
Figure 9. Training and validation errors for hinge loss (one-versus-all) or softmax loss as learning proceeds.
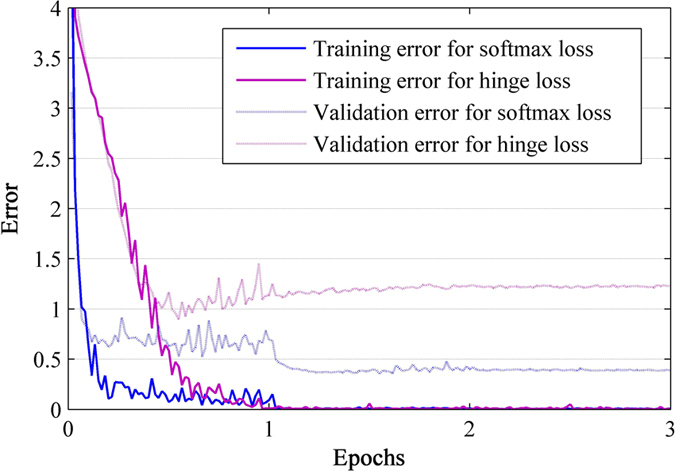
The errors were computed over 3 epochs, of which each has 20000 iterations. Both learning processes used the same local receptive fields and drop ratio. The two loss functions were associated with a large L2-norm weight decay constant 0.005 (larger than that used in AlexNet36), which has proved to be useful for improving generalization of neural networks55. Under these settings, softmax and hinge respectively achieved 0.932 and 0.891 in validation accuracy.