
Fig. 2.
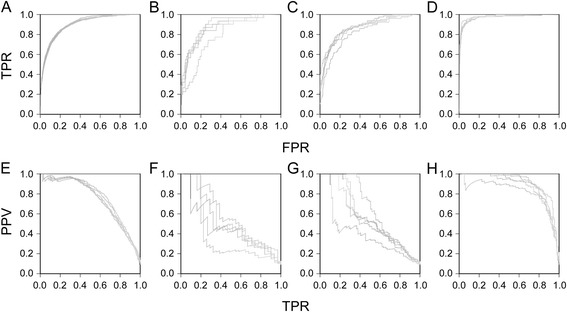
Assessment of classification capability of kmer-SVM trained GLIFLAG datasets containing sequences with at least one GBM. For all curves, each dataset is randomly split into 80 % for training and 20 % for prediction and the prediction is repeated five times (represented by individual lines). Plots assess the likelihood that the specified classifier can successfully predict sequences that have at least one GBM as positive or negative. a-d ROC plots depicting true positive rates (TPR) and false positive rates (FPR). Area under the curve (AUC) scores as calculated by kmer-SVM are: 0.89 for LDwGBM (a), 0.85 for CDwGBM (b), 0.86 for MBwGBM (c) and 0.97 for NPwGBM (d) datasets. e-h Precision recall curves depicting the positive predictive value (PPV), calculated as true positive / (true positive + false positive), versus the TPR. AUC of 0.75 for LDwGBM (e) and 0.88 for NPwGBM (h) indicate reasonable confidence in the classification while AUC of 0.49 for CDwGBM (f) and 0.55 for MBwGBM (g) indicate a low probability that the region is correctly labeled when the sequence is classified as positive