
Fig. 5.
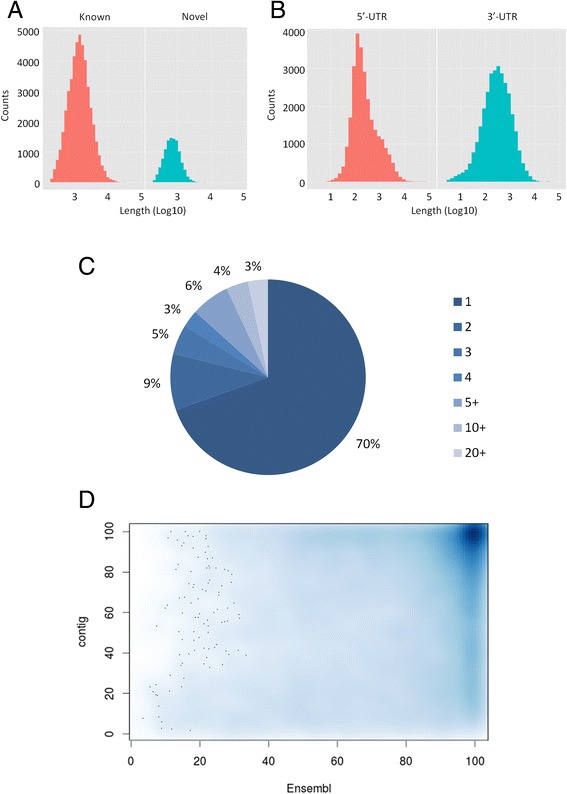
Contribution of the GigaTON database. a: Length distribution histogram of the known (red) and the ‘novel’ (blue) contigs. b: Length distribution of the newly characterized 5’- (red) and 3’- (blue) UTRs. c: Distribution of assembly variants in the database. The graph indicates the proportion of contigs exhibiting the indicated number of variants. d: Correspondence between the GigaTON and the predicted geneset proteins. The GigaTON contigs were translated using TransDecoder (http://transdecoder.github.io/) and resulted in 41445 proteins. They were aligned with the Ensembl protein from the oyster genome. The relative length of the 16787 alignments displaying at least 95 % identity between sets was plotted. The vertical smear on the right reflects longer proteins in the GigaTON database. For example, the protein with coordinates (X = 100, Y = 50) has its full Ensembl sequence covering 50 % of its GigaTON counterpart