimization, particularly to capture faster CNOT gates through closer placement of donors and control lines, and the operation of vertical SET structures requires experimental verification. However, many of the building blocks have been experimentally demonstrated—STM fabrication of atomically precise SET-donor systems (7) including the ability to load/unload single electrons (29–32), the extension of STM fabrication to atomically precise nanowires in 3D (59), and single donor nuclear spin control and readout below the surface code threshold level (5). Detailed 3D electrostatic modeling and quantum simulations of the required quantum gates in the presence of dephasing and control errors verified the operational parameter space, robustness to fabrication variations, and overall error rates below the surface code QEC threshold in the sub-percent regime. This shared-control silicon-based architecture thus presents a well-defined route to large-scale quantum computing.
MATERIALS AND METHODS
Simulations of the quantum operations on the architecture (Fig. 5) were carried out using the master equation approach. We obtained the corresponding superoperator for each of the quantum operations (PM protocol and spin-based gates) by numerically solving the appropriate time-dependent master equations. The numerical simulations included the effects of dephasing expected for electronic and nuclear spin qubits, as well as errors in the PM loading, with physical parameters as indicated. The 3D electrostatic simulations were carried out using the FastCap (60) boundary-element capacitance solver. The input to the FastCap solver is a meshed surface representation of the 3D structure; the resulting capacitance matrix is used to compute the total electrostatic energy within the constant interaction model (61) for each possible charge state of the donors and SET at a given set of voltages. Iterating over the relevant voltage coordinates, we track the lowest energy charge state as a function of gate bias to calculate diagrams (fig. S1, C to E).
Acknowledgments
We thank A. Fowler for helpful discussions on surface code error correction. Funding: This work was supported by the Australian Research Council (ARC) Centre of Excellence for Quantum Computation and Communication Technology (CE110001027). M.Y.S. acknowledges an ARC Laureate Fellowship. Author contributions: All authors contributed to the architecture design. C.D.H. and L.C.L.H. codeveloped the initial concept of quantum operations on donor nuclear spins in a 3D shared-control array. M.Y.S. developed the concept of 3D device fabrication. S.J.H., E.P., M.G.H., and M.Y.S. carried out the 3D simulations and analysis of device geometry and shared gate control. L.C.L.H., C.D.H., and S.R. codeveloped the PM protocol. C.D.H. and L.C.L.H. carried out the simulations of quantum operation and surface code analysis. L.C.L.H. wrote the paper with input from all authors. Competing interests: The authors declare that they have no competing interests. Data and materials availability: All data needed to evaluate the conclusions in the paper are present in the paper and Supplementary Materials. Further information pertaining to the theoretical calculations reported in this work will be made available by the authors upon request.
SUPPLEMENTARY MATERIALS
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/1/9/e1500707/DC1
Experimental considerations: 3D electrostatic simulations
PM qubit activation/deactivation
Fig. S1. 3D electrostatic simulations of gate control for qubit addressing.
Fig. S2. Implementation of the PM activation/deactivation sequence.
