
Fig. 3.
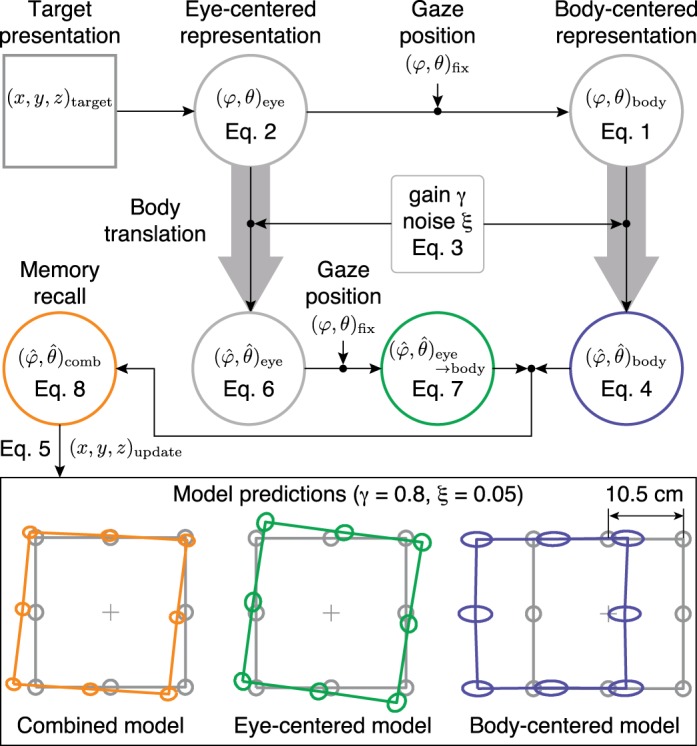
Schematic of the model. During target presentation, an estimate of the target location, represented by the center (mean) and shape (covariance) of the gray ellipses in the bottom panels, is stored in an eye-centered reference frame (φ, θ)eye (Eq. 2) and subsequently transformed into a body-centered reference frame (φ, θ)body, by taking eye position (φ, θ)fix into account (Eq. 1). Both representations are updated across body translation, where the perceived update is modeled with a gain parameter γ and noise parameter ξ (Eq. 3). The updated target estimate in eye-centered coordinates (Eq. 6) is then transformed into body coordinates (Eq. 7) and is optimally combined with the updated target estimate in body coordinates (Eq. 4). The combined map (Eq. 8) is used for target recall, from which the updated target location (x, y, z)update can be computed (Eq. 5). As an example, the orange ellipses show the updated target locations for γ = 0.8 and ξ = 0.05, as predicted by the combined model. The green and blue ellipses show the prediction when the model only uses the eye-centered or body-centered representation, respectively.