
Fig. 1.
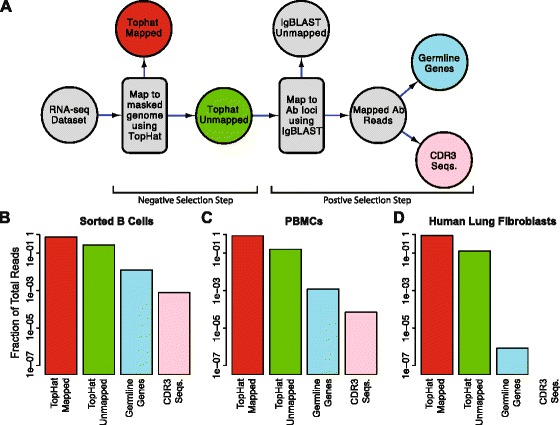
Bioinformatic pipeline. a Flow diagram of the steps in our bioinformatic pipeline for harvesting Ab reads from a RNA-seq dataset. The pipeline consists of a negative selection step using TopHat2 [47] where non-Ab reads are mapped to a masked reference genome, followed by a positive selection step using IgBLAST [48] where Ab reads are mapped to reference germline Ab sequences. b-d Fraction of reads retrieved for certain steps in the pipeline, in three different tissues, out of the number of TopHat mapped reads (red). The colors of the bars correspond to the colors of the steps in (a). b Sorted B cells from peripheral blood. c Peripheral blood mononuclear cells. d Human lung fibroblasts from tissue culture