REFERENCES AND NOTES
- 1.Kane B. E., A silicon-based nuclear spin quantum computer. Nature 393, 133–137 (1998). [Google Scholar]
- 2.Zwanenburg F. A., Dzurak A. S., Morello A., Simmons M. Y., Hollenberg L. C. L., Klimeck G., Rogge S., Coppersmith S. N., Eriksson M. A., Silicon quantum electronics. Rev. Mod. Phys. 85, 961–1019 (2013). [Google Scholar]
- 3.Morton J. J. L., Tyryshkin A. M., Brown R. M., Shankar S., Lovett B. W., Ardavan A., Schenkel T., Haller E. E., Ager J. W., Lyon S. A., Solid state quantum memory using the 31P nuclear spin. Nature 455, 1085–1088 (2008). [Google Scholar]
- 4.Dreher L., Hoehne F., Stutzmann M., Brandt M. S., Nuclear spins of ionized phosphorus donors in silicon. Phys. Rev. Lett. 108, 027602 (2012). [DOI] [PubMed] [Google Scholar]
- 5.Pla J. J., Tan K. Y., Dehollain J. P., Lim W. H., Morton J. J. L., Zwanenburg F. A., Jamieson D. N., Dzurak A. S., Morello A., High-fidelity readout and control of a nuclear spin qubit in silicon. Nature 496, 334–338 (2013). [DOI] [PubMed] [Google Scholar]
- 6.Saeedi K., Simmons S., Salvail J. Z., Dluhy P., Riemann H., Abrosimov N. V., Becker P., Pohl H.-J., Morton J. J. L., Thewalt M. L. W., Room-temperature quantum bit storage exceeding 39 minutes using ionized donors in silicon-28. Science 342, 830–833 (2013). [DOI] [PubMed] [Google Scholar]
- 7.Fuechsle M., Miwa J. A., Mahapatra S., Ryu H., Lee S., Warschkow O., Hollenberg L. C. L., Klimeck G., Simmons M. Y., A single-atom transistor. Nat. Nanotechnol. 7, 242–246 (2012). [DOI] [PubMed] [Google Scholar]
- 8.Weber B., Mahapatra S., Ryu H., Lee S., Fuhrer A., Reusch T. C. G., Thompson D. L., Lee W. C. T., Klimeck G., Hollenberg L. C. L., Simmons M. Y., Ohm’s law survives to the atomic scale. Science 335, 64–67 (2012). [DOI] [PubMed] [Google Scholar]
- 9.Weber B., Tan Y. H. M., Mahapatra S., Watson T. F., Ryu H., Rahman R., Hollenberg L. C. L., Klimeck G., Simmons M. Y., Spin blockade and exchange in Coulomb-confined silicon double quantum dots. Nat. Nanotechnol. 9, 430–435 (2014). [DOI] [PubMed] [Google Scholar]
- 10.P. W. Shor, Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer, paper presented at the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, 20–22 November 1994. [Google Scholar]
- 11.Hollenberg L. C. L., Greentree A. D., Fowler A. G., Wellard C. J., Two-dimensional architectures for donor-based quantum computing. Phys. Rev. B 74, 045311 (2006). [Google Scholar]
- 12.Stephens A. M., Fowler A. G., Hollenberg L. C. L., Universal fault tolerant quantum computation on bilinear nearest neighbor arrays. Quantum Inf. Comput. 8, 330–344 (2008). [Google Scholar]
- 13.S. Bravyi, A. Kitaev, Quantum codes on a lattice with boundary. arXiv:quant-ph/9811052 (1998).
- 14.Dennis E., Kitaev A., Landahl A., Preskill J., Topological quantum memory. J. Math. Phys. 43, 4452–4505 (2002). [Google Scholar]
- 15.Raussendorf R., Harrington J., Goyal K., Topological fault-tolerance in cluster state quantum computation. New J. Phys. 9, 199–223 (2007). [Google Scholar]
- 16.Wang D., Fowler A., Stephens A., Hollenberg L. C. L., Threshold error rates for the toric and surface codes. Phys. Rev. A 83, 020302 (2011). [Google Scholar]
- 17.Chow J. M., Gambetta J. M., Córcoles A. D., Merkel S. T., Smolin J. A., Rigetti C., Poletto S., Keefe G. A., Rothwell M. B., Rozen J. R., Ketchen M. B., Steffen M., Universal quantum gate set approaching fault-tolerant thresholds with superconducting qubits. Phys. Rev. Lett. 109, 060501 (2012). [DOI] [PubMed] [Google Scholar]
- 18.Barends R., Kelly J., Megrant A., Veitia A., Sank D., Jeffrey E., White T. C., Mutus J., Fowler A. G., Campbell B., Chen Y., Chen Z., Chiaro B., Dunsworth A., Neill C., O’Malley P., Roushan P., Vainsencher A., Wenner J., Korotkov A. N., Cleland A. N., Martinis J. M., Superconducting quantum circuits at the surface code threshold for fault tolerance. Nature 508, 500–503 (2014). [DOI] [PubMed] [Google Scholar]
- 19.Harty T. P., Allcock D. T. C., Ballance C. J., Guidoni L., Janacek H. A., Linke N. M., Stacey D. N., Lucas D. M., High-fidelity preparation, gates, memory, readout of a trapped-ion quantum bit. Phys. Rev. Lett. 113, 220501 (2014). [DOI] [PubMed] [Google Scholar]
- 20.Veldhorst M., Hwang J. C. C., Yang C. H., Leenstra A. W., de Ronde B., Dehollain J. P., Muhonen J. T., Hudson F. E., Itoh K. M., Morello A., Dzurak A. S., An addressable quantum dot qubit with fault-tolerant control-fidelity. Nat. Nanotechnol. 9, 981–985 (2014). [DOI] [PubMed] [Google Scholar]
- 21.C. J. Ballance, T. P. Harty, N. M. Linke, D. M. Lucas, High-fidelity two-qubit quantum logic gates using trapped calcium-43 ions. (2015).
