
Figure 3.
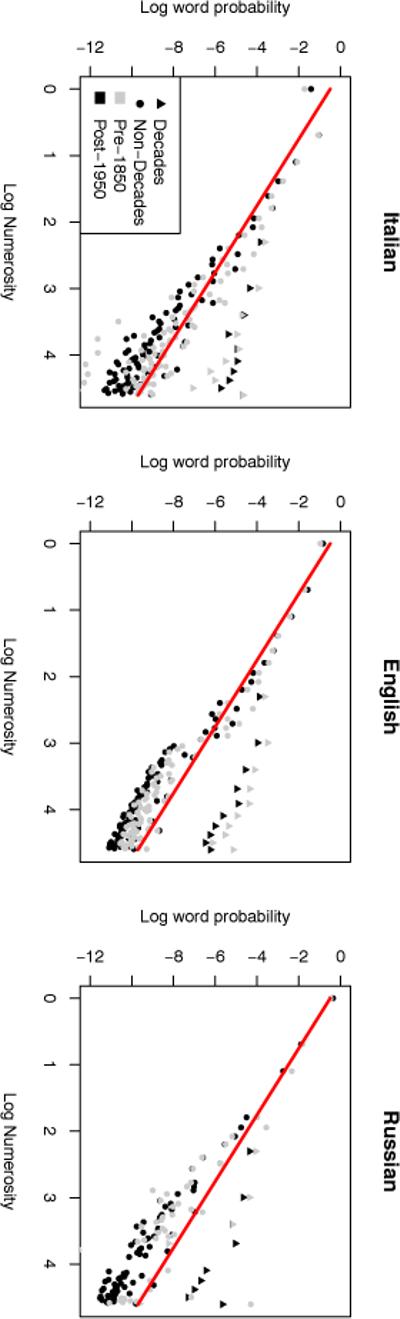
The distribution of number word frequencies across Italian, English, and Russian according to the Google Books N-gram dataset (Li et al. 2012). This reveals a strong power-law distribution across time, language, and for both decades (“ten”, “twenty”, etc.) and non-decades. On these plots, the linear trend of the data corresponds to the exponent in the power law distribution. The red line shows a power-law distribution with α = 2.