- 22.Nigg D., Müller M., Martinez E. A., Schindler P., Hennrich M., Monz T., Martin-Delgado M. A., Blatt R., Quantum computations on a topologically encoded qubit. Science 345, 302–305 (2014). [DOI] [PubMed] [Google Scholar]
- 23.Kelly J., Barends R., Fowler A. G., Megrant A., Jeffrey E., White T. C., Sank D., Mutus J. Y., Campbell B., Chen Y., Chen Z., Chiaro B., Dunsworth A., Hoi I.-C., Neill C., O’Malley P. J. J., Quintana C., Roushan P., Vainsencher A., Wenner J., Cleland A. N., Martinis J. M., State preservation by repetitive error detection in a superconducting quantum circuit. Nature 519, 66–69 (2015). [DOI] [PubMed] [Google Scholar]
- 24.Córcoles A. D., Magesan E., Srinivasan S. J., Cross A. W., Steffen M., Gambetta J. M., Chow J. M., Demonstration of a quantum error detection code using a square lattice of four superconducting qubits. Nat. Commun. 6, 6979 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.O’Gorman J., Nickerson N. H., Ross P., Morton J. J. L., Benjamin S. C., A silicon-based surface code quantum computer. arXiv:1406.5149 (2014). [Google Scholar]
- 26.Pica G., Lovett B. W., Bhatt R. N., Schenkel T., Lyon S. A., Surface code architecture for donors and dots in silicon with imprecise and non-uniform qubit couplings. arXiv:1506.04913, condmat (2015). [Google Scholar]
- 27.DiVincenzo D. P., The physical implementation of quantum computation. Fortschr. Phys. 48, 771–783 (2000). [Google Scholar]
- 28.Fowler A. G., Mariantoni M., Martinis J. M., Cleland A. N., Surface codes: Towards practical large-scale quantum computation. Phys. Rev. A 86, 032324 (2012). [Google Scholar]
- 29.Morello A., Pla J. J., Zwanenburg F. A., Chan K. W., Tan K. Y., Huebl H., Möttönen M., Nugroho C. D., Yang C., van Donkelaar J. A., Alves A. D. C., Jamieson D. N., Escott C. C., Hollenberg L. C. L., Clark R. G., Dzurak A. S., Single-shot readout of an electron spin in silicon. Nature 467, 687–691 (2010). [DOI] [PubMed] [Google Scholar]
- 30.Mahapatra S., Büch H., Simmons M. Y., Charge sensing of precisely positioned P donors in Si. Nano Lett. 11, 4376–4381 (2011). [DOI] [PubMed] [Google Scholar]
- 31.Pla J. J., Tan K. Y., Dehollain J. P., Lim W. H., Morton J. J. L., Jamieson D. N., Dzurak A. S., Morello A., A single-atom electron spin qubit in silicon. Nature 489, 541–545 (2012). [DOI] [PubMed] [Google Scholar]
- 32.Büch H., Mahapatra S., Rahman R., Morello A., Simmons M. Y., Spin readout and addressability of phosphorus-donor clusters in silicon. Nat. Commun. 4, 2017 (2013). [DOI] [PubMed] [Google Scholar]
- 33.McKibbin S. R., Scappucci G., Pok W., Simmons M. Y., Epitaxial top-gated atomic-scale silicon wire in a three-dimensional architecture. Nanotechnology 24, 045303 (2013). [DOI] [PubMed] [Google Scholar]
- 34.Wilson H. F., Warschkow O., Marks N. A., Schofield S. R., Curson N. J., Smith P. V., Radny M. W., McKenzie D. R., Simmons M. Y., Phosphine dissociation on the Si(001) surface. Phys. Rev. Lett. 93, 226102 (2004). [DOI] [PubMed] [Google Scholar]
- 35.Feher G., Gere E. A., Electron spin resonance experiments on donors in silicon. II. Electron spin relaxation effects. Phys. Rev. 114, 1245–1256 (1959). [Google Scholar]
- 36.Skinner A. J., Davenport M. E., Kane B. E., Hydrogenic spin quantum computing in silicon: A digital approach. Phys. Rev. Lett. 90, 087901 (2003). [DOI] [PubMed] [Google Scholar]
- 37.Wimperis S., Broadband, narrowband, and passband composite pulses for use in advanced NMR experiments. J. Magn. Reson. A. 109, 221–231 (1994). [Google Scholar]
- 38.Hill C. D., Robust controlled-NOT gates from almost any interaction. Phys. Rev. Lett. 98, 180501 (2007). [DOI] [PubMed] [Google Scholar]
- 39.Testolin M. J., Hill C. D., Wellard C. J., Hollenberg L. C. L., Robust controlled-NOT gate in the presence of large fabrication-induced variations of the exchange interaction strength. Phys. Rev. A 76, 012302 (2007). [Google Scholar]
- 40.Waugh J. S., Huber L. M., Haeberlen U., Approach to high-resolution NMR in solids. Phys. Rev. Lett. 20, 180 (1968). [Google Scholar]
- 41.Fowler A. G., Whiteside A. C., Hollenberg C. L., Towards practical classical processing for the surface code. Phys. Rev. Lett. 108, 180501 (2012). [DOI] [PubMed] [Google Scholar]
- 42.Tyryshkin A. M., Tojo S., Morton J. J. L., Riemann H., Abrosimov N. V., Becker P., Pohl H.-J., Schenkel T., Thewalt M. L. W., Itoh K. M., Lyon S. A., Electron spin coherence exceeding seconds in high purity silicon. Nat. Mater. 11, 143–147 (2012). [DOI] [PubMed] [Google Scholar]
- 43.Koiller B., Hu X., Das Sarma S., Exchange in silicon-based quantum computer architecture. Phys. Rev. Lett. 88, 279031 (2001). [DOI] [PubMed] [Google Scholar]
- 44.Wellard C. J., Hollenberg L. C. L., Parisoli F., Kettle L. M., Goan H.-S., McIntosh J. A. L., Jamieson D. N., Electron exchange coupling for single-donor solid-state spin qubits. Phys. Rev. B 68, 195209 (2003). [Google Scholar]
- 45.Wellard C. J., Hollenberg L. C. L., Donor electron wave functions for phosphorus in silicon: Beyond effective-mass theory. Phys. Rev. B 72, 085202 (2005). [Google Scholar]
- 46.Huebl H., Stegner A. R., Stutzmann M., Brandt M. S., Vogg G., Bensch F., Rauls E., Gerstmann U., Phosphorus donors in highly strained silicon. Phys. Rev. Lett. 97, 166402 2006. [DOI] [PubMed] [Google Scholar]
- 47.Dreher L., Hilker T. A., Brandlmaier A., Goennenwein S. T. B., Huebl H., Stutzmann M., Brandt M. S., Electroelastic hyperfine tuning of phosphorus donors in silicon. Phys. Rev. Lett. 106, 037601 (2011). [DOI] [PubMed] [Google Scholar]
- 48.Hersam M. C., Guisinger N. P., Lyding J. W., Silicon-based molecular nanotechnology. Nanotechnology 11, 70 (2000). [Google Scholar]
- 49.Randall J. N., Lyding J. W., Schmucker S., Von Ehr J. R., Ballard J., Saini R., Xu H., Ding Y., Atomic precision lithography on Si. J. Vac. Sci. Technol. B 27, 2764 (2009). [Google Scholar]
- 50.Barrett S. D., Stace T. M., Fault tolerant quantum computation with very high threshold for loss errors. Phys. Rev. Lett. 105, 200502 (2010). [DOI] [PubMed] [Google Scholar]
- 51.Fujii K., Tokunaga Y., Error and loss tolerances of surface codes with general lattice structures. Phys. Rev. A 86, 020303 (2012). [Google Scholar]
- 52.Whiteside A. C., Fowler A. G., Upper bound for loss in practical topological-cluster-state quantum computing. Phys. Rev. A 90, 052316 (2014). [Google Scholar]
- 53.Warschkow O., Wilson H. F., Marks N. A., Schofield S. R., Curson N. J., Smith P. V., Radny M. W., McKenzie D. R., Simmons M. Y., Phosphine adsorption and dissociation on the Si(001) surface: An ab initio survey of structures. Phys. Rev. B 72, 125328 (2005). [Google Scholar]
- 54.Carter D. J., Warschkow O., Marks N. A., McKenzie D. R., Electronic structure models of phosphorus δ-doped silicon. Phys. Rev. B 79, 033204 (2009). [Google Scholar]
- 55.Carter D. J., Warschkow O., Marks N. A., McKenzie D. R., Electronic structure of two interacting phosphorus δ-doped layers in silicon. Phys. Rev. B 87, 045204 (2013). [Google Scholar]
- 56.Drumm D. W., Budi A., Per M. C., Russo S. P., Hollenberg L. C. L., Ab initio calculation of valley splitting in monolayer δ-doped phosphorus in silicon. Nanoscale Res. Lett. 8, 111 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.G. Placidi, MRI: Essentials for Innovative Technologies (CRC Press, Taylor and Francis Group, Boca Raton, FL, 2012). [Google Scholar]
- 58.Salfi J., Mol J. A., Rahman R., Klimeck G., Simmons M. Y., Hollenberg L. C. L., Rogge S., Spatially resolving valley quantum interference of a donor in silicon. Nat. Mater. 13, 605–610 (2014). [DOI] [PubMed] [Google Scholar]
- 59.McKibbin S. R., Polley C. M., Scappucci G., Keizer J. G., Simmons M. Y., Low resistivity, super-saturation phosphorus-in-silicon monolayer doping. Appl. Phys. Lett. 104, 123502 (2014). [Google Scholar]
- 60.Nabors K., White J., FastCap: A multipole accelerated 3-D capacitance extraction program. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 10, 1447–1459 (1991). [Google Scholar]
- 61.Kouwenhoven L. P., Austing D. G., Tarucha S., Few-electron quantum dots. Rep. Prog. Phys. 64, 701 (2001). [Google Scholar]
- 62.B. Weber, Towards scalable planar donor-based silicon quantum computing architectures, PhD thesis (2013). [Google Scholar]
- 63.Morello A., Escott C. C., Huebl H., Van Beveren L. H. W., Hollenberg L. C. L., Jamieson D. N., Dzurak A. S., Clark R. G., Architecture for high-sensitivity single-shot readout and control of the electron spin of individual donors in silicon. Phys. Rev. B 80, 081307(R) (2009). [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/1/9/e1500707/DC1
Experimental considerations: 3D electrostatic simulations
PM qubit activation/deactivation
Fig. S1. 3D electrostatic simulations of gate control for qubit addressing.
Fig. S2. Implementation of the PM activation/deactivation sequence.